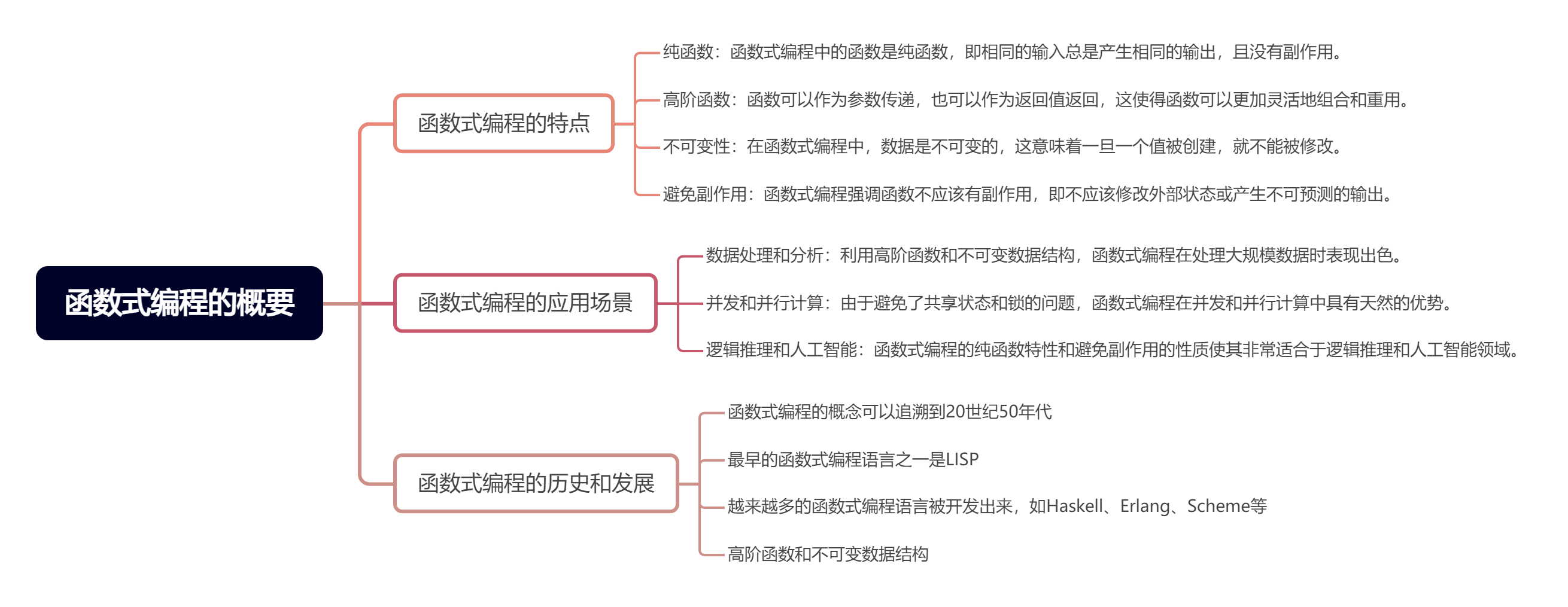
函数式编程(Functional Programming, FP)是一种编程范式,它将计算机程序视为数学函数的计算,强调程序由一系列函数组成,并通过函数调用和组合来解决问题。这种编程范式避免了状态和可变数据的使用,强调函数的不变性、纯函数(即输入相同则输出相同,且没有副作用)以及通过高阶函数(接受或返回其他函数的函数)来处理数据。
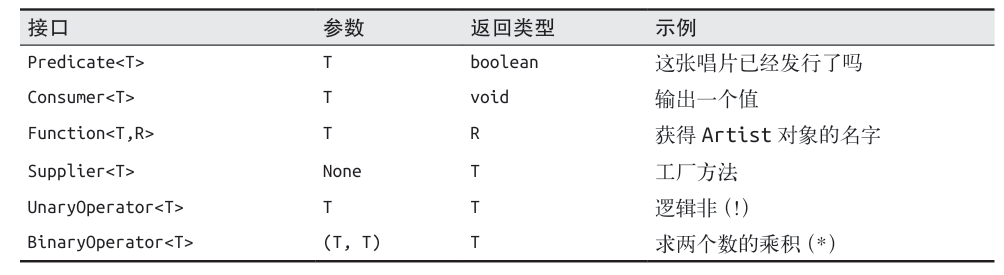
函数式编程的特点 纯函数:函数式编程中的函数是纯函数,即相同的输入总是产生相同的输出,且没有副作用。 高阶函数:函数可以作为参数传递,也可以作为返回值返回,这使得函数可以更加灵活地组合和重用。 不可变性:在函数式编程中,数据是不可变的,这意味着一旦一个值被创建,就不能被修改。 避免副作用:函数式编程强调函数不应该有副作用,即不应该修改外部状态或产生不可预测的输出。 函数式编程的历史和发展 函数式编程的概念可以追溯到20世纪50年代,最早的函数式编程语言之一是LISP,它基于λ演算(lambda calculus)的理论。随着计算机科学的发展,越来越多的函数式编程语言被开发出来,如Haskell、Erlang、Scheme等。这些语言强调代码的简洁性和可读性,以及通过高阶函数和不可变数据结构来实现并发和并行计算。
函数式编程的应用场景 数据处理和分析:利用高阶函数和不可变数据结构,函数式编程在处理大规模数据时表现出色。 并发和并行计算:由于避免了共享状态和锁的问题,函数式编程在并发和并行计算中具有天然的优势。 逻辑推理和人工智能:函数式编程的纯函数特性和避免副作用的性质使其非常适合于逻辑推理和人工智能领域。
体验Lambda表达式
函数式编程技巧都能给编程带来便利,人们津津乐道的话题之一是使用新的 Stream API 操作对象和集合类时(比如从所有的学生列表中过滤出在出生地在北京的学生时),代码是多么易读。如果你对 Lambda 表达式感兴趣,想知道它怎么帮助你提升专业技能,那么这个教程就是为你而写的。 1996 年 1 月,Java 1.0 发布,此后计算机编程领域发生了翻天覆地的变化。商业发展需要更复杂的应用,大多数程序都跑在功能强大的多核CPU的机器上。每个人对函数式编程的理解不尽相同。但其核心是:在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另一个值。 Java 8 的最大变化是引入了 Lambda 表达式——一种紧凑的、传递行为的方式。它也是本教程所述内容的基础,因此,接下来就了解一下什么是 Lambda 表达式。 第一个Lambda表达式
button.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
System.out.println("button clicked");
}
});这段代码中,我们创建了一个匿名类,它实现了ActionListener接口,这个接口中只有一个方法actionPerformed, 表达的含义是:当用户点击一个按钮时,button就会调用这个方法。表明按钮被点击了。设计匿名内部类的目的,就是为了方便Java程序员将代码作为数据传递。不过,匿名内部 类还是不够简便。为了调用一行重要的逻辑代码,不得不加上4行冗繁的样板代码。在Java 8中,上述代码可以写成一个 Lambda 表达式。
button.addActionListener(event -> System.out.println("button clicked"));上面这两段代码实现的效果是一样的,Lambda表达式只是创建了一个没有名字的函数,其中event是参数名(可以随便定义,只要符合java规范),-> 符号将参数与Lambda表达式的主体分开。仔细观察还会发现其中的参数没有显示的声明参数类型ActionEvent event,而在Lambda表达式中无需指定类型,程序依然可以 编译。这是因为javac根据程序的上下文(addActionListener方法的签名)在后台推断出 了参数event的类型。这意味着如果参数类型不言而明,则无需显式指定。程序员可省略 Lambda 表达式中的所有参数类型。再强调一次,这并不是魔法,javac 根据 Lambda 表达式上下文信息就能推断出参数的正确类型。程序依然要经过类型检查来保证运行的安全性,但不用再显式声明类型罢了。这就是所谓的类型推断。
Lambda表达式的多种形式
1)、Runnable run1 = () -> System.out.println("Hello World");
2)、ActionListener listener1 = event -> System.out.println("button clicked");
3)、Runnable run2 = () -> {
System.out.print("Hello");
System.out.println(" World");
};
4)、BinaryOperator<Long> add1 = (x, y) -> x + y;
5)、BinaryOperator<Long> add2 = (Long x, Long y) -> x + y; 1)、中所示的Lambda表达式不包含参数,使用空括号()表示没有参数。该Lambda表达式实现了Runnable接口,该接口也只有一个run方法,没有参数,且返回类型为void。 2)、中所示的Lambda表达式包含且只包含一个参数,可省略参数的括号 3)、Lambda 表达式的主体不仅可以是一个表达式,而且也可以是一段代码块,使用大括号({})将代码块括起来。该代码块和普通方法规则一样,可以用返回或抛出异常来退出。只有一行代码的Lambda表达式也可使用大括号,用以明确Lambda表达式从何处开始、到哪里结束。 4)、Lambda 表达式也可以表示包含多个参数的方法。这行代码并不是将两个数字相加,而是创建了一个函数,用来计算两个数字相加的结果。 5)、Lambda表达式中的参数类型都是由编译器推断得出的。但有时最好也可以显式声明参数类型,此时就需要使用小括号将参数括起来,多个参数的也是如此。
函数接口
函数接口是只有一个抽象方法的接口,用作Lambda表达式的类型
使用图形来表示不同类型的函数接口。指向函数接口的箭头表示参数,如果箭头 从函数接口射出,则表示方法的返回类型。ActionListener的函数接口如图
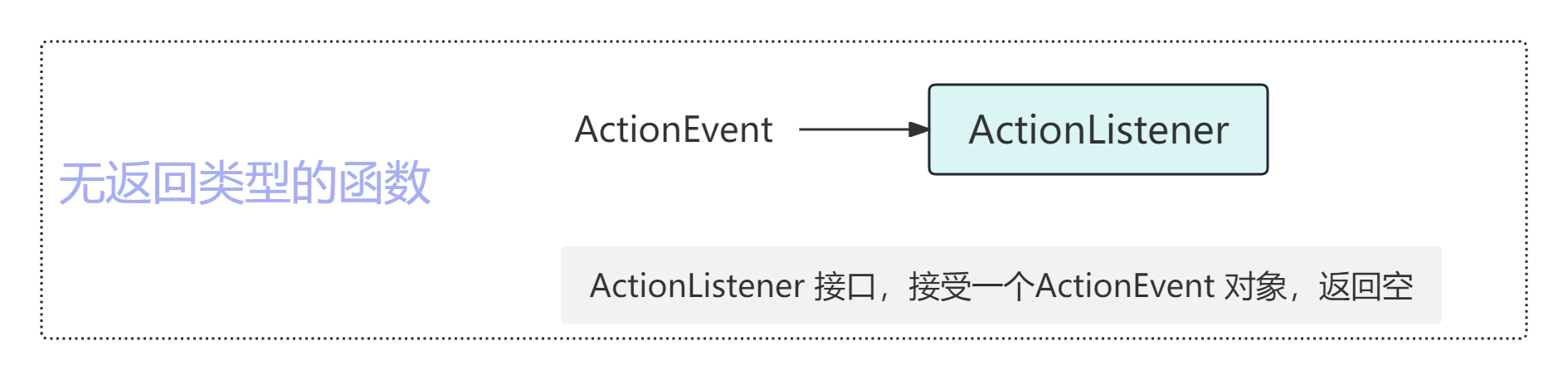
使用Java编程,总会遇到很多函数接口,但Java开发工具包(JDK)提供的一组核心函数 接口会频繁出现。
类型推断
某些情况下,用户需要手动指明类型。有时省略类型信息可以减少干扰,更易弄清状况;而有时却需要类型信 息帮助理解代码。经验证发现,一开始类型信息是有用的,但随后可以只在真正需要时才 加上类型信息。Lambda 表达式中的类型推断,实际上是Java 7就引入的目标类型推断的扩展。你可能已经知道Java 7中的菱形操作符,它可使javac推断出泛型参数的类型。如下代码示例
1)、Map<String, Integer> map1 = new HashMap<String, Integer>();
2)、Map<String, Integer> map2 = new HashMap<>(); 为变量map1明确指定了泛型的类型,而变量map2则使用了 菱形操作符。不用明确声明泛型类型,编译器就可以自己推断出来,这就是它的神奇之处! 当然,这并不是什么魔法,根据变量map2的类型可以推断出HashMap的泛 型类型,但用户仍需要声明变量的泛型类型。 Java 7 中程序员可省略构造函数的泛型类型,Java 8更进一步,程序员可省略Lambda表达 式中的所有参数类型。这是javac根据Lambda表达式上下文信息 就能推断出参数的正确类型。程序依然要经过类型检查来保证运行的安全性,但不用再显 式声明类型罢了。这就是所谓的类型推断。
Predicate<Integer> atLeast5 = x -> x > 5;
看一下它的源码
public interface Predicate<T> {
boolean test(T t);
}从上面Predicate只有一个泛型类型的参数,Integer用于其中。Lambda 表达式实现了Predicate接口,因此它的单一参数被推断为Integer类型。javac还可检查 Lambda 表达式的返回值是不是boolean,这正是Predicate方法的返回类型。
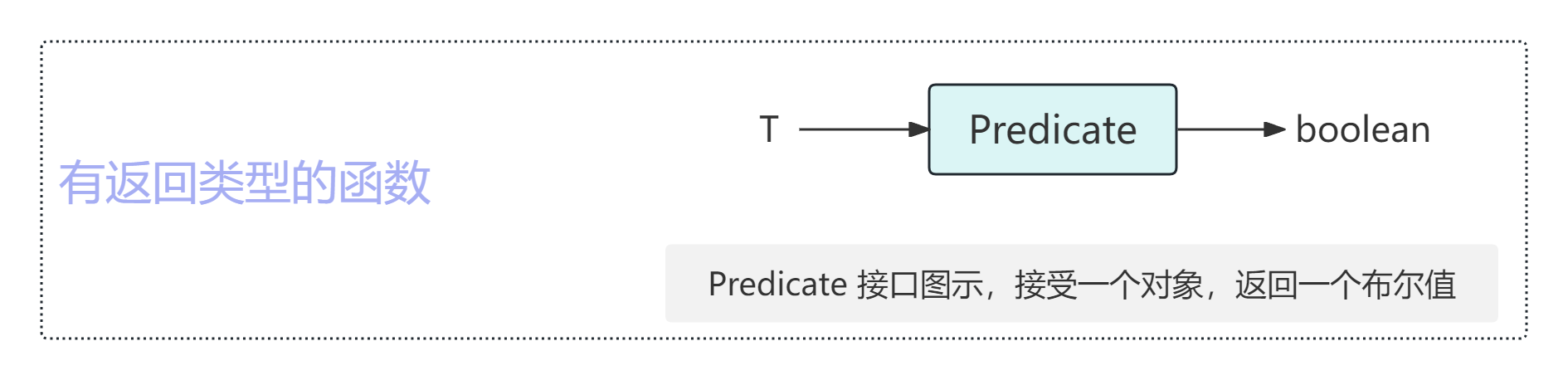
来一个稍微复杂点的函数接口:BinaryOperator。该接口接受两个参数,返回一个 Lambda表达式 | 11 值,参数和值的类型均相同。实例中所用的类型是Long
BinaryOperator<Long> addLongs = (x, y) -> x + y类型推断系统相当智能,但若信息不够,类型推断系统也无能为力。类型系统不会漫无边 际地瞎猜,而会中止操作并报告编译错误寻求帮助。如果我们删掉其中的某些类型信息(泛型)
BinaryOperator add = (x, y) -> x + y
编译器会提示错误:
Operator '& #x002B;' cannot be applied to java.lang.Object, java.lang.Object.上面这个错误,会让人一时看不懂。BinaryOperator毕竟是一个具有泛型参数的函数 接口,该类型既是参数x和y的类型,也是返回值的类型。上面的例子中并没有给出变量 add 的任何泛型信息,给出的正是原始类型的定义。因此,编译器认为参数和返回值都是 java.lang.Object 实例。
从外部迭代到内部迭代
平时常用的for循环代码
List<String> list = new ArrayList<>();
int countI =0;
for(String str:list){
if(str.startsWith("a")){
countI++;
}
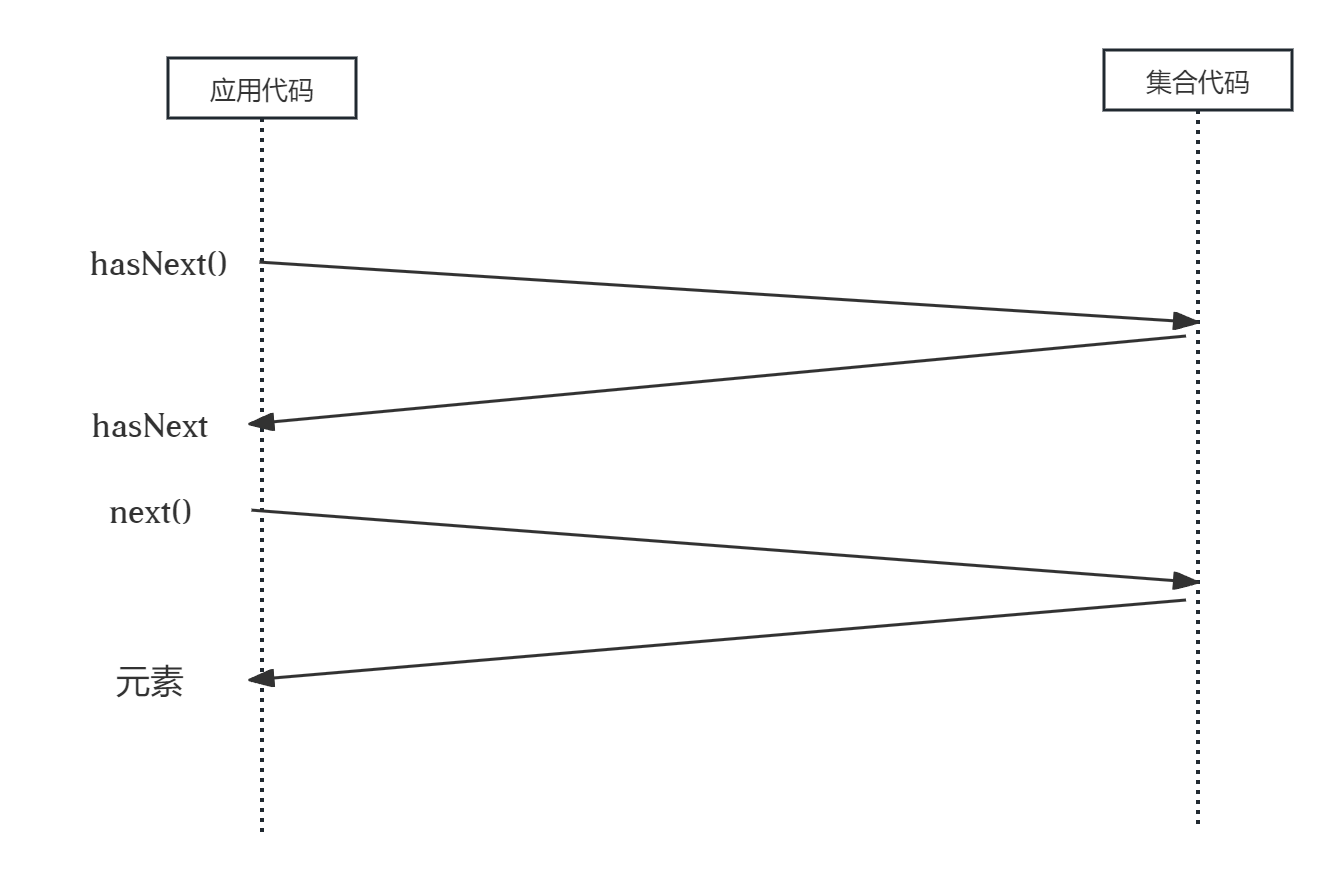
}若是单一的for循环,倒也问题不大,但面对一个满 是循环(尤其是嵌套循环)的庞大代码库时,负担就重了。就其背后的原理来看,for循环其实是一个封装了迭代的语法糖,我们在这里多花点时间, 看看它的工作原理。首先调用iterator方法,产生一个新的Iterator对象,进而控制整 个迭代过程,这就是外部迭代。
int countI =0;
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
String str = iterator.next();
if(str.startsWith("a")){
countI++;
}
}
然而,外部迭代也有问题。首先,它很难抽象出本章稍后提及的不同操作;此外,它从本 质上来讲是一种串行化操作。总体来看,使用for循环会将行为和方法混为一谈。另一种方法就是内部迭代,首先要注意stream()方法的调用,它和调用iterator()的作用一样。该方法不是返回一个控制迭代的Iterator对象,而是返 回内部迭代中的相应接口:Stream。Stream 是用函数式编程方式在集合类上进行复杂操作的工具
long countL = list.stream()
.filter(str->str.startsWith("a"))
.count();
map函数的使用
map函数可以将一种类型的值转换成另外一种类型,map操作可以将一个流中的值转换成一个新的流。
比如把集合中的所有元素转为大写
List<String> list2 = new ArrayList<>();
for (String str : list) {
String uppercaseStr = str.toUpperCase();
list2.add(uppercaseStr);
}map操作
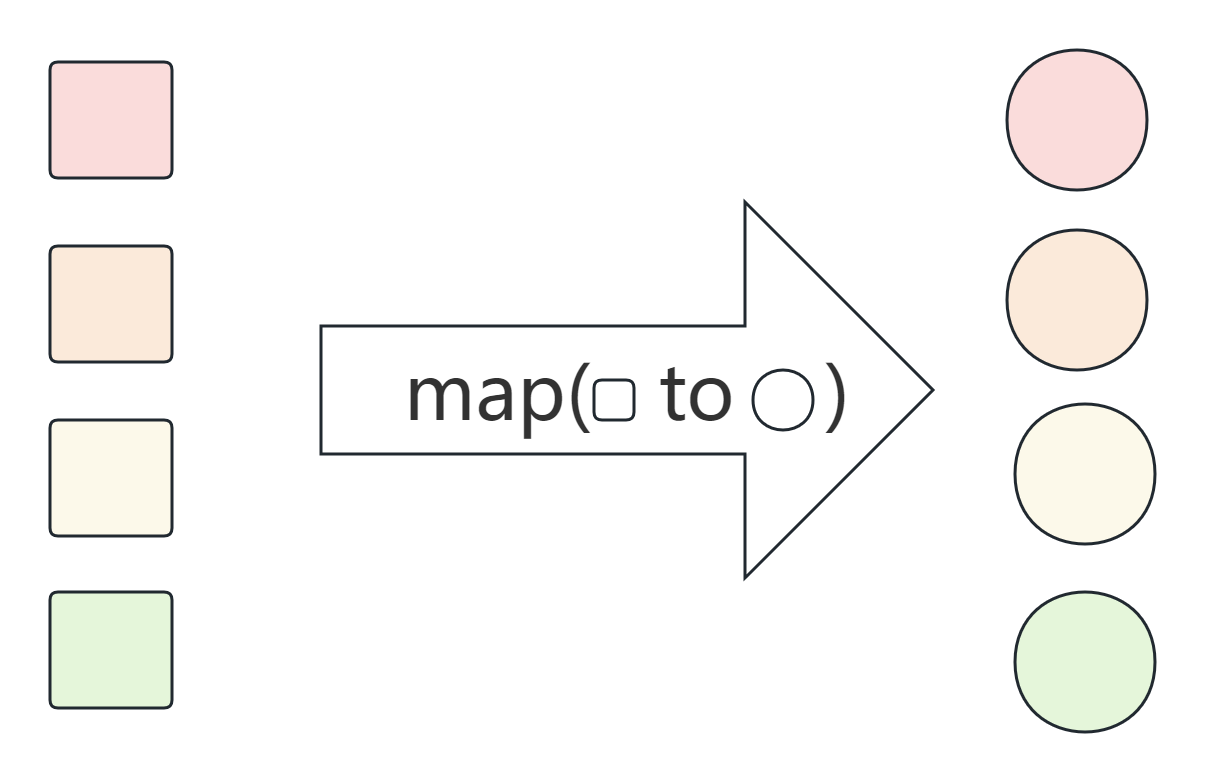
使用map操作将字符串转换为大写
List<String> list2 = list.stream().map(str->str.toLowerCase()).collect(Collectors.toList());filter 函数的操作
遍历数据并检查其中的元素时,可尝试使用Stream中提供的新方法filter

我们一起来看看这个filter有什么用。假设要找出一组字符串 中以字母a开头的字符串,比如字符串"a1"和"b1",其中"a1"就是符合条件的字符串。 可以使用一个for循环,内部用if条件语句判断字符串的第一个字符来解决这个问题
int countI = 0;
for (String str : list) {
if (str.startsWith("a")) {
countI++;
}
}使用filter的方式进行改写
long countI = list.stream().filter(str->str.startsWith("a")).count();这看起来和map很像,filter接受一个函数作为参数,该函数用Lambda表达式表示。
咱们回顾一下要点
• Lambda 表达式是一个匿名方法,将行为像数据一样进行传递。
• Lambda 表达式的常见结构:BinaryOperator<Integer> add = (x, y) → x + y。
• 函数接口指仅具有单个抽象方法的接口,用来表示 Lambda 表达式的类型。
以上截图内容来自ProcessOn 。如果你想要将自己的知识结构化记录下来,ProcessOn 是你的绝佳选择,提供多种专业图形的绘制工具和丰富的模板内容,支持工作、学习和生活各个方面的应用。
















 树形图
树形图  括号图
括号图  思维笔记
思维笔记