函数式编程的历史和发展 函数式编程的概念可以追溯到20世纪50年代,最早的函数式编程语言之一是LISP,它基于λ演算(lambda calculus)的理论。随着计算机科学的发展,越来越多的函数式编程语言被开发出来,如Haskell、Erlang、Scheme等。这些语言强调代码的简洁性和可读性,以及通过高阶函数和不可变数据结构来实现并发和并行计算。
承接上一章的内容:java函数式编程--入门基础知识社区ProcessOn思维导图流程图
max和min
求最大值和最小值常用的操作--max、min。StreamAPI中的max和min足以解决这个问题。比如我们要找最小的数字。首先要考虑用什么作为排序的指标。为了排序需要给它传一个Comparator对象,java8中提供了一个新的静态方法comparing,使用她可以比较方便的实现一个比较器。
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(0);
Integer min = list.stream().min(Comparator.comparing(item->item)).get();reduce操作
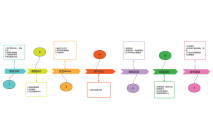
它可以实现从一组值中生成一个值。下图展示如何通过reduce操作对stream中的数字求和。
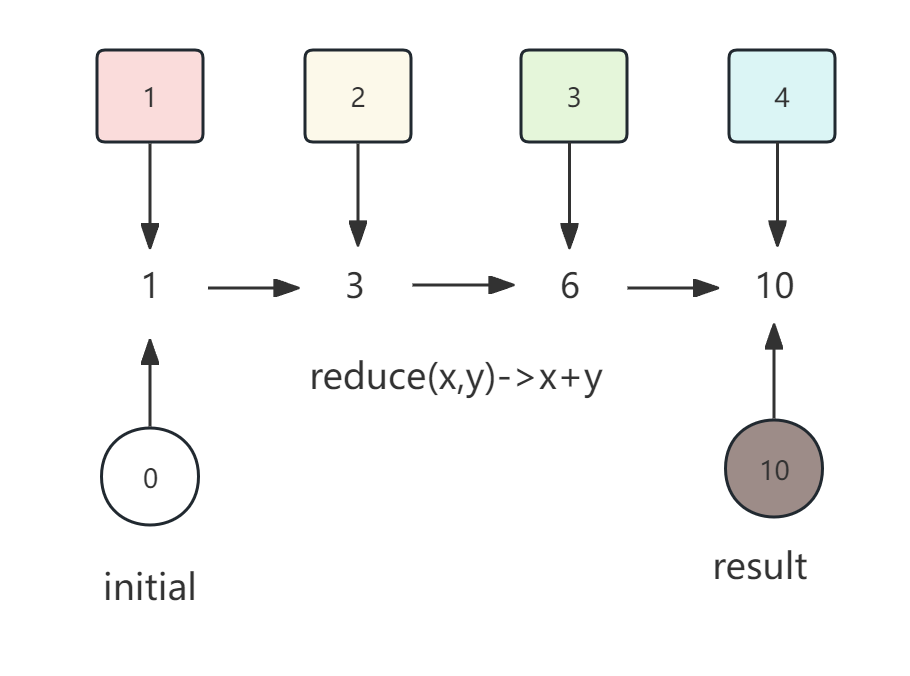
展开reduce的操作
BinaryOperator<Integer> accumulator = (x,y)->x+y;
int count = accumulator.apply(
accumulator.apply(
accumulator.apply(
accumulator.apply(0, 1),
2),
3),
4);合并后的操作
int count = Stream.of(1,2,3,4).reduce(0, Integer::sum);使用命令编程求和编码
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
int count = 0;
for(Integer element:list){
count=count+element;
}常用的类库
如何使用 Lambda 表达式。即使不需要编写像 Stream 这样重度使用函数式编程风格的类库,学会如 何使用 Lambda 表达式也是非常重要的。Java 8 中的另一个变化是引入了默认方法和接口的静态方法。在 Java 中,有一些相伴的类型,比如 int 和 Integer—— 前者是基本类型,后者是装箱类型。基本类型内建在语言和运行环境中,是基本的程序构 建模块;而装箱类型属于普通的 Java 类,只不过是对基本类型的一种封装。由于装箱类型是对象,因此在内存中存在额外开销。比如,整型在内存中占用 4 字节,整型对象却要占用 16 字节。将基本类型转换为装箱类型,称为装箱,反之则称为拆箱,两者都需要额外的计算开销。为了减小这些性能开销,Stream 类的某些方法对基本类型和装箱类型做了区分。在 Java 8 中,仅对整型、 长整型和双浮点型做了特殊处理,因为它们在数值计算中用得最多,特殊处理后的系统性 能提升效果最明显。

对基本类型做特殊处理的方法在命名上有明确的规范。如果方法返回类型为基本类型,则 在基本类型前加 To,如果参数是基本类型,则不加前缀只 需类型名即可。如果高阶函数使用基本类型,则在操作后加 后缀 To 再加基本类型,如 mapToLong

基本类型都有与之对应的 Stream,以基本类型名为前缀,如 LongStream。事实上, mapToLong 方法返回的不是一个一般的 Stream,而是一个特殊处理的 Stream。在这个特 殊的 Stream 中,map 方法的实现方式也不同,它接受一个 LongUnaryOperator 函数,将 一个长整型值映射成另一个长整型值。通过一些高阶函数装箱方法,如 mapToObj,也可以从一个基本类型的 Stream 得到一个装箱后的 Stream,如 Stream。

如何用这些方法,代码如下:
List<String> list = new ArrayList<>();
list.add("黑神话:悟空");
list.add("西游记");
list.add("黑悟空");
list.add("红楼梦");
list.add("三国演义");
list.add("水浒传");
list.add("哪吒闹海");
IntSummaryStatistics statistics = list.stream().mapToInt(String::length).summaryStatistics();
System.out.println(statistics.getMax());
System.out.println(statistics.getMin());
System.out.println(statistics.getAverage());
System.out.println(statistics.getSum());向控制台输出一系列统计信息。无需手动计算这些信息,这里使用对基 本类型进行特殊处理的方法 mapToInt,将每作品名映射为名字长度。因为该方法返回一个 IntStream 对象,它包含一个 summaryStatistics 方法,这个方法能计算出各种各样的统计 值,如 IntStream 对象内所有元素中的最小值、最大值、平均值以及数值总和。 这些统计值在所有特殊处理的 Stream,如 DoubleStream、LongStream 中都可以得出。如无 需全部的统计值,也可分别调用 min、max、average 或 sum 方法获得单个的统计值,同样, 三种基本类型对应的特殊 Stream 也都包含这些方法
重载解析
在 Java 中可以重载方法,造成多个方法有相同的方法名,但签名确不一样。这在推断参数 类型时会带来问题,因为系统可能会推断出多种类型。这时,javac 会挑出最具体的类型。Lambda 表达式的类型就是对应的函数接口类型,因此,将 Lambda 表达式作为参数 传递时,情况也依然如此。操作时可以重载一个方法,分别接受 BinaryOperator 和该 接口的一个子类作为参数。调用这些方法时,Java 推导出的 Lambda 表达式的类型正 是最具体的函数接口的类型。如下两个方法中选择时,输出的是 IntegerBinaryOperator。
private void overFn(Object o){
System.out.println("Obj");
}
private void overFn(String o){
System.out.println("String");
}
private interface IntegerBiFunction extends BinaryOperator<Integer>{}
private void overFun(BinaryOperator<Integer> lambda){
System.out.println("BinaryOperator");
}
private void overFun(IntegerBiFunction lambda){
System.out.println("IntegerBiFunction");
}数据分块
一个常用的流操作是将其分解成两个集合。比如希望按名字长度将作品分为两部分,一部分是名字长度小于4的,另一部分是大于等于4的。对于这个需求,可以使用两次过滤操作,分别过滤出以上两种分类的作品。但是问题来了,首先为了执行两次过滤操作,需要有两个流。其次,如果过 滤操作复杂,每个流上都要执行这样的操作,代码也会变得冗余。幸好我们有这样一个收集器 partitioningBy,它接受一个流,并将其分成两部分。它使用 Predicate 对象判断一个元素应该属于哪个部分,并根据布尔值返回一 个 Map 到列表。因此,对于 true List 中的元素,Predicate 返回 true;对其他 List 中的 元素,Predicate 返回 false。

使用它,我们就可以将作品按照名字长度进行分开了。本利中,分块函数指明超过长度为4的是一块,其他的是另外一块。
List<String> list = new ArrayList<>();
list.add("黑神话:悟空");
list.add("西游记");
list.add("红楼梦");
list.add("三国演义");
list.add("水浒传");
list.add("哪吒闹海");
Map<Boolean,List<String>> map1 = list.stream().collect(Collectors.partitioningBy(ele->ele.length()>3));
System.out.println(map1);
输出结果:
{false=[西游记, 红楼梦, 水浒传], true=[黑神话:悟空, 三国演义, 哪吒闹海]}数据分组
数据分组是一种更自然的分割数据操作,与将数据分成 ture 和 false 两部分不同,可以使 用任意值对数据分组。比如现在有一堆作品名,可以按照作品名的长度进行分组。
List<String> list = new ArrayList<>();
list.add("黑神话:悟空");
list.add("西游记");
list.add("红楼梦");
list.add("三国演义");
list.add("水浒传");
list.add("哪吒闹海");
Map<Integer,List<String>> map1 = list.stream().collect(Collectors.groupingBy(String::length));
System.out.println(map1);
输出结果:
{3=[西游记, 红楼梦, 水浒传], 4=[三国演义, 哪吒闹海], 6=[黑神话:悟空]}和其他例子一样,调用流的 collect 方法,传入一个收集器。groupingBy 收集器接受一个分类函数,用来对数据分组,就像 partitioningBy 一样,接受一个 Predicate 对象将数据分成 ture 和 false 两部分。我们使用的分类器是一个 Function 对 象,和 map 操作用到的一样。
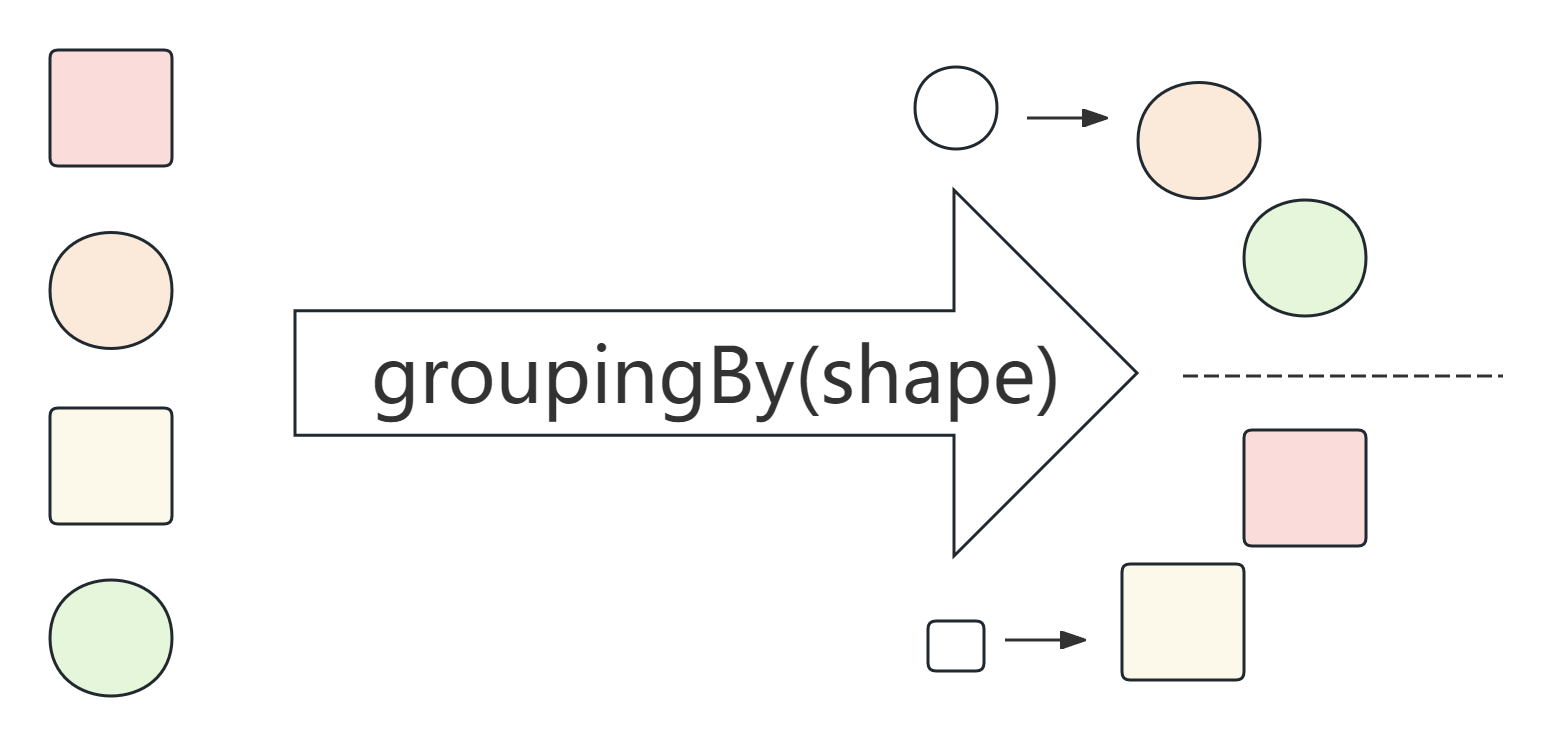
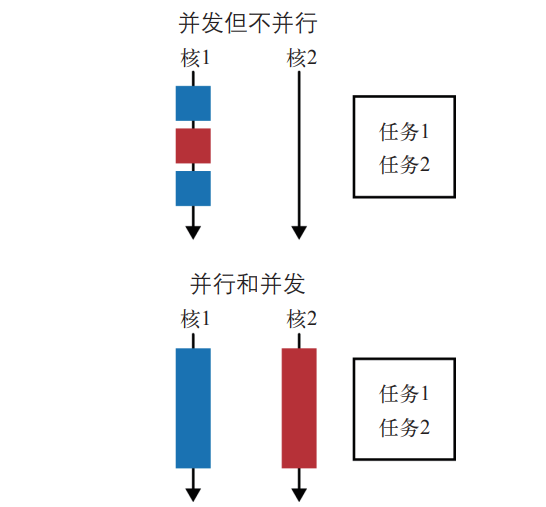
并行和并发
并发 和并行是两个不同的概念,它们的作用也不一样。并发:并发是指在宏观上多个程序或任务在一段时间内同时执行的现象,而在微观上这些程序交替执行。并发通过快速切换CPU上下文,使得每个进程执行一会就停下来,切换到下一个被调度到的进程上,这种切换速度非常快,人无法感知到,从而产生了多个任务同时运行的错觉。并行:并行是指多个任务在同一时刻同时执行,通常需要多个处理器或处理器核心。并行性主要用于提升计算性能,缩短任务执行时间。
并行求和的代码
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
int sum = list.parallelStream().mapToInt(i->i).sum();
System.out.println(sum);在底层,并行流还是沿用了 fork/join 框架。fork 递归式地分解问题,然后每段并行执行, 最终由 join 合并结果,返回最后的值。
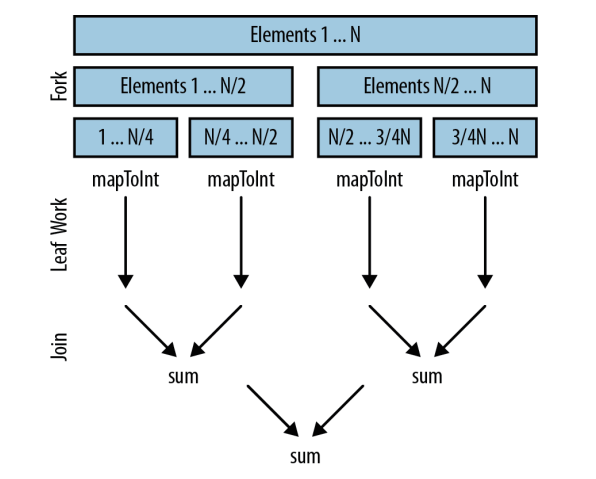
假设并行流将我们的工作分解开,在一个四核的机器上并行执行。 数据被分成四块;计算工作在每个线程里并行执行。这包括将每个 Integer 对象映射为 int 值,然后在每个线程里将 1/4 的数字相加。理想情况下,我们希望在这里花的时间越多越好,因为这里是并行操作的最佳场所;然后合并结果。就是 sum 操作,但这也可能是 reduce、collect 或其他终 结操作。
以上截图内容来自ProcessOn 。如果你想要将自己的知识结构化记录下来,ProcessOn是你的绝佳选择,提供多种专业图形的绘制工具和丰富的模板内容,支持工作、学习和生活各个方面的应用。

















 树形图
树形图  括号图
括号图  思维笔记
思维笔记