MySQL知识星球
2020-07-13 15:52:54 1 举报AI智能生成
MySQL知识汇总
作者其他创作
大纲/内容
1.MySQL介绍和安装
一. MySQL版本选择
1. MySQL5.6以后的版本,推荐使用官方版本。
2. Percona:
在5.6版本以后,MySQL将Percona之前优化集成到官方版本中;
3. MariaDB:
无INNODB;且核心代码较老
4. MySQL在5.6以后不断重构源码,安装包越来越大,功能和性能在持续改进
二. MySQL官方网站介绍
1. Developer Zone: MySQL开发工程师板块
Articles: Oracle工程师自己的博客
Plant MySQL: 和MySQL相关从业人员的博客
Bugs:
MySQL BugList
Worklog:开发记录
Labs:MySQL实验性项目
2. Downloads:
MySQL下载
Enterprise:MySQL企业版本相关,略过
Community:社区版,我们下载和使用社区版
MySQL Community Server:MySQL Server
MySQL Fabric : 和管理相关的工具
MySQL Router:路由中间件
MySQL Utilities:MySQL应用程序包
MySQL Workbench:官方图型化管理界面
MySQL Proxy:MySQL代理,Alpha版本,不推荐
3. Documentation:MySQL文档
官方文档 版面更改,下载离线文档在左侧Menu的下面
[PDF A4](http://downloads.mysql.com/docs/refman-5.7-en.a4.pdf)
[EPUB](http://downloads.mysql.com/docs/refman-5.7-en.epub)
[HTML](http://downloads.mysql.com/docs/refman-5.7-en.html-chapter.zip)
三. MySQL下载
1. 推荐下载`Linux-Generic`版本
2. `Source Code`版本主要作用是为了让开发人员研究源码使用,自己编译对性能提升不明显
3. 不推荐`Version 5.5.X`,有部分bug
4. 推荐使用`Version 5.6.X`和`Version 5.7.X`
5. 下载地址:
[MySQL Community Server 5.7.18 Linux Generic x86-64bit](https://downloads.mysql.com/archives/get/file/mysql-5.7.18-linux-glibc2.5-x86_64.tar.gz)
[MySQL Community Server 5.6.27 Linux Generic x86-64bit](http://dev.mysql.com/get/Downloads/MySQL-5.6/mysql-5.6.27-linux-glibc2.5-x86_64.tar.gz)
四. MySQL安装
1. 安装通用步骤:
解压缩`mysql-VERSION-linux-glibc2.5-x86_64.tar.gz`
打开`INSTALL_BINARY` 文件,按照`shell>`开头的步骤进行操作
将`export PATH=/安装路径/mysql/bin:$PATH`添加到`/etc/profile`
`chkconfig mysqld on`或者`chkconfig mysqld.server on`因你的环境而定。
2. MySQL 5.6.X 安装:
3. MySQL 5.7.X 安装:
4. 验证安装
`data`目录在安装之前是`空目录`,安装完成后应该有`ibXXX`等文件
安装过程中输出的信息中,不应该含有`ERROR`信息,错误信息`默认`会写入到`$HOSTNAME.err`的文件中
通过`bin/mysql`命令(*5.7.X含有临时密码*)可以正常登录
5. MySQL启动
`mysqld_safe --user=mysql &` 即可启动,`mysqld_safe`是一个守护`mysqld`进程的脚本程序,旨在`mysqld`意外停止时,可以重启`mysqld`进程
也可以通过`INSTALL_BINARRY`中的的步骤,使用`/etc/init.d/mysql.server start`进行启动(启动脚本以你复制的实际名字为准,通常改名为`mysqld`,即`/etc/init.d/mysqld start`)
五. 配置文件和脚本
1. 配置文件`my.cnf`
2. 几个重要的参数配置和说明
`innodb_log_file_size = 4G` :做实验可以更改的小点,线上环境推荐用4G,以前5.5和5.1等版本之所以官方给的值很小,是因为太大后有bug,现在bug已经修复
`innodb_undo_logs = 128`和`innodb_undo_tablespaces = 3`建议在安装之前就确定好该值,后续修改比较麻烦
`[mysqld]`,`[mysqld-5.7]`这种tag表明了下面的配置在什么版本下才生效,`[mysqld]`下均生效
`datadir`, `innodb_log_group_home_dir`, `innodb_undo_directory`一定要注意他的权限是 `mysql:mysql`
3. `my.cnf`问题
使用`mysqld --help -vv | grep my.cnf`查看mysql的配置文件读取顺序
后读取的`my.cnf`中的配置,如果有相同项,会覆盖之前的配置
使用`--defaults-files`可指定配置文
4. 安装脚本 `installation_of_single_mysql.sh`
注意:脚本、my.cnf文件和mysql-5.7.18-linux-glibc2.5-x86_64.tar.gz放在同一目录下
六.数据库升级
1. 环境说明:
2. 环境举例:
MySQL安装目录:
MySQL 5.6.27: /usr/local/mysql-5.6.27-linux-glibc2.5-x86_64
MySQL 5.7.18 : /usr/local/mysql-5.7.18-linux-glibc2.5-x86_64
datadir目录:
/dbdata/mysqdata/
*初始环境:*
3. 版本升级
4.关于降级问题的说明
七、多实例安装
1. 多实例介绍
一台服务器上安装多个MySQL数据库实例
可以充分利用服务器的硬件资源(注意io资源)
通过mysqld_multi进行管理
2. 配置文件要点
`[mysqld_multi]` 是否需要配置
`my.cnf`上直接配置`[mysqld1]`、`[mysqld2]`、`[mysqld3]` 实例标签,而`不配置[mysqld_multi]`,使用`mysqld_multi start 1`也是`可以启动`数据库实例的,但是没有`mysqld_safe`的守护进程。所以该标签`需要配置`
如果在`[client]`和`[mysqld_multi]`标签中同时存在`user`和`password`, 则在关闭数据库实例中会使用`[mysqld_multi]`中的`user`去关闭。
(`存在精确匹配的标签,则优先使用精确匹配标签下的配置项`)
multi_admin用户的作用multi_admin@localhost这个用户主要的作用是用来`关闭`数据库实例,因为文档中只授权了`SHUTDOWN`权限。
3. 环境说明
`mysqld1` -- MySQL 5.7.18
`mysqld2` -- MySQL 5.7.18
`mysqld3` -- MySQL 5.6.36
4. 配置说明
MySQL实例1
`mysqld1` (MySQL 5.7.18)
port = 33016
datadir = /dbdata/mysqldata/mysql_33016
socket = /dbdata/mysqldata/mysql_33016/mysql.sock
MySQL实例2
`mysqld2` (MySQL 5.7.18)
port = 33026
datadir = /dbdata/mysqldata/mysql_33026
socket = /dbdata/mysqldata/mysql_33026/mysql.sock
MySQL实例3
`mysqld3` (MySQL 5.6.36)
port = 33036
datadir = /dbdata/mysqldata/mysql_33036
注意MySQL5.6.36的`plugin_dir`的路径
配置说明:
1:配置的标签顺序没有关系,不会影响最终配置的有效性。
2:同类型标签中的配置项会合并,形成一个大的配置项
3:`匹配度高`的标签中的配置项的`值`,会`覆盖`掉`匹配度低`的标签中的配置项的`值`
这三个参数必须定制且必须不同 (port / datadir / socket)
配置文件
5. 安装多实例
启动数据库,并修改root账号,授权其他账号
检测port和socket
设置login-path
设置login-path主要为了能够简化登录,同时还可以让每个数据库的密码都不同,避免使用[client]下的统一用户名密码
八、Employees示例库安装
1. Employees数据库介绍
2. Employees的安装
2.1. 下载
[employees_db-full-1.0.6.tar.bz2](https://launchpad.net/test-db/employees-db-1/1.0.6/+download/employees_db-full-1.0.6.tar.bz2) 使用 `wget` 下载
[github-test_db](https://github.com/datacharmer/test_db) 使用`git clone` 进行仓库拉取
2.2. 解压和拉取
2.3. 导入employees库
2.4. 验证
2.MySQL访问连接和授权
一. Workbench与Utilities介绍
下载
[Workbench-win64下载](https://cdn.mysql.com//Downloads/MySQLGUITools/mysql-workbench-community-6.3.10-winx64.msi)
[Utilities下载](https://dev.mysql.com/get/Downloads/MySQLGUITools/mysql-utilities-1.6.5.tar.gz)
Workbench功能概述
SQL语句格式化 SQL关键字upcase MySQL Dashboard SQL语法提示 ER图 Forward Engine //ER图 --> DB表结构 Reverse //DB表结构 --> ER图
Utilities介绍和安装
MySQL Utilities介绍
MySQL Utilities 提供一组命令行工具用于维护和管理 MySQL 服务器,包括:
管理工具 (克隆、复制、比较、差异、导出、导入)
复制工具 (安装、配置)
一般工具 (磁盘使用情况、冗余索引、搜索元数据)> MySQL Utilities是一系列的命令行工具以及Python库更容易完成管理的任务。库是用Python语言写的,这就意味着不需要安装其他任何工具和库。当前是基于Python2.6版本设计的,不支持Python3.1版本.
MySQL Utilities提供了各种平台的软件包,如果没有找到对应自己平台的包,可以通过源码进行编译安装。
最新的MySQL Utilities可以在此处下载:http://dev.mysql.com/downloads/utilities/
MySQL Utilities依赖环境> MySQL Utilities需要Python2.6版本,所有的代码都是基于该版本编写的。同时,还需要连接驱动MySQL Connector/Python通用版本(高于1.0.8)。
MySQL Connector/Python下载地址:http://dev.mysql.com/downloads/connector/python/
MySQL Utilities源码安装
二. MySQL的连接登录
1. 几种登录方式
方式一 `mysql -p`
该方法默认使用root用户, 可使用`select user();`查看当前用户
方式二 `mysql -S /tmp/mysql.sock -u root -p` *密码A*
该方法适用于在安装MySQL主机上进行本地登录
方式三 `mysql -h 127.0.0.1 -u root -p` *密码B*
使用`'root'@'127.0.0.1'`这个用户登录
方式四 `mysql -h localhost -u root -p` *密码A*
该方式等价与【方式二】,且和【方式三】属于两个不同的“用户”
2. 免密码登录
方式一 `my.cnf`增加`[client]`标签
方式二 `login-path`
方式三 `~/.my.cnf`, 自己当前家目录
三. 权限管理
1.“用户 + IP”的概念
2. 用户权限管理
系统表权限信息:
a) 用户名和IP是否允许
b) 查看mysql.user表 `// 查看全局所有库的权限`
c) 查看mysql.db表 `// 查看指定库的权限`
d) 查看mysql.table_priv表 `// 查看指定表的权限`
e) 查看mysql.column_priv表 `// 查看指定列的权限`*tips: mysql> desc [tablename]; 可以查看表的结构信息;*
常用权限:
SQL语句:SELECT、INSERT、UPDATE、DELETE、INDEX
存储过程:CREATE ROUTINE、ALTER ROUTINE、EXECUTE、TRIGGER
管理权限:SUPER、RELOAD、SHOW DATABASE、SHUTDOWN、[所有权限猛戳这里](https://dev.mysql.com/doc/refman/5.7/en/privileges-provided.html)
可选资源:
MAX_QUERIES_PER_HOUR *count*
MAX_UPDATES_PER_HOUR *count*
MAX_CONNECTIONS_PER_HOUR *count*
MAX_USER_CONNECTIONS *count*`tips:`只能精确到小时,对于部分场景不适用,可以考虑中间件方式*
显示当前用户的权限
3. 基本操作
4. 撤销权限
`revoke` 关键字,该关键字只删除用户权限,不删除用户
`revoke` 语法同`grant`一致, 从`grant ... to` 变为`revoke ... from`
5.权限拾遗
GRANT与创建用户
查看某一个用户的权限
删除某一个用户
MySQL权限信息
6. MySQL模拟角色
角色的定义:
`角色(Role)`可以用来`批量管理用户`,同一个角色下的用户,拥有`相同的权限`。 MySQL5.7.X以后可以模拟`角色(Role)`的功能,通过`mysql.proxies_priv`模拟实现。
mysql.proxies_priv在`5.5.X和5.6.X`的时候就存在,但是`无法模拟角色(Role)`功能。
模拟角色操作:
四. MySQL 参数设置
全局参数:GLOBAL
可修改参数
不可修改参数
会话参数:SESSION
可修改参数
不可修改参数
2. 查看参数
3. 设置参数
设置全局(GLOBAL)参数
设置会话(SESSION)参数
注意
五.MySQL SSL
什么是SSL?
1. 开启SSL (5.7.18)
环境说明
开始测试
2. 开启证书认证(5.7.18)
3.MySQL数据库体系结构
一、 MySQL数据库体系结构
1.MySQL数据库体系结构介绍
*1.1 数据库*
数据库(数据库文件)是`一个或者一组`二进制文件,通常来说存在与文件系统之上。
*1.2 数据库实例*
由数据库`后台进程/线程`以及一个`共享内存区`组成
`共享内存`可以被运行的`后台进程/线程`所共享
数据库实例才是真正用来`操作数据库文件`的
注意:MySQL中,数据库实例和数据库是一一对应的。没有Oracle的一对多(RAC)的机制。
*1.3 MySQL体系结构*
单进程多线程结构
不会影响MySQL的性能,看程序如何写。(多进程程序,进程间通信开销大于多线程)
存储引擎的概念
可以理解成文件系统,例如FAT32, NTFS, EXT4。
一个表是一个分区,引擎就是分区的文件系统 `存储引擎`的对象就是`表`
show tables; 可以看到每个表对应的是上面引擎(Engine)
除了特殊情况,我们现在就只考虑`INNODB`
体系结构图
sql在各个模块的执行过程
*1.4 逻辑存储结构*
MySQL逻辑存储结构
instance
database
schema
table
view
一个DB对应一个schema
一个DB对应一个文件夹
一个表对应一组文件
*1.5 MySQL物理存储结构*
MySQL配置文件
datadir
存储数据二进制文件的路径
表结构的组成
frm:表结构定义文件 MYI:索引文件
MYD:数据文件 可以用hexdump -c XXX.frm查看二进制文件(意义不大)
show create table tablename;
mysqlfrm (utilities工具包)
错误日志文件
log_err 建议配置成统一的名字,方便定位错误
慢查询日志文件
将运行超过某一个时间阈值的SQL语句记录到文件
MySQL < 5.1 :以秒为单位
MySQL >= 5.1 : 以毫秒为单位
MySQL >= 5.5 : 可以将慢查询日志记录到表
MySQL >= 5.6 : 以更细的粒度记录慢查询
MySQL >= 5.7 : 增加timestamps支持
slow_query_log_file
建议配置成统一的名字,用于优化查询
通用日志作用
可以记录数据库所有相关操作
参数:general_log
默认文件名:机器名.log
同样可以将日志保存到表
mysql.general_log
开启性能下降明显
二、 MySQL主要文件
1.慢查询日志
1.1 慢查询日志相关参数:
`slow_query_log`
是否开启慢查询日志
`slow_query_log_file`
慢查询日志文件名, 在`my.cnf`我们已经定义为slow.log,默认是 *机器名-slow.log*
`long_query_time`
制定慢查询阈值, 单位是秒,且当版本 `>=5.5.X`,支持毫秒。例如`0.5`即为`500ms`
`大于`该值,不包括值本身。例如该值为2,则执行时间正好`等于`2的SQL语句`不会记录`
`log_queries_not_using_indexes`
将`没有使用索引`的SQL记录到慢查询日志
如果一开始因为数据少,查表快,耗时的SQL语句没被记录,当数据量大时,该SQL可能会执行很长时间
需要测试阶段就要发现问题,减小上线后出现问题的概率
`log_throttle_queries_not_using_indexes`
`限制每分钟内`,在慢查询日志中,去记录`没有使用索引的SQL语句的次数`;版本需要`>=5.6.X`
因为没有使用索引的SQL可能会短时间重复执行,为了避免日志快速增大,限制每分钟的记录次数
`min_examined_row_limit`
`扫描记录少于该值`的SQL不记录到慢查询日志
结合去记录没有使用索引的SQL语句的例子,有可能存在某一个表,数据量维持在百行左右,且没有建立索引。这种表即使不建立索引,查询也很快,扫描记录很小,如果确定有这种表,则可以通过此参数设置,将这个SQL不记录到慢查询日志。
`log_slow_admin_statements`
`记录超时的管理操作`SQL到慢查询日志,比如ALTER/ANALYZE TABLE
`log_output`
慢查询日志的格式,[FILE | TABLE | NONE],默认是FILE;版本`>=5.5`
如果设置为TABLE,则记录的到`mysql.slow_log`
`log_slow_slave_statements`
在从服务器上开启慢查询日志
`log_timestamps`
写入时区信息。可根据需求记录UTC时间或者服务器本地系统时间
1.2 慢查询日志测试
查看慢查询记录的相关参数
终端A
查看慢查询日志
终端B
进行模拟耗时操作
终端A
最终产生慢查询日志
终端B
注意
mysqldumpslow
慢查询日志存入表
2. 通用日志(generic_log)与审计
1.1 通用日志作用
当需要查找某条特定SQL语句,且该SQL语句执行较快,无法记录到slow_log中时,可以开启通用日志`generic_log`,进行全面记录, 可用于审计`Audit`
A终端设置开启关闭通用日志
B终端显示日志
通用日志会记录所有操作,性能下降明显。所以如果需要审计,需要`Audit Plugin`
1.2 审计插件
1.3 mcafee Audit Plugin安装
安装审计插件
测试插件
查看审计日志
以上仅为基本功能操作,详细的细粒度控制请参考[Mcafee文档](https://github.com/mcafee/mysql-audit/wiki)
4.MySQL存储引擎介绍
1.MySQL上支持的存储引擎
2.存储引擎的概念
用来处理数据库的相关`CRUD`操作
每个数据库都有存储引擎,只是MySQL比较强调存储引擎的概念。
3. MySQL存储引擎
官方存储引擎
MyISAM
`InnoDB` -- 推荐;其他引擎已经体停止维护和开发
Memory
Federated
CSV
Archive
第三方存储引擎
TokuDB -- 开源,适合插入密集型
InfoBright --商业,开源版本有数据量限制。属于列存储,面向OLAP场景
Spider
第三方存储引擎在特定场合下比较适合,除此之外,都应该使用InnoDB
3.存储引擎之MyISAM
3.1MyISAM特点
MySQL5.1版本之前的默认存储引擎
堆表数据结构
表锁设计
支持数据静态压缩
不支持事物
数据容易丢失
索引容易损坏
唯一优点
数据文件可以直接拷贝到另一台服务器使用
现在MySQL中还有用MyISAM的表,
主要是历史原因。数据库文件以`MY`开头的基本都是MyISAM的表
部分如User,DB等系统表(MyISAM引擎),可以直接拷贝,比较方便
性能好,或者存储小`不是`MyISAM的优点,也不是存在的原因
3.2 MyISAM文件组成
`frm` 表结构文件
`MYI` 索引文件
`MYD` 数据文件
数据文件是堆表数据结构,堆是无序数据的集合
`MYI`中的叶子节点,指向`MYD`中的数据页
当数据移动到页外时,需要修改对应指针
3.3 myisamchk
myisamchk 最好是关闭数据库,然后修复
不停机需要锁住表 `lock table sysbench.test_log_copy read` 再修复
4. Memory存储引擎
4.1 Memory介绍
全内存存储的引擎
数据库重启后数据丢失
支持哈希索引
不支持事物
4.2 Memory特性
`千万不要用Memory存储引擎去做缓存(Cache)`, 性能上不及Redis和Memcahced
Memory`不能禁用`,当涉及内部排序操作的临时表时,使用该存储引擎
`max_heap_table_size`决定使用内存的大小,默认时`16M`
无论该表使用的什么引擎,只要使用到临时表,或者指定Memory,都受参数影响
当上面设置的内存放不下数据时,(>=5.6)转为MyISAM,(>=5.7)转为InnoDB
注意磁盘上临时路径空间的大小(`tmpdir`)
内存使用为会话(SESSION)级别,当心内核OOM
支持哈希索引,且仅支持等值查询
4.3 Memory的物理特性
内存不会一次性分配最大空间,而是随着使用逐步增到到最大值
通过链表管理空闲空间
使用固定长度存储数据
不支持`BLOB`和`TEXT`类型
可以创建自增主键
5. CSV存储引擎
5.1 CSV介绍
CSV - Comma-Separated Values,使用逗号分隔
不支持特殊字符
CSV是一种标准文件格式
文件以纯文本形式存储表格数据
使用广泛
5.2 CSV文件组成
`frm` 表结构
`CSV` 数据文件
`CSM` 元数据信息
5.3 CSV特性
MySQL CSV存储引擎运行时,即创建CSV`文件`
通过MySQL标准接口来查看和修改CSV文件
无需将CSV文件导入到数据库,只需创建相同字段的表结构,拷贝CSV文件即可
CSV存储引擎表每个字段`必须是NOT NULL`属性
6.Federated存储引擎
6.1. Federated介绍
允许本地访问远程MySQL数据库中表的数据
本地不存储任何数据文件
类似Oracle中的DBLink
Federated存储引擎默认不开启, 需要在`my.cnf`的`[mysqld]`标签下添加 `federated`
MySQL的Federated不支持异构数据库访问,MariaDB中的`FederatedX`支持
6.2 Federated 语法
例句如下:
6.3 Federated测试
终端A(root@252)-192.168.48.168
终端B(proxy.gczheng.com)-192.168.24.180
5.MySQL数据类型
一. INT类型
1. INT类型的分类
TINYINT
存储空间 : 1 字节
取值范围
有符号(signed) : [-128, 127]
无符号(unsigned) :[0, 255]
SMALLINT
存储空间 : 2 字节
取值范围
有符号(signed) : [-32768, 32767]
无符号(unsigned) :[0, 65535]
MEDIUMINT
存储空间 : 3 字节
取值范围
有符号(signed) : [-8388608, 8388607]
无符号(unsigned) :[0, 16777215]
INT
存储空间 : 4 字节
取值范围
有符号(signed) : [-2147483648, 2147483647]
无符号(unsigned) :[0, 4294967295]
BIGINT
存储空间 : 8 字节
取值范围
有符号(signed) : [-9223372036854775808, 9223372036854775807]
无符号(unsigned) :[0, 18446744073709551615]
2. INT类型的使用
自增长ID
`推荐`使用`BIGINT`,而不是INT;
unsigned or signed
根据实际情况使用,一般情况下推荐`默认`的`sigend`
unsigned 的注意事项
一般情况下使用`int`时,推荐有符号数`(signed)`, 使用无符号数只是比原来多一倍的取值,数量级上没有改变。
如果需要取值超过10位以上,直接选择用`BIGINT`类型
3. INT(N)
int(N) 和 zerofill
int(N)中的`N`是显示宽度,`不表示`存储的数字的`长度`的上限。
`zerofill`表示当存储的数字`长度 < N`时,用`数字0`填充左边,直至补满长度`N`
当存储数字的长度`超过N时`,按照`实际存储`的数字显示
int(N)中的`N`和`zerofill`配合才有意义,且仅仅是显示的时候才有意义,和实际存储没有关系,不会去截取数字的长度。
4. AUTO_INCREMENT
自增
每张表一个
必须是索引的一部分
`AUTO_INCREMENT`是实例启动时,取当前表的最大值,然后 +1 即为下次自增的值。`(MAX + 1)`
注意: `insert into tablename select NULL;` 等价与 `insert into tablename values (NULL);`
二. 数字类型
1. 数字类型的分类
单精度类型:FLOAT
存储空间:4 字节
精确性:低
双精度类型:DOUBLE
占用空间:8 字节
精确性:低,比FLOAT高
高精度类型:DECIMAL
占用空间:变长
精确性:非常高
注意:财务系统必须使用DECIMAL
三. 字符串类型
1. 字符串类型介绍
2. N和字符集
char(N)
假设当前table的字符集的`最大长度`为`W`, 则`char(N)`的最大存储空间为 `(N X W)Byte`;假设使用`UTF-8`,则char(10)可以最小存储10个字节的字符,最大存储30个字节的字符,其实是另一种意义上的`varchar`
当存储的字符数`小于N`时,尾部使用`空格`填充,并且填充最小字节的空格
测试
hexdump idb文件
varchar(N)
测试
hexdump idb文件
插入数据尾部带空格
3.BLOB和TEXT
在BLOB和TEXT上创建索引时,必须指定索引前缀的长度
BLOB和TEXT列不能有默认值
BLOB和TEXT列排序时只使用该列的前max_sort_length个字节
不建议在MySQL中存储大型的二进制数据,比如歌曲,视频
四. 字符集
1. 常见的字符集
utf8
utf8mb4
gbk
gb18030
2. collation
修改默认的collation
五. 集合类型
集合简介
集合类型ENUM 和 SET
SET类型最多允许64个值
通过sql_mode参数可以用户约束检查
ENUM类型最多允许65536个值
1. 集合类型 sql_mode
2. 集合类型的排序
六. 日期类型
1. TIMESTAMP和DATETIME
2. 微秒
从MySQL5.6.X开始,支持微秒,最大显示6位
3. 时间函数
常用函数
4. 字段更新时间
七. JSON类型
1. JSON介绍
什么是 JSON ?
JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
JSON 是轻量级的文本数据交换格式
JSON 独立于语言 *
JSON 具有自我描述性,更易理解
`MySQL5.7.8`开始支持JSON数据类型。
对比存储在字符串,JSON格式的JSON数据类型提供了这些优点:
自动验证存储在JSON列中的JSON文档 ,无效的文档会产生错误。
优化的存储格式
2. JSON格式示例
3. JSON VS BLOB
JSON
JSON数据可以做有效性检查;
JSON使得查询性能提升;
JSON支持部分属性索引,通过虚拟列的功能可以对JSON中的部分数据进行索引;
BLOB
BLOB类型无法在数据库层做约束性检查;
BLOB进行查询,需要遍历所有字符串;
BLOB做只能做指定长度的索引;
对比
5.7之前,只能把JSON当作BLOB进行存储。数据库层面无法对JSON数据做一些操作,只能由应用程序处理。
4.结构化和非结构化
结构化
二维表结构(行和列)
使用SQL语句进行操作
非结构化
使用Key-Value格式定义数据,无结构定义
Value可以嵌套Key-Value格式的数据
使用JSON进行实现
5. JSON操作示例
JSON入门
JSON常用函数介绍
JSON创建索引
JSON类型数据本身无法直接创建索引,需要将需要索引的JSON数据重新生成虚拟列(Virtual Columns)之后,对该列进行索引
新建表时创建JSON索引
修改已存在的表创建JSON索引
附录
6.MySQL表
一. 表(TABLE)
1. 表的介绍
表是关系数据库的核心
表 = 关系
表是记录的集合
二维表格模型易于人的理解
MySQL默认存储引擎都是基于行(记录)存储
每行记录都是基于列进行组织的
MySQL中数据库与表之间的关系
2. 表是数据的集合
3. 创建表
3.1. 临时表
临时表的创建
临时表只能`单独会话`中`存在`
`临时表` 和 `普通表` 同名问题
临时表是SESSION级别的, 当前用户logout或者其他用户登录上来,是无法看到这张表的
当临时表和普通表同名时,当前用户只能看到同名的临时表
创建表时带上if not exists进行表的存在性检查;同时建议在临时表的表名前面加上统一的prefix
临时表的作用
临时表主要的作用是给当前登录的用户存储临时数据或者临时结果的。
不要和SQL优化器在排序过程中内部帮你创建的临时表相混淆。
临时表的存储引擎
临时表存储位置
MySQL5.7.18 把临时表结构放在tmpdir,而数据表数据放在datadir
4. 查看表结构
5. ALTER TABLE
注意: 当表记录很大的时候,alter table会很耗时,影响性能
ONLINE DDL
5.6以后对在线DDL操作进行了优化,以提高性能。[官方文档](http://dev.mysql.com/doc/refman/5.7/en/innodb-create-index-overview.html)
二. 外键约束
1. 外键的介绍
2. 外键操作
1. cascade方式
在父表上update/delete记录时,`同步`update/delete掉子表的匹配记录
2. set null方式
在父表上update/delete记录时,将子表上匹配记录的`列设为null`
要注意子表的`外键列`不能为`not null`
3. No action方式
如果子表中有匹配的记录,则`不允许`对父表对应候选键进行update/delete操作
4. Restrict方式
同no action, 都是立即检查外键约束
5. Set default方式
父表有变更时,子表将外键列设置成一个`默认的值`但Innodb不能识别
外键约束,可以让数据进行一致性更新,但是会有一定的性能损耗,线上业务使用不多。
通常上述级联更新和删除都是由应用层业务逻辑进行判断并实现。
7.MySQL增删改查
一. SELECT语法介绍
二. LIMIT 和 ORDER BY
三. WHERE 条件
四. 七种JOIN
4.1. INNER JOIN(内连接)
4.2. LEFT JOIN(左连接)
4.3. RIGHT JOIN(右连接)
4.4. LEFT JOIN(左连接),左表独有
4.5. RIGHT JOIN(右连接),右表独有
4.6.FULL JOIN(全连接)
4.7.FULL JOIN(并集去交集)
4.8. 笛卡尔积
4.3. GROUP BY
五. 子查询
1. 子查询的使用
1.1. ANY / SOME
ANY关键词必须与一个比较操作符一起使用: =, >, <, >=, <=, <> (这个是!=的意思)
子查询中SOME和ANY是同一个意思
1.2. IN
in是ANY的一种特殊情况:"in" equals "= any"
select a from s1 where a in (select a in t2);是用的比较多的一种语法
1.3. ALL
ALL关键词必须与一个比较操作符一起使用 NOT IN 是 <> ALL的别名
2. 子查询的分类
独立子查询
不依赖外部查询而运行的子查询
相关子查询
引用了外部查询列的子查询
3. 子查询的优化
MySQL5.6之前
在`MySQL5.6`之前,优化器会把子查询重写成`exists`的形式
在`MySQL 5.6`之前,部分的子查询需要重写成join的形式 (注意表的大小)
MySQL 5.6之后
4. 包含NULL值的NOT IN
MySQL数据库的比较操作,除了返回1(True), 0(False)之外,还会返回NULL NULL和NULL的比较,返回的还是NULL
对于包含了NULL值的IN操作,总是返回True或者NULL NOT IN返回NOT True (False)或者NOT NULL (NULL)
EXISTS不管返回值是什么,而是看是否有行返回,所以EXISTS中子查询都是select *、select 1等,因为只关心返回是否有行(结果集)
六. INSERT
七. DELETE
八. UPDATE
九. REPLACE
十. UNION
1. UNION的作用是`将两个查询的结果集进行合并`。
2. UNION必须由`两条或两条以上`的SELECT语句组成,语句之间用关键字`UNION`分隔。
3. UNION中的每个查询必须包含相同的列(`类型相同或可以隐式转换`)、表达式或聚集函数。
如果知道数据本身具有唯一性,没有重复,则建议使用union all,因为union会做去重操作,性能会比union all要低
十一. 关联更新和行号查询
7.1. 关联更新
7.2. 显示行号(RowNumber)
7.3. 使用子查询实现RowNumber
1. 思路
假设当前在第N行记录,通过主键emp_no遍历有多少行的记录`小于等于`当前行,即为当前行的行数.
2. SQL语句
3.查询employees表下基层用户的最近详细信息(员工号,员工名字,职位,部门,工资)
十二. Rank
十三. 视图
2.1、创建视图
2.2、视图的算法
`UNDEFINED` : 默认方式,由MySQL来判断使用下面的哪种算法
`MERGE` : `每次`通过`物理表`查询得到结果,把结果merge(合并)起来返回
`TEMPTABLE` : 产生一张`临时表`,把数据放入临时表后,客户端再去临时表取数据(`不会缓存`)
十四. 触发器
3.1、触发器介绍
触发器定义
触发器的对象是`表`,当表上出现`特定的事件`时`触发`该程序的执行
触发器的类型
`UPDATE`
update 操作
`DELETE`
delete 操作
replace 操作
注意:drop,truncate等DDL操作`不会触发`DELETE
`INSERT`
insert 操作
load data 操作
replace 操作
3.2、触发器语法
创建触发器
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句。
trigger_order:值为FOLLOWS 或者 PRECEDES 后面跟上现有的触发器的名字(注意:这两个触发器的触发条件和触发时间必须一样)。如果为FOLLOWS,这个新的触发器就会在现有的触发器之后被触发。如果为PRECEDES,就会在现有的触发器之前执行。
trigger_body:触发器的程序体
注意
3.3、UPDATE 类型触发器
3.4、INSERT 类型触发器
3.5、Delete 类型触发器
3.6、显示和删除触发器
3.7、触发器总结
触发器对性能有损耗,应当非常慎重使用;
对于事物表,`触发器执行失败则整个语句回滚`;
Row格式主从复制,`触发器不会在从库上执行`;
因为从库复制的肯定是主库已经提交的数据,既然已经提交了说明触发器已经被触发过了,所以从库不会执行。
使用触发器时应防止递归执行;
3.8、触发器模拟物化视图
物化视图的概念
不是基于基表的虚表
根据基表实际存在的实表
预先计算并保存耗时较多的SQL操作结果(如多表链接(join)或者group by等)
模拟物化视图
8.存储过程和函数以及游标
一. 存储过程和函数
1.存储过程和函数介绍
`存储过程`和`函数`是在数据库中定义一些`SQL语句的集合`,然后`直接调用`这些存储过程和函数来执行已经定义好的SQL语句;
用户可以通过`存储过程名`和`传参`多次调用的程序模块;
存储过程和函数的特点:
使用灵活,可以使用流控语句、自定义变量等`完成复杂的业务逻辑`;
提高数据安全性,屏蔽应用程序直接对表的操作,易于进行审计;
减少网络传输;
提高代码维护的复杂度,实际使用需要结合业务评估;
2.创建存储过程和函数
2.1 创建存储过程
2.2 创建存储函数
明确指明函数的类型
1 DETERMINISTIC 不确定的
2 NO SQL 没有SQl语句,当然也不会修改数据
3 READS SQL DATA 只是读取数据,当然也不会修改数据
4 MODIFIES SQL DATA 要修改数据
5 CONTAINS SQL 包含了SQL语句
其中在function里面,只有 DETERMINISTIC, NO SQL 和 READS SQL DATA 被支持。如果我们开启了 bin-log, 我们就必须为我们的function指定一个参数。
3. 变量的使用
3.1 定义变量
3.2 为变量赋值
赋值方法一
赋值方法二
4.定义条件和处理程序
4.1 定义条件
4.2 定义处理程序
condition_value参数指明错误类型,该参数有6个取值。
sqlstate_value和mysql_error_code与条件定义中的是同一个意思。
condition_name是DECLARE定义的条件名称。
SQLWARNING表示所有以01开头的sqlstate_value值。
NOT FOUND表示所有以02开头的sqlstate_value值。
SQLEXCEPTION表示所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值。
sp_statement表示一些存储过程或函数的执行语句。
第一种方法是捕获sqlstate_value值。如果遇到sqlstate_value值为42S02,执行CONTINUE操作,并且输出"CAN NOT FIND"信息。
第二种方法是捕获mysql_error_code值。如果遇到mysql_error_code值为1146,执行CONTINUE操作,并且输出"CAN NOT FIND"信息。
第三种方法是先定义条件,然后再调用条件。这里先定义can_not_find条件,遇到1146错误就执行CONTINUE操作。
第四种方法是使用SQLWARNING。SQLWARNING捕获所有以01开头的sqlstate_value值,然后执行EXIT操作,并且输出"ERROR"信息。
第五种方法是使用NOT FOUND。NOT FOUND捕获所有以02开头的sqlstate_value值,然后执行EXIT操作,并且输出"CAN NOT FIND"信息。
第六种方法是使用SQLEXCEPTION。SQLEXCEPTION捕获所有没有被SQLWARNING或NOT FOUND捕获的sqlstate_value值,然后执行EXIT操作,并且输出"ERROR"信息。
5.游标的使用
5.1 声明游标
5.2 打开游标
5.3 使用游标
5.4 关闭游标
6. 流程控制语句
6.1 IF语句
6.2 CASE WHEN 语法
6.3 WHILE 循环
6.4 REPEAT循环
while 和 repeat对比
6.5 loop循环、LEAVE和ITERATE语句
7. 查看、修改、删除存储过程和函数
7.1 查看存储过程和函数
7.2 修改存储过程和函数
7.3 删除存储过程和函数
9.磁盘I/0和压试
一. 磁盘
1. 磁盘的访问模式
顺序访问
顺序的访问磁盘上的块;
一般经过测试后,得到该值的单位是`MB/s`,表示为磁盘`带宽`,普通硬盘在 50~ 100 MB/s
随机访问
随机的访问磁盘上的块
也可以用MB/s进行表示,但是通常使用`IOPS`(每秒处理IO的能力),普通硬盘在 100-200 IOPS
2. 磁盘的分类
HDD
盘片通过旋转,磁头进行定位,读取数据;
顺序性较好,随机性较差;
常见转速
笔记本硬盘:5400转/分钟;
桌面硬盘:7200转/分钟;
服务器硬盘:10000转/分钟、15000转/分钟;
SATA:120 ~ 150 IOPS
SAS :150 ~ 200 IOPS> 从理论上讲,15000转/分钟,最高是 15000/60 约等于250IOPS由于机械盘片需要旋转,转速太高无法很好的散热> 如果一个HDD对4K的块做随机访问是0.8MB/s,可通过`0.8 *(1 / 4)= 200` 或者 `(0.8 * 1000) / 4=200`得到`IOPS`,但是这个值存在部分干扰因素,如cache等
SSD
纯电设备
由FLash Memory组成
没有读写磁头
MLC闪存颗粒对一般企业的业务够用。目前SLC闪存颗粒价格较贵
IOPS高
50000+ IOPS
读写速度非对称 以 [INTEL SSD DC-S3500](http://www.intel.com/content/www/us/en/solid-state-drives/ssd-dc-s3500-spec.html)为例子:
Random 4KB3 Reads: Up to 75,000 IOPS
Random 4KB Writes: Up to 11,500 IOPS
Random 8KB3 Reads: Up to 47,500 IOPS
Random 8KB Writes: Up to 5,500 IOPS
当写入数据时,要先擦除老数据,再写入新数据
擦除数据需要擦除整个区域(128K or 256K)一起擦除(自动把部分有用的数据挪到别的区域)> 对比发现4K性能要优于8K的性能,几乎是2倍的差距,当然16K就更明显,所以当使用SSD时,建议数据库页大小设置成4K或者是8K,`innodb_page_size=8K`)上线以前,SSD需要经过严格的压力测试(一周时间),确保性能平稳
Endurance Rating
表示该SSD的寿命是多少
比如450TBW,表示这个SSD可以反复写入的数据总量是450T(包括添加和更新)
SSD线上参数设置
磁盘调度算法改为Deadline``` echo deadline > /sys/block/sda/queue/scheduler # deadline适用于数据库,HDD也建议改成Deadline```
MySQL参数
`innodb_log_file_size=4G` 该参数设置的尽可能大
`innodb_flush_neighbors=0`> 性能更平稳,且至少有15%的性能提升
SSD 品牌推荐
Intel
FusionIO
宝存
不是很建议使用PCI-E的Flash卡(PCI-E插槽的SSD)
性能过剩
安装比较麻烦
3. 提升IOPS性能的手段
通过 RAID 技术
功耗较高
IOPS在2000左右
通过购买共享存储设备
价格非常昂贵
但是比较稳定
底层还是通过RAID实现
直接使用SSD
性能较好的SSD可以达到 `万级别的IOPS`
建议可以用SSD + RAID5,RAID1+0太奢侈
4. RAID类别
RAID0
RAID1
RAID5
RAID6
RAID1+0 和 RAID 0+1
RAID5+0
5. RAID卡
BBU
Battery Backup Unit
目前几乎所有RAID卡都带BBU
需要电池保证写入的可靠性(在断电后,将RAID卡`内存`中的缓存的数据刷入到磁盘)
电池有充放电时间 (30天左右一个周期,充放电会切换成 Write Through,导致性能下降)
使用`闪存(Flash)`的方式,就不会有充放电性能下降的问题
RAID卡缓存
Write Backup (`强烈建议开启缓存`)
Write Through (不使用缓存,直接写入)
LSI-RAID卡相关命令
查看电量百分比``` [root@test_raid ~]# megacli -AdpBbuCmd -GetBbuStatus -aALL |grep "Relative State of Charge"Relative State of Charge: 100 %```
查看充电状态``` bash[root@test_raid ~]# megacli -AdpBbuCmd -GetBbuStatus -aALL |grep "Charger Status"Charger Status: Complete```
查看缓存策略``` bash[root@test_raid ~]# megacli -LDGetProp -Cache -LALL -a0Adapter 0-VD 0(target id: 0): Cache Policy:WriteBack, ReadAdaptive, Direct, No Write Cache if bad BBU```
6. 文件系统和操作系统
文件系统
XFS/EXT4
noatime (不更新文件的atime标记,减少系统的IO访问)
nobarrier (禁用barrier,可以提高性能,前提是使用write backup和使用BBU)> mount -o noatime,nobarrier /dev/sda1 /data
操作系统
推荐Linux
关闭SWAP
四. sysbench 测试io
4.1、Sysench测试前准备
4.1.1、压测环境
4.1.2、压测基准值
4.2、进行OLTP_IO测试
4.2.1、安装压测工具sysbench
标准安装
4.2.2、执行压测
4.2.2.1 创建128个表,并发线程数24个,总数据量128G
4.2.2.2 进行fileio(rndrw随机读写)测试
4.2.2.3 进行fileio(rndwr随机写)测试
4.2.2.4 进行fileio(rndrd随机读)测试
4.2.3、 执行结果
分别进行rndrw(随机读写)、rndwr(随机写)、rndrd (随机读)各3分钟,如图R2目录(/dev/sdl)IOPS:
rndrw(随机读写)平均读iops:334,平均写iops:223
rndwr(随机写)平均写iops:389.35
rndwr(随机读)平均读iops:697.23
4.2.4、 清除生成的数据
二. Linux I/0调度算法
1. CFQ
2. Deadline
3. Noop
三. MySQL的IO使用情况
1.iostat
2. performance_schema.threads
3. 存储结构对应关系
4. O_DIRECT
fwrite / fsync
`fwrite`是把数据写入文件系统层(Filesystem)(可能有cache),并不能保证写入Disk
`fsync`可以保证把数据写入到Disk(数据落盘)> 只通过`fwrite`写入数据特别快(因为有缓存),但随后调用`fsync`就会很慢,这个速度取决于磁盘的`IOPS`如果不手工执行`fysnc`,当Filesystem的`cache`小于`10%`时,操作系统才会将数据刷入磁盘。所以可能存在数据丢失的风险,比如掉电
O_DIRECT``` bash+-------------------+ +-------------------+ +-------------------+| | fwrite | | fsync | || Buffer Pool +---------------> Filesystem Cache +--------------> Disk || | | | | |+--------+----------+ +-------------------+ +---------+---------+ | ^ | | | innodb_flush_method = O_DIRECT | +-----------------------------------------------------------------------+```
10.InnoDB 存储引擎
1. InnoDB的历史
2. InnoDB的特点
3. InnoDB存储引擎的文件
3.1 概述
表空间文件
独立表空间文件
全局表空间文件
undo表空间文件(from MySQL5.6)
重做日志文件
物理逻辑日志
没有Oracle的归档重做日志
3.2 InnoDB - 表空间
表空间的概念
表空间是一个 `逻辑存储` 的概念
表空间可以由`多个文件`组成
支持裸设备(可以直接使用 `O_DIRECT`方式绕过缓存,直接写入磁盘)
表空间的分类
系统表空间 (最早只有系统表空间)
存储元数据信息
存储Change Buffer信息
存储Undo信息
甚至一开始 `所有的表和索引` 的信息都是存储在`系统表空间`中
随后InnoDB对其做了改进,可以使用独立的表空间
独立表空间
innodb-file-per-table=1 (开启支持每个表一个独立的表空间)
每张用户表对应一个独立的 `ibd文件`
分区表可以对应`多个ibd文件`
Undo表空间
MySQL5.6版本支持`独立`的`Undo表空间`
innodb_undo_tablespaces
临时表空间
MySQL5.7增加了`临时表空间`(ibtmp1)
innodb_temp_data_file_path
说明:
同一个表空间`(ibdata1)` 存储和 `独立表空间` 存储就 `性能` 上而言没有区别;
当需要删除表(drop table)时, `独立的表空间` 存储可以`直接删除文件` ,而 ibdata1 存储也只是把 该部分表空间标记为可用 ,所以从速度上看很难说哪个更快;但是 `删除文件` 后, ibdata1 占用的 `空间不会释放` ;
`分区表` 会产生 `独立` 的 ibd文件 ;
`独立的表空间` ,一个表对应一个 `ibd文件` ,给人的感觉更加直观;
单个 `ibd文件` 直接拷贝到新的数据库中无法直接恢复:
原因一: `元数据` 信息还是在 `ibdata1` 中
原因二:部分索引文件存在于 `Change Buffer` 中,目前还是存放于 `ibdata1文件中`
3.3 General表空间
方法一,链接idb文件
方法二,使用`通用表空间`
通过使用 `General Space` ,一个表空间可以对应`多张表`
当对表进行`alter`等操作时,还是和原来一样,无需额外语法指定表空间位置
可以简单的理解为把多个表的ibd文件合并在一起了
3.4 Undo表空间文件
innodb_undo_tablespaces = 3
创建3个undo表空间
3.5 重做日志文件
innodb_log_file_size
该文件设置的尽可能的大 ,模板中给出的大小是 4G
设置太小可能会导致脏页刷新 时hang住
4.InnoDB 表空间内部组织结构
一. 表空间内部组织结构
1.1表空间 – 区
区是最小的空间申请单位,区的`固定大小`为`1M`
innodb设置为 `page_size= 16K`, 那么一个区 `1M * 1024 / 16 = 64` 个页
同理 `page_size= 8K` 就是 `128`个页
同理 `page_size= 4K` 就是 `256`个页
通常说来,一次申请`4个区(4M)` 的大小(存在一次申请5个区的时候,但是绝大部分情况就是申请4个区)
单个区的`1M`空间内,`物理上是连续` 的(一次申请的4个区的空间之间(1M和1M之间)不保证连续)
1.2 空间 – 页
1.2.1 页的定义
页是`最小`的I/O操作单位
`data`的最小单位不是页,而是页中的 `记录`(row)
普通用户表中MySQL`默认`的每个页为 `16K`
从MySQL5.6开始使用 `innodb_page_size` 可以控制页大小
一旦数据库通过 `innodb_page_size` 创建完成,则后续无法更改
`innodb_page_size` 是针对 `普通表` 的, `压缩表` 不受其限制
1.2.2 如何定位到页
每个 `表空间` 都对应 一个 `SpaceID` ,而 `表空间` 又对应一个 `ibd文件` ,那么一个 `ibd文件` 也对应一个 `SpaceID`
因为 `表空间` <--> `idb文件` , `表空间` <--> `SpaceID` ,所以 `ibd文件` <--> `SpaceID`
ibdata1 对应的 SpaceID 为 0
每创建一个表空间(ibd文件) , SpaceID `自增长`(全局)
PageNumber
在一个表空间中,第几个`16K的页`(假设 innodb_page_size = 16K) 即为 PageNumber
1.3 压缩表
基于页的压缩,每个表的页大小可以不同(针对压缩表来讲)
1.3.1 key_block_size的含义
`key_block_size` 的可选项是1k,2k,4k,8k,16k(是页大小,不是比例)
不是将原来 `innodb_page_size`页大小的数据压缩成 `key_block_size` 的页大小,因为有些数据可能不能压缩,或者压缩不到那么小
压缩是将原来的页的数据通过压缩算法压缩到一定的大小,然后用 `key_block_size`大小的页去存放。
查看压缩比
`innodb_cmp_per_index_enabled` 这个参数默认关闭,开启对性能有影响
*key_block_size=16的含义*
假设`innodb_page_size = 16K`
设置`key_block_size = 16`是`有意义`的
`key_block_size`的设置`不影响压缩`本身*(只和数据本身以及zlib算法有关)*,只是确定`压缩后的数据`存放的`页大小`
字段类型如果是`varchar`,`text`等类型的数据,压缩的效果还是比较明显的
设置`row_format=compressed`就会压缩数据, `是否压缩`和设置`key_block_size`没有关系所以`key_block_size=16`的设置是有意义的,因为数据还是`进行了压缩`,压缩后的数据存放在`16K`大小的页中
1.3.2 压缩后的存储以及性能
`innodb_page_size=16k` 的的数据设置 `key_block_size=16` 是可以压缩的,且效果比较明显;
并不是 `key_block_size` 设置的越小,压缩率就越高,上图中 8K 和 4K 的压缩率几乎一样;
在启用压缩后, 16K 和 8K 的插入性能 要好于 原来 未压缩 的插入性能,所以 启用了压缩,性能不一定会变差 ;
在I/O Bound(IO密集型)的业务场景下,减少I/O操作的次数对性能提升比较明显。
`key_block_size` 的设置的值( 经验值 )通常为 innodb_page_size 的 1/2在MySQL的官方文档中,上面(包括之前谈的)都称之为 `InnoDB Table Compression`,其实不够准确,因为他是 基于页的压缩
1.3.3 透明表空间压缩
1.3.3.1 透明表空间压缩的创建
1.3.3.2 稀疏文件
1. 压缩后,原来16K的数据压缩成了4K;
2. 剩余的12K空间用特殊的字符填充(比如说是0);
3. 在写入文件系统时调用 `Punching holes` 写入,实则只写入4K的数据;
4. 被填充的12K的空间,可以提供给后序的插入,更新等使用;
5. 从innodb的角度看还是16K的页大小,只是文件系统知道该页只需要4K就能够存储(对innodb是透明的);
6. SpaceID 和 PageNumber 的读取方式没有改变(细节由文件系统屏蔽);
7. 由于文件系统的快大小是4K,所以压缩后存储的空间也是4K对齐的
比如16K压缩成了 10K ,那就需要 3个4K 去存储
1.3.3.3 系统以及文件系统的支持
操作系统以及内核
RHEL7 kernel >= 3.10.0-123
Debian 7 kernel >= 3.2
Ubuntu 12.04LTS kernel >= 3.2
Ubuntu 14.0.4LTS kernel >= 3.13
Oracle和Suse可以参考官方文档
文件系统
支持Hole Punch
比如XFS,EXT4,NTFS等
1.3.3.4 关于warning
二. 索引组织表
1. 每张表都 `必须有` 一个 `主键`
2. 根据 `主键` 的值构造一棵 `B+树`
3. 这棵B+树的 `叶子节点(leaf page)` 存放 `所有的记录(Row)`
4. `非叶子节点`(Non-leaf page)存放的`主键和指针`( 若干个{主键,指针}组成一个非页节点 )
这里的 `指针` 其实就是 `PageNumber` (这里 不需要SpaceID ,因为SpaceID对应的是 ibd文件 ,我们现在是在 ibd文件内部 查找数据)
2.1 主键
1. 判断表中是否有 `非空的唯一索引` ,如果有,该列即为主键 ;
如果存在`多个非空唯一索引`,以创建表时 `第一个定义` 的非空唯一 `索引` 为准,而 不是(columns)定义的顺序
2. 如果`上述条件都不符合`,则InnoDB自动创建一个`6字节大小`的指针;
2.2 索引组织表与堆表
2.2.1 堆表
2.2.2 索引组织表
2.2.2.1 索引组织表
1. `非叶子节点`(Non-leaf page)中不会存放所有的数据(Row)的 `{主键, PageNumber}`,而是从`叶子节点(leaf page)`中选出一个数据的`主键`,将这个`主键`和`该页的PageNumber`填入到`非叶节点(Non-leaf page)`中
2. 从逻辑上看,是`一棵B+树`,但是从物理上看都是`每个页(非叶子节点和叶子节点)`通过`指针`串在一起,使得逻辑有序。
2.2.2.2 二级索引
2.2.3 查询数据对比
堆表查询
索引组织表以及二级索引查询
2.2.4 Page的空间申请
叶子节点(leaf page) 由 `leaf page segment` 进行申请空间
非叶子节点(Non-leaf page) 由`Non-leaf page segment` 进行申请空间,所以索引由 `两个段`组成
1. leaf page segment
2. Non-leaf page segment`段(segment)` 是由 `区(extent)` 组成,申请空间就按照`区(extent)`进行申请(一般情况下一次申请4个区)
三. 主键测试
3.1 多个唯一非空键
3.2 系统定义主键(系统rowid)
当用户表中没有显示的`指定主键`,且`没有非空唯一键`时,系统会 `自定义` 一个 `主键` (6个字节,int型,全局,隐藏)
四. 页的结构
1. File Header
五. 记录
5.1 ROW_FORMAT
5.2 COMPACT 结构
5.3 COMPACT 示例
5.3.1 创建mytest表
创建mytest表,格式为compact,且没有显示定义主键和非空唯一键,故使用系统定义的ROWID。并插入三条记录。
5.3.2 将mytest表结构进行dump
5.3.3 将红色部分对应的第一条记录进行解析
variable string length list
03 02 01 ,表示有三个变长字段`(varchar,varbinary,text等)`,且`逆序存放`(为了提高CPU的cache的命中率)
NULL flag
00 , 这条记录中不存在NULL
Record Header
5个字节,比较底层(比如看该记录有没有被删除)
RowID
主键ID,`00 00 00 2b 68 00`,从这个值可以看出,不是每张表从1开始递增的,是全局的`ROWID`
TransactionID
`事物ID`
Roll Pointer
回滚指针
5.3.3 char 和 varchar 的区别
1. char(N) 中存储的数据的长度 `范围` 是 N ~ 4N ,当存储数据的长度 `M` , 未达到N 时,则填充空格(0x20),且空格的长度 `取最小` 的长度 `N-M`,而 `不是4N-M`
2. varchar(N) 则 `不填充空格`注意: `char`数据类型本来是定长数据,但是在 `多字节字符集` 下,表现的行为和 `varchar`类似,失去了原来的优势,当数据更新变长后可能无法 `原地更新`
5.3.4 原地更新(in place update)
原地更新不会占用`新的存储空间`
非原地更新需要删除`(物理删除)`原来的空间的数据,然后将更新后的数据插入到`页的后面`
删除的数据的空间,会插入到`Free_List`链表的 `头部`
原地更新 `不会触发页的分裂`
5.3.5 Reorganize
5.4 DYNAMIC
DYNAMIC相比COMPACT,优化了大对象记录的存储。
假设有一条记录有A,B,C,D 四列,其中D列的是text类型,且含有2W个字节的长度。
COMPACT
COMPACT会存储text中的前768个字节的数据,剩余的数据通过20个字节的指针指向溢出页
六. heap number
heap_number表示页中每个 记录插入 的顺序 序号
假设 插入 的数据是 a, b, d, e, g ;则对应的 heap_number 为 2,3,4,5,6-0 和 1 被 infimum 和 supermum 所使用
infimum 对应最小的heap_number
supermum 对应最大的heap_number,随着数据的插入,该值会更新
update对heap_number没有影响
heap_number是物理的,存储在row的 record_header 字段中
三 CheckPoint
3.1. CheckPoint的作用
`缩短`数据库的恢复时间
`缓冲池`不够用时,将`脏页刷新到磁盘`
`重做日志`不可用时, `刷新脏页`
数据页首先被`读入缓冲池中`,当数据页中的某几条记录被更新或者插入新的记录时,所有的操作都是在Buffer Pool 先完成的;
1. Buffer Pool中的某个页和磁盘中的某个页在`(Space, Page_Number)`上是相同的,但是其`内容可能是不同的`(Buffer Pool中的被更新过了),形成了脏页;
2. 要定期将缓冲池中的脏页刷回磁盘`(Flush)`,达到最终一致,即通过`CheckPoint机制`来刷脏页;
3.2. LSN (Log Sequence Number)
1. `Log sequence number` 和`Log flushed up` 这两个LSN可能会不同,运行过程中后者可能会小于前者,因为redo日志也是先在内存中更新,再刷到磁盘的。
2. `Pages flushed up` 与`Last checkpoint` 其实都指向了最后一个刷新到磁盘的页,只是`Pages flushed up` 代表了页中的`NEWEST_MODIFICATION` ,而`Last checkpoint` 代表了页中的`OLDEST_MODIFICATION` 。
`FLUSH LIST`使用`OLDEST_MODIFICATION` 进行记录并排序,那在刷新脏页时,`CheckPoint`的`LSN 值`就对应的是当前刷新到某个页的`OLDEST_MODIFICATION` ;
当某个页只被修改过一次,则`Pages flushed up` 与`Last checkpoint`会`相等`,反之多次修改,则`Pages flushed up`大于`Last checkpoint` ;
在恢复时,从CheckPoint 开始恢复,如果当前页的`LSN`大于`CheckPoint的LSN` ,则表示`不需要恢复`;
3.2.1 日志(redo)中的LSN:
假设当前的LSN为C ,此时对某个页做修改,则会产生M 个字节的日志(需要写入M个字节的日志),那此时的LSN 则为`C+M` 。依次类推,LSN是一个单调递增的值(字节数)。
日志中的LSN代表了日志一共写入了多少个字节。
3.2.2 页中的LSN:
`页`中也存在LSN,表示该页被修改的时候,对应的日志的LSN是多少;
`Page`中的LSN主要用在`恢复的时候`,Page中的LSN放在页头
3.2.3 CheckPoint LSN
1. 日志中的LSN = CheckPoint的LSN ,则表示所有页都已经刷回磁盘
2. 日志中的LSN > CheckPoint的LSN ,则表示还有页没刷到磁盘;如果是宕机,则需要用日志恢复。
3. 日志中的LSN < CheckPoint的LSN ,则报错
3.3 CheckPoint的分类
Sharp CheckPoint
将`所有的脏页`刷新回磁盘
通常在`数据库关闭`的时候
刷新时系统hang住
innodb_fast_shutdown={1|0}
Fuzzy CheckPoint
将`部分脏页刷`新回磁盘
对系统影响较小
innodb_io_capacity
最小限制为100
一次最多刷新脏页的能力,与IOPS相关
`SSD`可以设置在`4000-8000`
`SAS` 最多设置在`800多``(IOPS在1000左右)
3.4. 刷新
Master Thread Checkpoint
从 `FLUSH_LIST` 中刷新
FLUSH_LRU_LIST Checkpoint
从 `LRU_LIST`中刷新(即使不在脏页链表中)
5.5以前需要保证在 `LRU_LIST 尾部`要有`100个空闲页`(可替换的页),即 `刷新一部分数据` ,保证有100个空闲页
innodb_lru_scan_depth – 每次进行 `LRU_LIS`T 刷新的`脏页的数量`
应用到每个`Buffer Pool`实例,总数即为该值乘以`Buffer Pool`的实例个数,如果超过 `innodb_io_capacity` 是不合理的
建议该值不能超过 `innodb_io_capacity` / `innodb_buffer_pool_instances`
Async/Sync Flush Checkpoint
重做日志重用
Dirty Page too much Checkpoint
`innodb_max_dirty_pages_pct` 参数控制
七. Flush Neighbor Page (FNP)
刷新`脏页所在区`(`extent`)的`所有脏页`,合并`IO`,随机转顺序的优化;
`写入的数据太多`
`如果业务确实是频繁更新,那刷新也会很频繁`
对传统机械磁盘有意义;
innodb_flush_neighbors={0|1|2} `(`>=MySQL 5.6`)`
0`:表示关闭该功能`
1`:表示刷新一个区内的脏页`
2`:表示刷新几个` 连续 `的脏页`
`SSD`建议关闭次功能;
六. Adaptive Hash Index(自适应Hash索引)
`搜索的时间复杂度`
`B+`树`O(T)`,只能定位到该记录所在的页;
`哈希表` `O(1)`,可以直接定位到记录;
可以自己判断是否是活跃的页,如果是活跃的页,可以自动做`Hash`,管理员无需人工干预;
`MySQL5.6`版本后,官方`不推荐`使用自适应`Hash`索引`
CPU `使用率变高`,但是性能没有提升;
`MySQL5.7`中增加了`innodb_adaptive_hash_index_parts`,增加分片,以减少竞争;
`只对等值的操作有意义`;
五. Insert/Change Buffer
5.1. Insert/Change Buffer介绍
`MySQL5.5`版本以前叫做`insert buffer`,现在叫做`change buffer`
`提高辅助索引的插入性能`
`非唯一`的二级索引(`non-unique secondary index`)
`Insert/Change Buffer`是一个`持久化`的对象(在`ibdata1`中,同时也会写`redo`日志)`
`Insert/Change Buffer`页是一棵`B+`树,每次最缓存`2K`的记录`
开启后有`30%`的性能提升(默认开启)`
`MySQL5.5`版本之前,最大可以设置为`Buffer Pool`的`1/2`,现在最大只能设置为` 1/4
当`Insert Buffer`进行`合并`的时候,`性能下降
5.2. Insert/Change Buffer举例
对于`主键`(`a列`),每次插入都要立即插入对应的`聚集索引`页中(在内存中就直接插入,不在内存就先读取到内存)
对于`二级索引`(`secondary index`)(`b列`)
1. 在`没有 Insert/Change Buffer`时,每次插入一条记录,就要`读取一次页`(读取内存,或者从磁盘读到内存),然后将记录插入到页中;
2. 在`有 Insert/Change Buffer`时,当插入一条记录时,`先判断`记录对应要插入的`二级索引`(secondary index)页`是否`在`Buffer Pool`中:
如果该`二级索引`(secondary index)页`已经在Buffer Pool中`,则`直接插入`;
反之,先将其`Cache`起来,放到`Insert/Change Buffer`中,等到该`二级索引`(secondary index)页被`读到`时,将`Insert/Change Buffer`中该页对应的记录`合并`(`Merge`)进去,从而减少`I/O`操作;
5.3. Insert/Change Buffer 性能
1.左图使开启了`Insert/Change Buffer`,而右图未开启;
2.一开始都比较高是因为还没有全量的进行刷磁盘(脏页全部在`Buffer Pool`中,还没满)`
`如开始介绍时所说,当`Insert Buffer`进行合并的时候,性能进行下降`
3.开启`Insert/Change Buffer`后,`insert`的常量值在`5K`左右;
4.`SSD`场景下也建议开启;
5.4. Insert/Change Buffer 查看
insert / merges `就是插入的效率(插入一条记录,就要读取一次页);
5.5.Change Buffer
从`MySQL 5.5`以后,改名为`Change Buffer`,表示不仅仅适用于`insert`。`
副主题
1. Insert
副主题
2. Delete-Marking`(标记删除)`
副主题
3. Purge`(清除)`
副主题
4. innodb_change_buffering = all
all
none `(禁用)`
inserts
deletes
changes =`(insert & delete-marking)`
purge
四. Double Write
4.1 Double Write介绍
Double Write的目的是为了保证数据写入的可靠性,`避免partial write`的情况
partial write`(*部分写*)`
`16K`的页只写入了`4K`,`6K`,`8K`,`12K`的情况(此时是不完整、不干净的页);
`不可以`通过`redo log`进行恢复;
`redo`恢复的前提是该`页`必须是`完整、干净`的;
`Double Write`是`全局`的;
共享表空间存在一个`段对象 double write`,然后这个段`由2个区(1M)组成`
`2M`固定大小(`both file and memory`);
页在刷新时,首先`顺序`的写入到`double write`
然后再刷回磁盘(`ibd`)
2M循环覆盖
顺序`写入`(`一次`IO)
4.2 Double Write的开销
`Double Write`的`2M`数据是`顺序`刷入磁盘的,是`一次`IO``,该次`IO`的大小为`2M`。
开启`Double Write`的性能降低`5% \~ 25%`(`IO Bound`场景下降的最厉害)
`slave`服务器同样`需要开启`
4.3.Double Write可以关闭的前提
4.3.1.支持`原子`写的设备
`磁盘`
Funsion-IO
`宝存`
`文件系统`
ZFS (`Linux`上不推荐使用)
btrfs(`Linux`上不推荐使用)
使用`copy on wirte`机制,`不进行原地更新`,而是开辟新的位置,写成功后,将原来的页`释放`
本质上的思路还是`保留一个副本`
4.3.2. innodb_doublewrite参数
innodb_doublewrite=0 `可以关闭`double write`功能`
二. Buffer Pool与压缩页
2.1 查找Buffer Pool中的压缩页
2.2 压缩页在内存中的存放
压缩页存在于 unzip_LRU 中
2.3 伙伴算法
通过上述方式,`不同大小的页`可以在``同一个`Buffer Pool中使用 (可以简单的认为Free List是 按照页大小 来进行 划分 的)。
`不能`根据页大小来划分缓冲池,缓冲池中页的大小就是`固定的大小`( 等于innodb_page_size )
`LRU List`和`Flush List` 不需要按照页大小划分,都是统一的 `innodb_page_size`大小
2.4. 压缩页在内存中保留
被压缩的页需要在`Buffer Pool中解压` 。
`原来的压缩页`保留 在Buffer Pool中。
缺点是压缩页`占用`了Buffer Pool的空间,对于热点数据来说,相当于内存小了,可能造成性能下降(热点空间变小)。
所以在`开启`了`压缩`后,Buffer Pool的`空间`要相应`增大`;
如果启用压缩后`节省的磁盘IO`能够抵消掉Buffer Pool`空间变小`所带来的性能下降,那整体性能还是会上涨;
启用压缩的前提是,`内存尽可能的大`;
压缩页保留的原因:
是为了在更新数据的时候,将 `redo` 添加到`压缩页的空闲部分`,如果要刷回磁盘,可以直接 `将该压缩页刷回去`。如果该页被写满,则做一次 `reorganize操作`(在此之前也要做解压),真的写满了才做`分裂`。
保留压缩页是为了更快的`刷回磁盘`
`解压的页`是为了更快的查询
一. 缓冲池(Buffer Pool)
1.1 缓冲池介绍
每次`读写`数据都是通过 `Buffer Pool` ;
当`Buffer Pool` 中没有用户所需要的数据时,才去`硬盘中`获取;
通过 `innodb_buffer_pool_size`进行设置总容量,该值设置的越大越好;
innodb_buffer_pool_instances 设置为`多个`缓冲池;
总容量还是`innodb_buffer_pool_size`
设置多个`instance` 可将热点打散,提高并发性能(建议设置成CPU个数值)
Buffer Pool也是以 `页(page)`为单位的,且大小和`innodb_page_size`一致;
1.2 Buffer Pool 性能测试
18G的测试数据,80M条记录;
当 `Buffer Pool`使用的内存`超过数据库的大小`时,比如20G(库中所有数据都在内存中),此时的性能有了很大的提升;
该图测试的是`TPS (每秒事物数)`,sysbench中一个事物由18条SQL语句组成,即这里的QPS为4.5W
内存减少 `10%` ,性能下降 `60%`
1.3 Buffer Pool的管理
1.3.1 Buffer Pool 的组成
Buffer Pool 刚启动时,有一个个16K的`空白的页`,这些页就存放(链表串联)在 `Free List` 中
当读取一个数据页的时候,就从 `Free List` 中取出一个页,存入数据,并将该页放入到 `LRU List` 中
当 `LRU List` 中的页 `第一次` 被修改了,就将该页的 `指针`(page number) 放入了 `Flush List` (只要修改过,就放入,不管修改几次)
Flush List 中包含`脏页(数据经过修改,但是未刷入磁盘的页)`
Flush list 中存放的不是一个页,而是`页的指针(page number)`
1.3.2 查看Buffer Pool的状态
1. 使用命令 show engine innodb status\G
1. 使用元数据表 information_schema.INNODB_BUFFER_POOL_STATS
1.3.3 Buffer Pool 在线调整
从 MySQL 5.7 开始,可以在线修改 innodb_buffer_pool_size
MySQL 5.7之前的版本,修改`innodb_buffer_pool_size`,需要`重启`
1.3.4 LRU List 的管理
1.3.4.1使用`mid point` 的LRU算法
LRU是`Least Recently Used`的缩写,即`最近最久未使用`,常用于`页面置换算法`,是为虚拟页式存储管理服务的。
当该页被`第一次读取`时,将该页先放在 `mid point`的位置(因为无法保证一定是活跃);
取当被`读到第二次` 时,才将改页放入到 `new page` 的首部;
`innodb_old_blocks_pct` 参数控制 `mid point` 的位置,默认是 `37` ,即 3/8 的位置
过程如下:
1 : mid --> new
2 : mid --> old --> new
3 : mid --> old --> 刷回磁盘
4 : new --> old --> 刷回磁盘
当Free List中没有空余的页时,就需要从 `old page` 中最后的页(被淘汰的页)给取出,给新的查询所使用
如果被淘汰的页是`脏页(page number在Flush List中)`,则需要先`刷回磁盘后`,再给`新的查询`使用
避免扫描语句污染LRU
当使用 select * from tablename; 时,该语句会读取某个页很多次(即该页可能被读取了两次以上,读取一条记录,就需要读一次页 )
1.3.4.2 innodb_old_blocks_time
1. 当该页被第一次 `读取时`,将该页放在`mid point` 位置,但是随后无论你读多少次 ,我在这 `innodb_old_blocks_time` 的时间内都不管(都视作只读取了一次 ),等这个时间过去了(时间到),如果该页还是`被读取`了,我才把这个页放到 `new page` 的首部。
2. 通常 `select *` 扫描操作不会高于1秒,一个页很快就被扫完了。
1.4. Buffer Pool 的预热
1.4.1 Buffer Pool预热
在MySQL启动后(MySQL5.6之前),Buffer Pool中页的数据是`空的`,需要大量的时间才能把`磁盘中的页`读入到`内存中`,导致启动后的`一段时间性能很差`。
使用该方法预热,`强制扫描`,将数据刷入`buffer pool`,但是不能真正将热点数据放入`buffer pool` ;
select count(1) from table force index(PRIMARY) ;
select count(1) from table FORCE index(index name);
在 MySQL 5.6 以后,可以在 `停机` 的时候 `dump` 出 `buffer pool` 的数据(space,page number),然后在 `启动` 的时候 `Load` 进 `buffer pool`,该功能可以让MySQL启动时 `自动预热` ,无需人工干预。
1.ib_buffer_pool dump的`越多`,启动的`越慢`
2.频繁的`手工dump( set innodb_buffer_pool_dump_now = 1 )`,会导致`Buffer Pool中的数据`越来越少,是因为设置了 `innodb_buffer_pool_dump_pct`
3.如果做了高可用,可以定期dump,然后将该dump的文件传送到slave上,然后直接load`( set innodb_buffer_pool_load_now = 1 )``(slave上的(Space,Page)和Master上的 大致相同 )`
4.load `now` 和 dump`now`都是 `异步`在后台加载的,返回的速度很快
查看当前buffer pool中的数据的条数
innodb_buffer_pool_dump_pct,该百分比(N<100)不是你当前`buffer pool`的`总的数据(总页数)`的`N%`,而是你每个buffer pool实例中`最近使用的页`的`N%`
查看Buffer Pool中的Flush List
11.B+树和索引
一. 索引
1. 索引的定义
2. 二分查找
步骤一:设`low`为下标最小值`0`,`high`为下标最大值`9`;
步骤二:通过`low`和`high`得到`mid`,mid=(low + high)/ 2,初始时`mid`为下标`4`*(也可以=5,看具体算法实现)*;
步骤三:`mid=4`对应的数据值是31,31 < 48(我们要找的数字);
步骤四:通过二分查找的思路,将`low`设置为31对应的下标`4`,`high`保持不变为`9`,此时`mid`为`6`;
步骤五:`mid=6`对应的数据值是42,42 < 48(我们要找的数字);
步骤六:通过二分查找的思路,将`low`设置为42对应的下标`6`,`high`保持不变为`9`,此时`mid`为`7`;
步骤七:`mid=7`对应的数据值是48,48 == 48(我们要找的数字),查找结束;
通过3次`二分查找`就找到了我们所要的数字,而顺序查找需8次.
二. Binary Tree(二叉树)
1. 二叉树的定义
每个节点至多只有`二棵子树`;
二叉树的子树有`左右之分`,次序不能颠倒;
一棵深度为`k`,且有`$2^k-1$`个节点,称为满二叉树(Full Tree);
一棵深度为`k`,且root到k-1层的节点树都达到最大,第k层的所有节点都`连续集中`在最左边,此时为完全二叉树(Complete Tree)
2. 平衡二叉树(AVL-树)
左子树和右子树都是平衡二叉树;
左子树和右子树的高度差绝对值不超过1;
平衡二叉树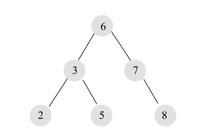
非平衡二叉树
平衡二叉树的遍历
`前序`:`6`, 3, 2, 5, 7, 8(ROOT节点在开头, `中`-左-右 顺序)
`中序`:2, 3, 5, `6`, 7, 8(中序遍历即为升序,左-`中`-右 顺序)
`后序`:2, 5, 3, 8, 7, `6`(ROOT节点在结尾,左-右-`中` 顺序)
平衡二叉树的旋转
三. B树/B+树
3.1. B树的定义
每个节点最多`有M个孩子`;
除了`root节点`外,每个`非叶子(non-leaf)节点`至少含有`(M/2)`个孩子;
如果`root节点`不为空,则root节点`至少`要有两个孩子节点;
一`个非叶子(non-leaf)节点`如果含有`K个`孩子,则包含`k-1个keys`;
所有叶子节点都在`同一层`;
B树中的`非叶子(non-leaf)节点`也包含了数据部分;
3.2. B+树的定义
数据只存储在叶子节点上,非叶子节点只保存索引信息;
`非叶子节点`(索引节点)存储的只是一个Flag,不保存实际数据记录;
`索引节点`指示该节点的左子树比这个Flag小,而右子树大于等于这个Flag
叶子节点本身按照数据的升序排序进行链接(串联起来);
叶子节点中的数据在`物理存储上是无序`的,仅仅是在`逻辑上有序`(通过指针串在一起);
3.3. B+树的作用
在`块设备`上,通过`B+树`可以有效的存储数据;
所有记录都存储在`叶子节点`上,`非叶子(non-leaf)`存储索引`(keys)信息`;
B+树含有非常高的`扇出(fanout`),通常超过`100`,在查找一个记录时,可以有效的减少IO操作;
3.4. B+树的操作
B+树的插入
B+树的插入必须保证插入后`叶子节点中的记录`依然`排序`。
插入操作步骤
B+树的删除
B+树使用`填充因子(fill factor)`来控制树的删除变化,`50%`是填充因子可设的最小值。B+树的`删除操作`同样`必须保证`删除后叶子节点中的记录依然排序。与插入不同的是,删除根据`填充因子`的变化来衡量。
删除操作步骤
3.5. B+树的扇出(fan out)
B+树图例
该 B+ 树高度为 2
每叶子页(LeafPage)4条记录
`扇出数为5`
叶子节点(LeafPage)由小到大(有序)串联在一起> `扇出` 是每个索引节点(Non-LeafPage)指向每个叶子节点(LeafPage)的指针> `扇出数` = 索引节点(Non-LeafPage)可存储的最大关键字个数 + 1> 图例中的`索引节点(Non-LeafPage)`最大可以存放4个关键字,但实际使用了3个;
3.6. B+树存储数据举例
查看数据表中每行记录的平均大小
高度为1
16K/200B 约等于 `80`个记录(数据结构元信息如指针等忽略不计)
高度为2> 非叶子节点中存放的仅仅是一个索引信息,包含了`Key`和`Point`指针;`Point`指针在MySQL中固定为`6Byte`。而`Key`我们这里假设为`8Byte`,则单个索引信息即为14个字节,`KeySize = 14Byte`
高度为2,即有一个索引节点(索引页),和N个叶子节点
一个索引节点可以存放 16K / KeySize = 16K / 14B = 1142个索引信息,即有(1142 + 1)个扇出,以及有(1142 + 1)个叶子节点(数据页) *(可以简化为1000)*
数据记录数 = (16K / KeySize + 1)x (16K / 200B) 约等于 80W 个记录
高度为3> 高度为3的B+树,即ROOT节点有1000个扇出,每个扇出又有1000个扇出指向叶子节点。每个节点是80个记录,所以一共有 8000W个记录
高度为4> 同高度3一样,高度为4时的记录书为(8000 x 1000)W> 上述的8000W等数据只是一个理论值。线上实际使用单个页的记录数字要乘以70%,即第二层需要70% x 70% ,依次类推。> 因此在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO,2~4次的IO意味着查询时间只需0.02~0.04秒(假设IOPS=100,当前SSD可以达到50000IOPS)。
四、二级索引
一. Secondary Index(二级索引)
1.1. Secondary Index 介绍
Clustered Index(聚集索引)
叶子节点存储所有记录(all row data)
Secondary Index(二级索引)
也可以称为非聚集索引
叶子节点存储的是索引和主键信息
在找到索引后,得到对应的主键,再回到聚集索引中找主键对应的记录(row data)
Bookmark Lookup (书签查找)
俗称回表
回表不止多一次IO
而是多N次IO(N=树的高度)
Secondary Index 查找数据
1.2. Secondary Index 回表
1. 假设查找`username`为Tom,先找二级索引`idx_username`,通过找到`key` 为Tom,并得到对应的`primary key:userid_a`。
2. 得到了`userid_a`后,再去找聚集索引中userid_a的`记录(row data)`。
3. 上述一次通过二级索引得到数据(row data)的查找过程,即为`回表`。整个过程都是MySQL自动帮你做的。
可以将上述的userinfo 表进行人工拆分,从而进行人工回表,拆分如下:
假设要查找TOM的`email` :
先查找`Tom` 对应的`userid` ,即找的是`idx_username表`(对应之前就是在idx_username索引中找tom)
得到`userid`后,再去`userinfo表`,通过`userid` 得到`email` 字段的内容(对应之前就是在聚集索引中找userid的记录(row data))
上述两次查找就是`人工回表`
1.3. 堆表的二级索引
在堆表中,是`没有聚集索引`的, 所有的索引都是`二级索引`;
索引的叶子节点存放的是`key`和`指向堆中记录的指针`(物理位置)
1.4. 堆表和索引组织表(IOT)二级索引的对比
`堆表`中的二级索引查找`不需要回表`,且查找速度和`主键索引一致`,因为两者的叶子节点存放的都是`指向数据的指针`;反之`IOT表`的的二级索引查找`需要回表`。
堆表中某条记录(row data)`发生更新且无法原地更新`时,该`记录(row data)的物理位置`将发生改变;此时, 所有索引中对该记录的`指针`都需要更新(代价较大);反之,IOT表中的记录更新,且主键没有更新时, `二级索引`都`无需更新`(通常来说主键是不更新的)
实际数据库设计中,堆表的数据无法原地更新时,且在一个`页内有剩余空间时`,原来数据的空间位置不会释放,而是使用指针指向新的数据空间位置,此时该记录对应的所有索引就无需更改了;
如果`页内没有剩余空间`,所有的索引还是要更新一遍;
IOT表页内是`有序的`,页与页之间也是有序的,做range查询很快。
1.5. index with included column(含列索引)
方案一:复合索引
方案二:拆表
对于含有多个索引的IOT表,可以将索引拆成不同的表,进而提高查询速度
但是实际使用中,就这个例子而言,使用复合索引,代价也不会太大。
二. Multi-Range Read 多范围读(MRR)
2.1. 回表的代价
对于查询语句1 ,假设一个页中有100条记录,则只需要`100次IO`;
对于查询语句2 ,此次查询中,假设`聚集索引`和`hire_date索引`(二级索引)的高度都是3 ,且查找1W 条(假设不止1W条),则需要查询的IO数为(3+N)+3W
`3` 为第一次找到hire_date>=1990-01-01 `所在的页(二级索引)的IO次数`
`N` 为从第一次找到的页`往后读页的IO次数`(注意二级索引也是连续的, 不需要从根再重新查找)
所以`3+N` 就是`在hire_date (二级索引)中读取IO的次数`
`3W` 为在IOT表中进行`回表`的次数
在MySQL5.6之前,实际使用过程中,优化器可能会选择直接进行`扫表`,而`不会`进行如此多的回表操作。
2.2. MRR 介绍
开辟一块`内存空间`作为`cache`
配置为`8M` ,注意是`线程级的`,不建议设置的很大;
参数`read_rnd_buffer_size`用来控制`键值`的`缓冲区大小`,当大于该值,执行器对已经缓存的数据根据`RowID`进行`排序`,并通过RowID来取得行数据
将`需要回表`的`主键`放入上述的`内存空间`中(空间换时间), 放满后进行`排序`(随机转顺序);
将`排序好数据`(主键)一起进行回表操作,以提高性能;
在`IO Bound` 的SQL场景下,使用`MRR`比`不使用MRR`系能提高将近`10倍`(磁盘性能越低越明显);
如果`数据都在内存中`,`MRR`的`帮助不大`, 已经在内存中了,不存在随机读的概念了(随机读主要针对物理访问)
二. MRR补充
三. 求B+树的高度
3.1 B+树
3.1 B+树高度
3.3. PAGE_LEVEL
3.4. 获取root页
3.5. 读取PAGE_LEVEL
`24640 = 8192 * 3 + 64`
其中`8192`是页大小
`root页`的`PAGE_NO` `为3`,表示是`第4个页`,则需要跳过前面`3个页`,才能`定位到root页`,所以要`*3`
然后加上`64` 个字节的偏移量,即可定位到`PAGE_LEVEL`
`-n 2`表示读取的字节数,这里读取2个字节,即可以读到`PAGE_LEVEL`根据上述`hexdump` 的结果,root页中的`PAGE_LEVEL` 为`2`,表示该索引的高度为`3`(从0开始计算)
五. MySQL索引
4.1. MySQL 创建索引
4.2. MySQL 查看索引
4.3. Cardinality(基数)
高选择性:身份证 、手机号码、姓名、订单号等
低选择性:性别、年龄等
4.4 复合索引
六. information_schema库
information_schema 数据库相当于一个数据字典。保存了表的元信息。
5.1 问题
5.1.1 哪张数据表中记录了Cardinality信息?
5.1.2 判断线上的索引是否有创建的必要?
SQL解释:
1. 从`information_schema.TABLES`表中获取`table_schema`, `table_name`, `table_rows`等信息。
3. 将`TABLES` 和 `STATISTICS` 表中的`table_schema`和`table_name`相关联并通过`Cardinality`和`table_rows` 计算,即可得到对应`索引名`
3.1 因为存在`复合索引`,所以我们要取出复合索引中seq最大的哪个值,取出的cardinality值才是最大的
3.2 得到了`最大的seq`值,从而可以取出对应的`cardinality`值
3.3 最后通过`table_schema`和`table_name` 让上述的信息和TABLES表进行关联,获取employees库的所有使用情况
通过最后一列的`SELECTIVITY`是否接近1,判断该索引创建是否合理
注意:
`Cardinality`和`table_rows`的值,都是通过随机采样,预估得到的
当`analyze`前后,`Cardinality`值相差较多,说明该索引是不应该被创建的(`页上的记录数值分布不平`)
推荐 `SELECTIVITY 15%` 以上是适合的
七. Explain
1.explain说明
explain是解释SQL语句的执行计划,即显示该SQL语句怎么执行的
使用`explain`的时候,也可以使用`desc`
5.6 版本支持`DML语句`进行explain解释
5.6 版本开始支持`JSON格式`的输出
参数FORMAT
使用`format=json`不仅仅是为了格式化输出效果,还有其他有用的显示信息。
且当5.6版本后,使用`MySQL Workbench`,可以使用`visual Explain`方式显示详细的图示信息。
2.Explain输出介绍
2.1. id
2.2. select_type
MATERIALIZED
产生中间`临时表`(实体)
临时表自动`创建索引`并和其他表进行关联,提高性能
和子查询的区别是,优化器将可以进行`MATERIALIZED`的语句自动改写成`join`,并自动创建索引
2.3. table
通常是用户操作的用户表
``UNION得到的结果表
`` 排生表,由id=N的语句产生
``由子查询物化产生的表,由id=N的语句产生
2.4. type
2.5. extra
Using filesort:可以使用复合索引将filesort进行优化。提高性能
Using index:比如使用覆盖索引
Using where: 使用where过滤条件
12.SQL优化--JOIN算法
一. SQL优化--JOIN算法
1. JOIN 写法对比
2. JOIN的成本
两张表的JOIN的过程:
`回表`:在找到`二级索引`后,得到对应的`主键`,再回到`聚集索引`中找`主键`对应的`记录`
3. JOIN算法
nsted_loop join
simple nested-loop join
index nested-loop join
block nested-loop join
classic Hash Join
Only support in MariaDB
bached key access join
from MySQL 5.6
from MariaDB 5.5
3.1. simple nested loop join
`simple nested_loog join` 即`外表`(驱动表)中的每一条记录与`内表`中的记录进行判断
其算法解析如下:
假设外表的记录数为R,内表的记录数位S
1. `R` 表,该表只扫描了一次;
2. `S` 表,该表扫面了`count(R)` 次;
3. 该方法相当于是一个`笛卡尔积`,实际上数据库不会使用该算法;
4. 根据上面对于JOIN算法的评判标准来看,SNLJ的开销如下表所示:
3.2. index nested loop join
`index nested_loop join` 由于`内表`上有`索引`,将`外表扫描一次`,内表是通过查找内表相应的索引的方式,和外表的记录进行匹配。
1. S 表上有索引
2. 扫描R表,将R表的记录和S表中的索引进行匹配
3. R表上可以没有索引
4. 优化器倾向使用记录数少的表作为外表(又称驱动表)
5. 如果数据量大,`index nested loop join`的成本也是高的,尤其是在二级索引的情况下,需要大量的回表操作
6. 因为索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为外表。故`index nested_loop join`的算法成本如下表所示:
首先,辅助索引的index lookup是比较`随机I/O访问操作`。
其次,根据index lookup再进行回表`又是`一个`随机的I/O操作`。所以说,index nested_loop join最大的弊端是其可能需要`大量的离散操作`,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比`顺序I/O`,其还是慢了很多,依然不在一个数量级上。
3.3. block nested loop join
block nested loop join 可被用于联接的是ALL,index,range的类型
3.3.1 Join Buffer缓存的对象
3.3.2 Join Buffer的分配
Join Buffer可分为以下两类:
regular Join Buffer
incremental Join Buffer
3.3.3 Block Nested-Loop Join总结
3.4. MariaDB中的Hash Join算法
MariaDB中的`Hash Join`问题是,优化器`默认`不会去选择`Hash Join`算法
set join_cache_level = 4;
set optimizer_switch='join_cache_hashed=on';
3.5. batched key access join
set optimizer_switch='mrr_cost_based=off';
13.锁
一. 锁
1.1. 锁的介绍
什么是锁
对共享资源进行并发访问
提供数据的完整性和一致性
每个数据库的锁的实现完全不同
MyISAM`表锁`
InnoDB `行锁`(与Oracle的行锁不同)
MSSQL `行级锁` with 锁升级
latch
mutex
rw-lock
锁的区别
`latch` 是针对`程序内部的资源`(比如:全局变量)的锁的定义,而这里的 `lock` 针对的是数据库的 `事物`
`lock` 由 `latch` 来保证和实现
1.2. latch锁的查看
1.3. 锁的类型
1. S 行级共享锁
2. X 行级排它锁锁
3. IS
4. IX
5. AI 自增锁
1.4. 意向锁介绍
1. 揭示下一层级请求的锁的类型
2. IS:事物想要获得一张表中某几行的共享锁
3. IX:事物想要获得一张表中某几行的排他锁
4. InnoDB存储引擎中意向锁都是 `表锁`
假如此时有 `事物tx1` 需要在 `记录A` 上进行加 `X锁` :
1. 在该记录所在的 `数据库` 上加一把 `意向锁IX`
2. 在该记录所在的 `表` 上加一把 `意向锁IX`
3. 在该记录所在的 `页` 上加一把 `意向锁IX`
4. 最后在该 `记录A` 上加上一把 `X锁`
假如此时有 `事物tx2` 需要对 `记录B` (假设和记录A在同一个页中)加 `S锁` :
1. 在该记录所在的 `数据库` 上加一把 `意向锁IS`
2. 在该记录所在的 `表` 上加一把 `意向锁IS`
3. 在该记录所在的 `页` 上加一把 `意向锁IS`
4. 最后在该 `记录B` 上加上一把 `S锁`
加锁是 从上往下 , 一层一层进行加的
假如此时有 `事物tx3` 需要在 `记录A` 上进行加 `S锁`:
1. 在该记录所在的 `数据库` 上加一把 `意向锁IS`
2. 在该记录所在的 `表` 上加一把 `意向锁IS`
3. 在该记录所在的 `页` 上加一把 `意向锁IS`
4. 发现该记录被锁定`( tx1的X锁 )`,那么 `tx3需要等待` ,直到 `tx1` 进行commit
1.5. 意向锁的作用
`意向锁` 是为了实现 `多粒度的锁` ,表示在数据库中不但能实现 `行级别的锁` ,还可以实现 `页级别的锁` 、`表级别的锁` 以及 `库级别的锁`。
如果没有意向锁,当你去锁一张表的时候,你就需要对表下的所有记录都进行加锁操作,且对其他事物刚刚插入的记录(游标已经扫过的范围)就没法在上面加锁了,此时就没有实现锁表的功能。
`InnoDB`没有`数据库级别的锁`,也没有 `页级别的锁`(InnoDB只能在 `表` 和 `记录` 上加锁),所以InnoDB的 意向锁 只能加在 `表` 上,即InnoDB存储引擎中意向锁都是 `表锁`
1.6. 加锁以及查看
1.6.1 加锁测试
步骤一:终端1
步骤二:终端2
步骤三:终端1
1.6.2 INNODB_TRX
步骤一:终端1
步骤二:终端2
INNODB_TRX 表
1.6.3 INNODB_LOCKS和INNODB_LOCK_WAITS
步骤一:终端1
步骤二:终端2
步骤三:终端1
INNODB_LOCKS表
INNODB_LOCK_WAITS表
二. 锁与并发
locking (锁)
concurrency control (并发控制)
isolation (隔离级别)
serializability (序列化)
2.1. 事物隔离级别
1.READ UNCOMMITED
2.READ COMMITTED
Oracle、DB2、Microsoft SQL Server (默认)
解决 `脏读` (ANSI SQL)
3.REPEATABLE READ
InnoDB(默认)
解决 `脏读 、不可重复读` (ANSI SQL)
InnoDB中的RR解决了`幻读问题` (实现了事物的隔离级别)
4.SERIALIZABLE
解决 `脏读 、 不可重复读 和 幻读` (ANSI SQL)
2.1.1 隔离性
什么是隔离性?
`一个事物` 所做的`修改` ,对 `其他事物` 是 `不可见` 的,好似是 `串行` 执行的
终端1
终端2
终端1
终端2
2.1.2 脏读
终端1
终端2
终端1
2.1.3 不可重复读
终端1
终端2
终端1
终端2
终端1
2.1.4 幻读
终端1
终端2
终端1
不可重复读:在一个事物中,针对同一条记录,执行两次相同的SQL得到的结果不一样
幻读:在一个事物中,执行两次相同的SQL,得到了不同的结果集(新增了部分记录或者缺失了部分记录)(不是同一条记
三. 锁的算法
Record Lock (行锁)
`行锁`锁定`单条索引记录`,锁住的是`索引`,而非`记录本身`,即使`没有索引定义表`, InnoDB创建一个`隐藏的聚集索引`,并使用此索引进行记录锁定.
Gap Lock (间隙锁)
`间隙锁`锁定是`索引记录之间`的`间隙`的锁定,也可以是`最后一个索引记录`之前`或`之后的`间隙`的锁定,并不包括该`索引记录本身`;对于使用`唯一索引`锁定`行`以`搜索唯一行`的语句,`不需要`使用`间隙锁定`。(这`不包括`搜索条件`仅包含多列唯一索引`中的某些列的情况;在这种情况下,会发生间隙锁定)
Next-Key Lock
索引记录上的`记录锁`和索引记录之前的间隙上的`间隙锁`的`组合`,锁定一个范围,并且锁定记录本身
3.1. Record Lock
假如t_nums表A列有`记录10,20,30,40,50`(只有这三个记录),且在`记录30`上加锁
对于在`记录30`上加锁,表示`该记录上加了行锁`
`[30, 30]`:只锁定`记录30本身`
终端1
终端2
3.2. Gap Lock
假如t_nums表A列有`记录10,20,30,40,50`(只有这三个记录),且在`记录30`上加锁
对于在`记录30`上加锁,表示在`记录10` 到`记录30` 之间加锁(30的前面个记录10,20)
(10, 30) :锁定该范围,`不包含`两个`边界`(不能插入10、30等在这个范围内的数据,但是可以对10和30做删除或者修改)
Gap Lock解决了`幻读问题`
终端1
终端2
3.3. Next-Key Lock
假如t_nums表A列有`记录10,20,30,40,50`(只有这三个记录)),且在`记录30`上加锁
对于在`记录30`上加锁,表示在`记录10`到`记录30`范围加锁(Gap Lock)的同时,同时在`记录30`上也行锁
(10, 30] :`锁定该范围`,且包含`记录30本身`(不能插入11、18等在这个范围的数据,同时对记录30不能删除或修改,记录10可以删除或修改)
注意:锁住的是索引
终端1
终端2
3.4 隔离级别和锁
3.4.1 REPEATABLE-READ级别
终端1
终端2
终端3
总结:
副主题
1. `REPEATABLE-READ`级别下的锁默认为 `Next-Key Lock`
副主题
2. `REPEATABLE-READ`会对`游标`打开的`所有的记录`进行加锁
3.4.2 READ-COMMITTED级别
终端1
终端2
3.4.3 Next-Key lock优化为Record lock
REPEATABLE-READ隔离级别
终端1
终端2
3.4.4 非唯一索引的等值查询
3.4.4.1 REPEATABLE-READ隔离级别
终端1
终端2
3.4.4.2 READ-COMMITTED隔离级别
终端1
终端2
3.4.5 非等值查询 (假如REPEATABLE-READ级别没有Gap LOCK情况)
3.4.6 二级索引列的等值查询
3.4.6.1 REPEATABLE-READ隔离级别
终端1
终端2
3.4.6.1.1 问题1
3.4.6.1.2 问题2
终端1
终端2
终端3
3.4.6.2 READ-COMMITTED隔离级别
终端1
终端2
当查询条件是二级索引列的等值查询时
副主题
1. `READ-COMMITTED` 模式下,二级索引查询的记录上有一个记录锁, 对应的`聚集索引`上有一个记录锁
副主题
2. `REPEATABLE-READ` 模式下,二级索引查询的记录上有一个 `Next-Key Lock` ,该记录的下一个记录上有一个 `Gap-Lock (二级索引`);对应的聚集索引上有一个记录
3.5 插入意向锁(insert intention lock)
`插入意向锁` 本质上就是个 `Gap Lock`
普通Gap Lock `不允许` 在 `(上一条记录,本记录)` 范围内插入数据
插入意向锁Gap Lock `允许` 在 `(上一条记录,本记录)` 范围内插入数据
`插入意向锁的作用`是为了 `提高并发插入的性能`, `多个事务`同时写入`不同数据至同一索引范围(区间)内`,并`不需要等待`其他事务完成,不会发生锁等待
3.5.1. 插入的过程
假设现在有记录 `10,30,50,70` ;且为 `主键` ,需要插入记录 `25` 。
1. 找到 `小于等于25的记录` ,这里是 `10`
2. 找到 `记录10的下一条记录` ,这里是 `30`
3. 判断 `下一条记录30` 上是否有锁(如果有=25的情况,后面再讨论)
判断 `30` 上面如果 `没有锁` ,则 可以插入
判断 `30` 上面如果有 `Record Lock` ,则 可以插入
判断 `30` 上面如果有 `Gap Lock / Next-Key Lock` ,则无法插入,`(10, 30) / (10, 30]`;在 `30` 上增加`insert intention lock` (此时处于`waiting` 状态),当 `Gap Lock / Next-Key Lock` 释放时,等待的事物`(transaction`)将被 `唤醒` ,此时 `记录30` 上才能获得 `insert intention lock`,然后再插入 记录25
注意:一个事物 `insert 25`且没有提交,另一个事物 `delete 25` 时,记录25上会有`Record Lock`
3.5.2 插入意向锁的演示
默认隔离级别下演示
终端1
终端2
终端3
3.5.3 插入意向锁提高插入的并发性演示
终端1
终端2
终端3
终端1
3.6 锁的内部实现
`每个事物每个页` 一个锁对象
约100个字节
通过位图存放锁信息
内存占用少
没有锁升级
like Oracle
3.7 显式锁和隐式锁
3.7.1 显式锁和隐式锁
显式锁
显式锁是使用`全局记录锁哈希表`和`lock_t结构的锁`,通常用`show engine innodb status`能查看到
隐式锁
隐式锁`没有分配关联的lock_t对象`所谓的隐式锁,可以理解成一个`记录标记`,在内存的锁对象在hash中是不存在的。但我们在更新数据块时,会进行如下操作:
对于`聚集索引`,每次更改或插入记录会`同时写入`对应的`事务id`和`回滚段指针`。
对于`二级索引`,每次更改/插入`二级索引记录`,会更新`二级索引页`的`最大事务id`。
隐式锁的逻辑过程如下:
A. InnoDB的每条记录中都一个`隐含`的`trx_id`字段,这个字段存在于`簇索引`的`B+Tree`中。
B. 在操作一条记录前,首先根据记录中的`trx_id`检查该事务是否是`活动的事务(未提交或回滚)`。如果是活动的事务,首先将`隐式锁`转换为`显式锁`(就是为该事务添加一个锁)。
C. 检查是否有`锁冲突`,如果`创建锁`,并设置为`waiting状态`。如果`有冲突不加锁`,写数据,并将自己的`trx_id`写入`trx_id`字段。
D. 等待加锁成功`被唤醒`,或者超时。
E. 写数据,并将自己的`trx_id`写入`trx_id`字段。Page Lock可以保证操作的正确性。
3.7.2 显式锁(explicit lock)与隐式锁(implicit lock)的区别
explicit locK
gap explicit lock
no gap explicit lock
3.7.3 聚集索引记录的隐式锁
聚集索引记录中 implicit lock 的判断较为简单。
因为每个`聚集索引记录`都有个`事务id` 的`隐藏列`,只需要通过该`事务id` 判断当前是`否为活跃事务`就能得知是`否有 implicit lock`。若通过`事务 id` 查询得到该事务为`活跃事务`,则此聚集索引记录上有 `implicit lock` 。反之,则不含有 `implicit lock`。
3.7.3 二级索引记录的隐式锁
二级索引记录是`不含有事务id的隐藏列`,然而 ,每个二级索引页通过 `page header`的 `PAGE_MAX_TRX_ID` 保存一个`最大事务ID` ,当二级索引中的任何记录被更新后,都需要`更新PAGE_MAX_TRX_ID 的值`。因此判断二级索引记录的 `implicit lock` 分为两个步骤进行:
根据二级索引页的 `PAGE_MAX_TRX_ID值`进行判断,
通过`聚集索引记录`进行判断。
因此若当前 `PAGE_MAX_TRX_ID 值`小于`当前活跃事务的最小id 时`,则此`二级索引记录`不含有 `implicit lock`,即之前已经提交的事务修改了该记录。
若 `PAGE_MAX_TRX_ID` 大于等于`当前活跃事务的最id 时`,则存在下这些可能性:
存在某活跃事务,`修改了二级索引记录`,从而导致 PAGE_MAX_TRX_IDD 的更新
存在事务`(可能是活跃也可能已经完成提交操作)`,修改了页中其他的二级索引记录,从而导致 PAGE_MAX_TRX_ID 更新。
辅助索引记录的隐式锁参考(姜大佬(MYSQL内核:INNODB存储引擎 卷1)第九章锁)
3.8 一致性的非锁定读
终端1
终端2
四. 死锁
4.1 死锁的介绍
两个或两个以上的事务在执行过程中,因`争夺锁资源`而造成的一种`互相等待`的现象
AB-BA, A和B互相等待
解决死锁
超时,`死锁`和 `锁超时`不是同一个东西( `锁超时` 是 `解决死锁` 的一种方式)
--innodb_lock_wait_timeout,默认是50s
waits-for graph
自动死锁检测
4.2 AB-BA死锁演示
终端1
终端1
终端2
终端1
终端3
假如一个事物中有10个步骤,当执行到步骤8时:
出现普通错误,在步骤8中停止,只要重新执行步骤8即可,然后`再继续执行`后续操作
出现死锁时,该事物中,步骤8之前的操作都会`自动回滚`
4.3 官网两种死锁演示
4.3.1 第一种
终端1
终端2
终端3
终端1
终端2
终端3
终端1
死锁具体分析:
原来加在 `a记录15` 上的锁,都转移到了 `a记录20` 上了( 锁继承 )
1. 因为 `终端1` 中的事物 `回滚`,则 `a记录15` 标记为`删除(delete-mark)`;
2. 而`终端2` 和`终端3` 中的 `事物` 都对 `a记录15` 添加了 `S-Lock` (后台 Purge 线程会把 a记录15 给删除);
3. 此时`下一个记录`,即 `a记录20` 会`继承`之前 `a记录15`上的锁,所以上面看到了 `锁` 的信息都在 `a记录20` 上。
此时的锁的状态是:
1. `终端2` 持有`a记录20`的 `S Gap-Lock` ,并且等待`X locks gap insert intention lock`
2. `终端3` 持有`a记录20`的 S Gap-Lock ,并且等待 `X locks gap insert intention lock`
X Lock 和 S Lock 是不兼容的
`终端3` 的 `insert intention lock` 等待`会话2` 的 `S Gap-Lock` 的释放;
`终端2` 的 `insert intention lock` 等待`会话3` 的 `S Gap-Lock` 的释放;
都在等待对方释放,所以产生了死锁
完整的插入过程如下:
4.3.1 第二种
终端1
终端1
这种死锁的情况,线上是无法完全避免的,解决的办法就是 `程序端重试` 。
后续涉及Purge时,可以只使用 `两条SQL` 语句,就出现`死锁现象`,这里使用了3条SQL语句。
`mysqld-debug` 版本可以操作更多的参数(比如关闭purge),并且可以看到丰富的信息,可以用于`故障诊断`。
五.AI自增锁
5.1 自增锁
一个表一个自增
AUTO_INCREMENT PK
在事务提交前释放
其他的锁在事务提交时才释放
如果AI锁在提交后才释放,那其他事物就没法插入了,无法实现并发
5.2 演示
5.2.1 演示1
终端1
终端2
5.2.2 演示2
终端1和终端2
终端1
5.3 AI自增锁的方式
如果插入前能 `确定行数` 的,就是 `simple inserts`
insert into table_1 values(NULL, 1), (NULL, 2);
如果插入前 `不能确定行数` 的,就是 `bulk inserts`
insert into table_1 select * from table_2;
如果 `部分自增长,部分指定` 的,就是 `mixed-mode inserts`
1. 非ANSI SQL 标准
2. 效果并非预期所期望的那样
5.3.1 设置自增并发度
innodb_autoinc_lock_mode 是 `read-only` 的,需要修改后 `重启MySQL`
0 传统方式
在 `SQL语句执行完之后` ,AI锁才释放
例如:当 insert ... select ... 数据量很大时(比如执行10分钟),那在这个`SQL执行完毕前` ,其他事物是 `不能插入` 的(AI锁未释放)
这样可以保证在这个SQL语句内插入的数据,自增值是 `连续的`,因为在这个时间内,AI自增锁是被这个SQL`持有的,且没有释放`
1 默认参数( 大部分情况设置为1 )
`bulk inserts`, 同传统方式一样
对于 `bulk inserts` 的方式,和 `0 - 传统方式` 一样,在`SQL执行完之后`,`AI锁`才释放
simple inserts, 并发方式
在 `SQL运行完之前` , `确定自增值`之后 ,就可以`释放自增锁`了
> 因为 `bulk inserts` 不知道要插入多少行,所以只能等`insert结束后`,才知道 `N` 的值,然后 `一次性(ai + N)`
而 `simple inserts` 知道`插入的行数(M)`,所以可以`先 (ai + M)` ,然后将`锁释放掉`,给别的事物用,然后自己慢慢插入数据
参数2
所有自增都可以并发方式( 不同于Simple inserts的方式 )
同一SQL语句自增可能不连续
row-based binlog``` for (i = ai; until_no_rec; i++) { acquire AI_Lock # 插入前申请锁 insert one record... # 只插入一条记录 ai = ai + 1 # 自增值+1 release AI_Lock # 释放锁}```> 这样做的好处是,对于批量的、耗时的插入,SQL不会长时间的持有AI自增锁,而是插入 `一条` (有且仅插入一条,而simple inserts是确定好的M条)语句后就 释放 ,这样可以给别的事物使用,实现并发。但是这种方式 `并发度是增加`了 ,但是性能不一定变好,尤其是单线程导入数据时,要 `不断的申请和释放锁`对于批量插入来说,自增就可能变的`不连续了`(需要和开发沟通,是否可以接受)
5.4. 自增列与索引
5.5. 自增的两个参数
--auto_increment_increment = 1
--auto_increment_offset = 1
两个服务器上的User表的主键的值就没有交叉了
如果有三台服务器,则 `A:[offset = 1, increment=3] , B:[offset = 2, increment=3] , C:[offset = 3, increment=3]`
如果一开始不知道后面会有多少台服务器,则可以一开始把increment设置的大一点,比如是10,这样只会浪费一点自增值
这样做的目的是保证 `每个节点` 上产生的 `自增值` 是 `全局唯一`的,这样做并不能用来做双主(比如一些额外的唯一索引能保证全局唯一么)
14.事务和事务相关的功能
一. 事务
1.1. 事务相关的功能
transaction
redo
undo
purge
group commit
XA
transaction programming
1.2 开启/结束一个事务
方法一
begin;
SQL…;
commit / rollback;
方法二
start transaction;
SQL…;
commit / rollback;
案例1:
案例2:
1.3. 事务的ACID
A - Atomicity(原子性)
`一个事务`必须被视为一个`不可分割`的`最小工作单元`,整个事务中的`所有操作`要么`全部提交成功`,要么`全部失败回滚`,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
`undo`技术来保证。
相关的MySQL功能包括:
自动提交设置
COMMIT语句
ROLLBACK语句
INFORMATION_SCHEMA 表的操作数据
C - Consistency(一致性)
数据库总是`从一个一致性的状态`转换到`另一个一致性的状态`,事务的`开启`和`结束`,没有破坏数据的结构和约束。
`redo`技术来保证。
相关的MySQL功能包括:
InnoDB双写缓冲
InnoDB崩溃恢复
I - Isolation (隔离性)
通常来说,一个事务所做的修改在`最终提交以前`,对`其他事务`是`不可见的`
`lock`技术来保证。
相关的MySQL功能包括:
自动提交设置
声明`SET ISOLATION LEVEL`
InnoDB锁的`底层细节`。在性能调整期间,您可以通过INFORMATION_SCHEMA表查看这些细节。
D - Durable(持久性)
在`事务完成`以后,该事务所对数据库`所作的更改`便持久的`保存在数据库之中`,并不会被回滚。
`redo & undo`技术来保证。
相关的MySQL功能包括:
innodb_doublewrite
innodb_flush_log_at_trx_commit
sync_binlog
innodb_file_per_table
在存储设备(如磁盘驱动器,SSD或RAID阵列)中写入缓冲区。
操作系统是否支持fsync()系统调用
备份策略
分布式或托管式数据应用程序,MySQL服务器硬件所在的数据中心的特定特性以及数据中心之间的网络连接。
存储设备中的电池备份缓存。
不间断电源(UPS),保护运行MySQL服务器和存储MySQL数据的所有计算机服务器和存储设备的电源。
1.4. 事务的类型
扁平事务(Flat Transactions)
扁平事务中,`所有操作`都处于`同一层次`,其由`BEGIN WORK`开始,由`COMMIT WORK`或`ROLLBACK WORK`结束,其间的操作是`原子的`,要么`都执行`,要么`都回滚`,因此扁平事务的应用程序称为原子操作的的基本组成模块
其中commit work 约占96%,ROLLBACK WORK约占3%,1%强制结束
带有保存点的扁平事务(Flat Transactions with Savepoints)
除了`扁平事务`支持的操作外,允许在事务执行过程中回滚到`同一事务`中`较早的一个状态`
在MySQL内 非常有用
链事务(Chained Transactions)
在提交一个事务的时候,`释放不需要的数据对象`,将必要的处理上下文`隐式的传给`下一个要开始的事务
提交事务操作和开始下一个事务操作将合并成为一个原子操作。这意味着下一个事务将看到上一个事务的结果,就好像在一个事务中执行的一样
相当于在一个事务commit之后,立即打了一个begin(系统自动)
嵌套事务(Nested Transactions)
InnoDB不支持
BDB支持
分布式事务(Distrihuted Transactions)
在分布式环境下运行的`扁平事务`
参与分布式的`节点`都要`支持ACID`
举例:持卡人从招行银行的储蓄卡转账10000元到工商银行的储蓄卡
1.5. 事务演示
1.5.1 扁平事务(Flat Transactions)
1.5.2 带有保存点的扁平事务(Flat Transactions with Savepoints)
二. REDO
2.1. REDO的组成
REDO的组成
redo log block
redo log 都是`reod log block`组成,每块的大小为 `512 字节`。
redo log buffer
--innodb_log_buffer参数
通常8M已经足够使用
redo log file
--innodb_log_file_size 单个redo文件大小(推荐4~8G,官方建议等于`buffer_pool_size`大小)
--innodb_log_files_in_group 表示日志组中的`日志文件`的`数量`。默认值和推荐值是2
--innodb_log_group_home_dir redo文件的保存目录,建议`redo文件`和`数据文件`分开保存,选择更快的磁盘。
2.2. REDO Log Buffer的刷新条件
2.2.1 刷新条件
1. `master thread` `每秒刷新`redo的buffer到logfile
mysql 5.6版本后,增加 `innodb_flush_log_at_timeout` 参数,可以设置刷新间隔,默认为 `1秒`
2. `redo log buffer` 使用量`大于1/2时`进行刷新
3. `事务提交时`进行刷新
--innnodb_flush_log_at_trx_commit = {0|1|2}
2.2.2 redo日志写入过程
当`ib_logfile0`写满时,去写`ib_logfile1`,redo日志组进行`轮询插入`
优点:
这样做的好处是`不需要归档`减少了`IO操作` ;
缺点:
如果`redo_log_file`太小,则可能需要`等待`。因为当要`覆盖`log_file中的`log_block` 时,如果该 `log_block` 中的`脏页还没有进行刷新`的话,则需要`等待这个脏页`进行刷新,所以需要把 `redo log file` 设置的尽`可能的大`
2.2.3 如何判断 innodb_log_file_size 设置小了?
`Pages flushed`和`Log sequence number`两者之差表示 `redo log 还有多少没有刷新的磁盘`
如果该差值 `接近` 重做日志的总大小的`75%`时,表明你的innodb_log_file_size设置小了(75%左右就强制刷新了)
innnodb_flush_log_at_trx_commit
0:每次事务提交时不将`redo log buffer的数据`写入`redo log file`,而是 log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.
该模式下,innodb会`每秒一次`或者`redo log buffer`的数据大于50%时执行fsync操作。
1:每次事务提交时将`redo log buffer的数据`写入`redo log file`,并且进行`fsync操作`(刷到磁盘).
该模式下,innodb会`实时执行`fsync操作。
2:每次事务提交时将`redo log buffer的数据`写入`redo log file`,仅写入`file system的cache`中,但是`fsync操作`(刷到磁盘)并不会同时进行.
该模式下,innodb会`每秒执行一次`fsync操作。
innodb_flush_log_at_timeout
该值设置的越大,相对性能就好一些(io操作变少),但是万一发生宕机,丢失的数据也就越多。
2.3. 组提交
2.3.1 组提交
1. 一次fsync刷新多个事务
性能提高10~100+倍
通过sysbench工具,压试sysbench update_non_index.lua脚本(5.5有bug,性能较差)
2. InnoDB存储引擎原生支持
2.3.2 fsync
fsync
O_DIRECT 仅对`写数据`时有用,`redo log` 是`不通过` O_DIRECT 方式写入到磁盘的,而是写到`文件系统的缓存`中
O_DIRECT 仅`写数据到磁盘`,但是数据的 `元数据` 没有同步,比如time、owner、size等等
从数据的角度看,fsync可以将`元数据`同步到磁盘
fsync 可以将 `redo日志` (redo log buffer)从`文件系统的缓存`同步到磁盘
2.4 REDO日志的分类
Redo日志的分类
物理日志:记录整个页的变化(diff)
逻辑日志:Like SQL语句
物理逻辑日志:根据页进行记录,内容逻辑
2.5 redo日志优化
redo日志优化参考下面指导原则:
日志文件的组合大小(`innodb_log_file_size` * `innodb_log_files_in_group`)不能超过最大值`512GB`。
使您的重做日志文件大,甚至与`缓冲池(buffer_pool_size)`一样大 。
当InnoDB写完重做日志文件时,必须将`修改后的缓冲池的内容`写入`磁盘的 检查点`。`小的重做日志文件`导致许多不必要的磁盘写入。虽然从历史上看,`大的重做日志文件`会导致`冗长的恢复时间`,但现在`恢复速度更快`,您可以放心使用`大型重做日志文件`。
重做日志文件的大小和数量使用`innodb_log_file_size` 和 `innodb_log_files_in_group` 配置选项进行配置。
考虑增加`日志缓冲区(redo log buffer)`的大小 。
一个`大的日志缓冲区`允许`大事务运行`,而`无需在事务提交之前将日志写入磁盘`。因此,如果您有`更新,插入或删除多行的事务`,则使日志缓冲区更大可节省`磁盘I/O`。
日志缓冲区大小使用`innodb_log_buffer_size` 配置选项进行配置。
三. binary log(binlog日志)
通过在my.cnf中配置参数`log-bin [=name]`来启动二进制日志
log_bin = /dbdata/mysqldata/binlog
binlog文件以自己定义的`name [binlog]`开头的,在datadir中以 binlog.000001,binlog.000001 ....显示
`binlog.index` 为二进制索引文件
1.binlog是在MySQL层产生
2.redolog在innodb层产生
3.1. 查看当前binlog状态
通过查看 binlog_cache_use 、binlog_cache_disk_use 的状态
3.2. binlog的类型
1.statement
记录SQL语句(那如果有一些不确定的SQL语句,类似UUID()的函数、limit without order by,主从会出现不一致)
2.row
设置RC隔离级别,必须选这个(5.7.7默认)
记录SQL语句操作的哪些行(行的变化)
一张表一定要有主键(性能较高)
数据一致性高,可flashback
3.mixed
结合statement和row栺式(不推荐),默认使用`STATEMENT`格式,下面情况下会使用 `ROW 格式`:
副主题
1. 表的存储引擎为 NDB ,这时对表的 DML 操作都会以 ROW 格式记录。
副主题
2. 使用了 UUIDO USERO CURRENT_ USERO FOUND_ROWSO ROW_COUNTO等不确定函数。
副主题
3. 使用了 INSERT DELAY 语句。
副主题
4. 使用了用户定义函数 (UDF)
副主题
5. 使用了临时表(temporary table)
3.3 binlog events
3.4. binlog 演示
两种binlog格式的区别
3.5. mysqlbinlog
3.5. binlog_rows_query_log_events
3.6. row和statement 简单性能对比
1.当写入的数据量 `较小` 时,`row`和`statement`所占用的`磁盘空间差不多`;
2.当写入的数据量 `较大` 时, 例如:导入数据,或者批量操作时[update tb set a=a+1;]),ROW要`记录每行的变化`,所以占用`磁盘空间较大`。
3.且写入的数据量 `很大` 时,ROW格式下,`commit会比较慢`,因为他还要先`写如binlog`再`提交`才写入磁盘,时间耗费多◦
假设更新一张千万的表,产生的binlog可能会有几百上千兆,当commit时,写入的数据量就是几百兆,所以会有`阻塞`等待的效果。表现为`binlog在写入到磁盘`。
3.7. binlog_cache
3.7.1 判断当前 `binlog_cache_size 的设置是否合适?
通过查看 binlog_cache_use 、binlog_cache_disk_use 的状态,可以判断当前 `binlog_cache_size` 的设置是否合适。
`binlog_cache_size` 是`基于会话 (session)` 的,也就是说,当一个线程开始一个事务时, MySQL会自动分配一个大小为 `binlog_cache_size` 的`缓存`,因此该值的设置`不能过大`。
当一个事务的记录大于设定的 `binlog_cache_size` 时, MySQL 会把缓冲中的日志写人一个`临时文件`中,因此该值的设置`不能太小`。
如果参数 `Binlog_cache_disk_use` 次数很多,就要看一下 `binlog_cache_size` 设置是否 `太小` ,或者 `事物本身` 是否`太大`MySQL使用在OLTP的场景下,应该是很快速的小事物。如果有大的事物,应该把 `大的事物拆成小事物` 去执行
3.8. binlog与redo的一致性
使用 `内部分布式事务` 来保证一致性,
1.`InnoDB层`写`prepare log`
写的还是 `redo file` (或者就是redo log,只是内容不一样,这里不是记录页的变化了)
写入的是 `xid` (事物id,show binlog events in “bin.000056”)
准确的说, `xid` 是写在 `undo` 页上的
2.`MySQL层` 写 `binlog`
3.`InnoDB层` 写 `commit log` (这里同样也是redo log file)
1. 假设,如果 `没`有 第一步的 `prepare log` ,而是直接写第二步的`MySQL binlog`,以及接着写第三步的 `InnoDB commit log`
此时假设出现`binlog写入成功` ,而 `commit log(redo)写入失败` 的情况(比如宕机),那随后机器重启时`恢复` 时,就会对该事物 `回滚` ;
万一此时的 `binlog` 已经传递到了 `slave` 机器上,且slave上`commit` 了。那此时 `主从就不一致` (Master上回滚了)
2. 现在有 `prepare log` 了以后, `prepare log写入成功` , `binlog写入成功` ,而 `commit log(redo)写入失败` 的情况下;
此时事物恢复的时候, 检查到`prepare log写入成功`,`binlog写入成功` ,那就直接 `commit` 了(可以理解成补了那次失败的commit),而 `不管commit log是否写入成功` 了。
3. 如果 `prepare log写入成功 , binlog写入失败` 了,那`恢复`时,也会`回滚`
4. 如果 `没开binlog`,就没有第一和第二步, 只写第三步的`commit log` ,恢复的时候没有`commit log`,就会回滚
一个事物在`prepare log`中写入成功,在`binlog中写入成功`,那就 `必须要提交` (commit))
`xid` 即 `写入prepare log` 中,也会 `写入到binlog` 中,当恢复时,会 `对比xid`在两个文件中是否都存在,如果`都存在`,该xid对应的事物`才会提交`
1.在MySQL5.6以后, 写入`binlog(步骤二)` 和 `写入commit log(步骤三)` ,都是通过 `组提交`的方式刷入(fsync)到磁盘的。
2.在MySQL 5.7以后,写入 `prepare log(步骤一)` 也是通过 `组提交`的方式刷入(fsync)到磁盘的(在写binlog之前执行一次fsync,就批量刷入prepare log)
3.9. REDO 和 binlog的总结
1.`redolog`是 `InnoDB` 层的;`binlog`是 `MySQL` 层的。
2.`redolog`是 `物理逻辑` 日志;`binlog`是 `逻辑` 日志。
3.写入的`时间点`不一样
redo log 可以`有多个写入点`,比如`master thread刷新`,`buffer大于1/2`,`事物提交`等等
binlog只会在 `事物提交` 的时候写入
3.10. 分布式事务
终端1
终端2
终端1
终端2
1. 分布式事物是 `串行` 执行的(不能快照读),在分布式事物中,使用的是两阶段事物,如果prepare成功了,就一定要提交。
2. 如果发生commit失败,事物就变成了 `悬挂` 事物,需要人工介入,查看prepare是否成功,而后决定commit 或者 rollback
四. UNDO
4.1. Checkpoint
存在两个checkpoint(CP1和CP2),两个checkpoint循环写入
所以说,redo log的写入其实 `不是完全顺序` ,因为还需要更新checkpoint中的内容。
通过判断两个checkpoint中的值的大小,可以判断哪个checkpoint是最后写入的。即使使用小的checkpoint,也无非多恢复一些数据、多花一点时间而已。
设计成两个,主要是为了`容灾考虑`。
4.2. UNDO对象
rollback segment – 回滚段
undo log segment – undo段
undo 段才是真正的存储undo 日志
undo page
undo log
undo log record
4.2.1 rollback segment(回滚段)
MySQL 5.5 前`只有1个 rollback segment`
MySQL 5.5+ 有 `128个 rollback segment`
MYSQL 5.7.2 之后可以定制
innodb_undo_logs=128 –-表示Rollback segmentd的配置个数128
innodb_undo_tablespaces=3 –- 保存3个undo log文件
innodb_undo_directory=/dbdata/undologs/ –-表示undo存放的独立目录
回滚段slot 分配如下:
slot 0 ,预留给`系统表空间`;
slot 1- 32,预留给`临时表空间`,每次数据库重启的时候,都会重建临时表空间;
slot 33-127,如果有`独立表空间`,则预留给UNDO独立表空间;如果没有,则预留给系统表空间;
InnoDB undo的空间管理简图如下:
undo默认存放在 `ibdata1`中,即`系统表空间中`。
系统表空间中的内容:
1.double write
2.元数据信息(数据字典)
3.undo信息(5.6后可分离),分开放可避免竞争
innodb_undo_directory
innodb_undo_logs
innodb_undo_tablespaces
4.insert buffer / change buffer
4.2.2 undo log segment (undo段)
undo log segment
undo 日志
undo 日志页头(undo log page header)
每个事务最多需分配两个undo log page header
undo段段头(undo log segment header )
4.2.3 undo page
undo page
每个`undo page`可以保存`多个事务的undo log`
undo页重用
当页的使用空间小于¾
4.2.3 undo log
undo log 以`逻辑的方式`进行存储
undo log header 用于保存每个事务undo日志通用信息
undo log record
1.insert undo log record – 记录insert
2.update undo log record – 记录update和delete
包含undo 日志详细信息的undo页描述
ro ll back segment (trxOrseg. *) ;
undo segment (trxOundo. * ) ;
undo log (trxOrec . *) ;
undo 10g beader !
undo 10g record
整体结构
4.3. Purge
`真正`的删除记录
删除undo log
案例:
表t1中有记录pk=1,2,3;执行DELTE FROM t1 WHERE PK=1;
1.将pk=1的记录标记为`删除` (delete-mark,info bits),数据库中pk=1的记录此时还是存在的,`空间并没有被释放`,该操作为同步操作(SQL执行完,也就标记完成了)
2.`purge`调用后台线程(purge线程)异步操作,会真正的`删除该记录`,且`空间被释放`。purge线程是系统自动的,无法人工控制
标记为已删除的原因:
1.该事椌可能需要`回滚`,先作保留。
2.当 `事务1` 去删除pk=1且 `没有提交` 时,`事务2` 应该要能看到pk=1的记录(事务的隔离性)。
过滤条件是聚集索引
1.delete 将该记录标记为 `delete-mark` 。
2.update 将该记录 `先物理delete`(聚簇索引里主键相同的行最多只能有1个),然后 `insert`(或者可以原地更新[in place update])(即使删除了,也可以通过undo进行还原)。
过滤条件是二级索引
1.delete 将该记录标记为 `delete-mark` 。
2.update 将该记录标记为 `delete-mark`(索引列是columns + pk,即使是唯一索引更新也是和原来的不一样),然后 `insert`。
为什么没有insert
1.insert操作是不需要异步去purge,因为insert之前`记录是不存在的`;
2.不存在记录(未提交)是没有别的事务能引用到的,所以insert以后,对应的undo可以直接删除,而不需要等待异步purge
总结:
1.delete-mark的记录最后会`被purge线程回收`,Purge会`检测`记录上是否有其他事物在引用`undo`,如果没有就可以删除。
2.innodb_purge_threads (5.6以后),可以设置的大一些,回收的速度会快一些。
15.备份和恢复
一.备份的类型
1. 热备(Hot Backup)
在线备份
对应用无影响(应用程序不会被阻塞(其实有,只是时间很短),可以正常的读写,但是性能上还是有影响的)
2. 冷备(Cold Backup)
备份数据文件,最可靠的备份
需要停机(最大的弊端)
备份datadir下的所有文件
3. 温备(Warm Backup)
在线备份
对应用影响很大
通常加一个读锁(读不受影响,写被阻塞)
二.备份工具
1. ibbackup
官方备份工具
收费
物理备份
2. Percona XtraBackup
开源社区备份工具(必须使用最新版本,否则备份出来的数据可能有问题)
开源免费
物理备份
Xtrabackup老版本的问题
3. mysqldump/mysqlpump
官方自带备份工具,是可靠的,且备份文件相对较小
产生一组能够被执行以再现原始数据库对象定义和表数据的SQL语句
开源免费
逻辑备份
恢复速度较慢(需要重建索引等等)
4. mydumper
1. 有的热备都只能使`InnoDB存储引擎表`
2. `其他存储引擎表只能是`温备`
三.备份方式
物理备份
备份了 `表空间` 的数据,和冷备类似
逻辑备份
备份了 `表中` 的数据(导出的是一条条SQL)
从以下维度选择备份方式:
备份速度
恢复速度
备份大小
对业务影响
四.备份工具
4.1 mysqldump
4.1.1 mysqldump 简介
1.语法
2.常用参数
`--all-databases` :备份所有的数据库
mysqldump -uroot -p --all-databases > alldb.sql
`--databases` DB1 [DB2 DB3] :备份指定的数据库
mysqldump -uroot -p --databases db1 db2 > mulit.sql
`--flush-logs,-F`:设置导出前刷新binlog
mysqldump -uroot -p -F --databases db1 > db1.sql
`--no-data,-d`:设置导出CREATE TABLE表的语句
mysqldump -uroot -p -d --databases db1 > db1.sql
`--opt`:默认启用, 快速转储操作,并生成一个可以快速重新加载到MySQL服务器的转储文件
--add-drop-table --add-locks --create-options --disable-keys --extended-insert --lock-tables --quick --set-charset参数组合
mysqldump -uroot -p --opt --databases db1 > db1.sql
`--default-character-set`:设置导出的字符集
mysqldump -uroot -p --default-character-set=utf8 --databases db1 > db1.sql
`--single-transaction`: 在一个事物中导出,确保产生`一致性的备份`,适用于`事务引擎`,当前只针对innodb引擎
mysqldump --single-transaction -uroot -piforgot --databases db1 > db1.sql
`--master-data`:将CHANGE MASTER TO 语句写入导出的数据文件中
如果为1,将会输出CHANGE MASTER 命令
如果为2,输出CHANGE MASTER 命令,但前面加注释
mysqldump -uroot --single-transaction --master-data=2 --databases db1 > db1.sql
`--set-gtid-purged` :是否要把`gtid信息`写入导出的数据文件中
--set-gtid-purged=OFF: SET @@SESSION.SQL_LOG_BIN=0;不被添加到输出。
--set-gtid-purged=ON: SET @@SESSION.SQL_LOG_BIN=0;被添加到输出。
--set-gtid-purged=AUTO:SET @@SESSION.SQL_LOG_BIN=0;如果在正在备份的服务器上启用了GTID(即,如果AUTO 计算结果为ON),则会将其添加到输出中。
mysqldump --single-transaction --master-data=2 -uroot -piforgot --set-gtid-purged=OFF --databases baktest >/data5/backup_sm.sql
`--delete-master-logs`
在主复制服务器上,`PURGE BINARY LOGS` 执行转储操作后,通过向服务器发送语句来`删除二进制日志`。
mysqldump --single-transaction --master-data=2 --delete-master-logs -uroot -piforgot --set-gtid-purged=OFF --databases mytest >/data5/backup_20180208_1_PM.sql
4.1.2 mysqldump演示
4.1.2.1 准备数据
4.1.2.2 要对单一整数据库进行备份
4.1.2.3 对数据库进行恢复
方法一
会话A
会话B
会话A
会话B
方法二
4.1.2.4 要对单表进行备份
4.1.2.5 单库导出多张表结构及表数据,用空格隔开
4.1.2.6 要对多个数据库进行备份,用空格隔开
4.1.2.7 要对所有数据库进行备份
4.1.2.8 set-gtid-purged参数在备份中作用
4.1.2.9 通过将数据从一台MySQL服务器复制到另一台服务器, mysqldump对于填充数据库也非常有用,导入库可以不同名
会话A
会话B
会话C
语法:shell> mysqldump --opt db_name | mysql --host=remote_host -C db_name
会话B
4.1.3 对于InnoDB表进行在线备份的方式
1. --master-data参数
2. --single-transaction --master-data参数结合
3.备份的流程如下:
4.1.4 mysqldump备份恢复总结
1、mysqldump是通过`select * from table_name`来获取表的数据进而完成备份。
2、`START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */`必须放到`FLUSH TABLES WITH READ LOCK`和`UNLOCK TABLES`之间。
放到`之前`会造成`START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */和FLUSH TABLES WITH READ LOCK之间`执行的`DML语句丢失`,
放到之后,会造成`从库重复插入数据`。
3、mysqldump只适合放到业务低峰期做,如果备份的过程中数据操作很频繁,会造成Undo表空间越来越大。
4、`--single-transaction`开启`事务一致性快照`,开始`savepoint`,每次备份完执行`rollback to savepoint`为了防止表的`DDL阻塞`,而调整事务`隔离界别RR`为了保障会话的`可重复读`,从而达到备份数据的一致性。
4.1.5 mysqldump与锁
4.1.6 mysqldump详细参数
4.2. mysqlpump
4.2.1 mysqlpump简介
1.语法
2.主要的特点:
`并行`备份数据库和数据库中的对象的,加快备份过程。
更好的控制数据库和数据库对象`(表,存储过程,用户帐户)`的备份。
备份用户账号作为帐户管理语句`(CREATE USER,GRANT)`,而不是直接插入到MySQL的系统数据库。
备份出来直接生成`压缩后`的备份文件。
备份`进度指示`(估计值)。
重新加载(还原)备份文件,`先建表后插入数据最后建立索引`,减少了索引维护开销,加快了还原速度。
备份可以`排除或则指定数据库`。
绝大部分参数和mysqldump一致
3.mysqlpump 架构图
4.2.2 mysqlpump重要参数应用
1.并发相关
1.`--default-parallelism=#` 线程数,默认开 2 个线程进行并发备份
2.`--parallel-schemas=name` 哪些数据库进行并发
2.压缩相关
`--compress-output`:默认不压缩输出,目前可以使用的压缩算法有`LZ4`和`ZLIB`
4.2.3 mysqlpump演示
1.对employees数据库进行备份
2.查看备份的占用的线程,--default-parallelism默认配置为2个
3.多队列和多线程并发备份测试
4.compress压缩
5.还原
6.总结:
lz4压缩快,但是压缩比相对比较低,zlib反之
恢复要先解压缩,再恢复
4.2.4 mysqlpump原理分析
会话A
会话B
会话A
导出流程
1.线程`105` 进行 `FLUSH TABLES WITH READ LOCK` ,对表加一个`全局读锁`。
2.线程`105、106、107`由于之前加了`全局读锁`,然后`分别开启一个事物(RR隔离级别)`并生成`一致性快照`去备份数据,所以这三个线程备份出的数据是`一致性的`
3.线程`105` 解锁 `UNLOCK TABLE`。
4.查询库表各种状态,然后`select`导出
5.根据配置参数是否导出权限等
4.2.5 mysqlpump详细参数
4.2.6 mysqldump和mysqlpump对比
4.3. Percona XtraBackup
4.3.1 Percona XtraBackup 简介
特点:
(1)备份过程快速、可靠;
(2)备份过程不会打断正在执行的事务;
(3)能够基于压缩等功能节约磁盘空间和流量;
(4)自动实现备份检验;
(5)还原速度快;
工具集说明
xtrabackup:是用于热备份innodb, xtradb表中数据的工具,不能备份其他类型的表,也不能备份数据表结构;
innobackupex:是将xtrabackup进行封装的perl脚本,提供了备份myisam表的能力。
xbcrypt:用于加密和解密备份文件
xbstream :类似于tar,允许从xbstream格式流式解压文件
4.3.2 Percona XtraBackup 权限
需要的权限:
系统权限:
连接到服务器是为了执行备份,需要在`datadir`上有`read`,`write`和`execute`权限。
数据库中需要以下权限:
`RELOAD`和`LOCK TABLES` 在开始复制文件之前,有`RELOAD`和`LOCK TABLES`权限(除非指定了`--no-lock`选项)才能使`FLUSH TABLES WITH READ LOCK`和`FLUSH ENGINE LOGS`;在`LOCK TABLES FOR BACKUP`和`LOCK BINLOG FOR BACKUP`需要备份锁时,就需要这些权限,
`REPLICATION CLIENT` 为了获得二进制日志位置,
`CREATE TABLESPACE`权限为了导入表,用户表级别的恢复
`PROCESS`进程以运行SHOW ENGINE INNODB STATUS(这是必需的),并且可以选择查看服务器上正在运行的所有线程,
`SUPER`为了在复制环境中`启动/停止`slave线程,使用`XtraDB改变页`跟踪增量备份和跟进`FLUSH TABLES WITH READ`锁操作,
`CREATE`权限为了创建 `PERCONA_SCHEMA.xtrabackup_history`数据库和表,
`INSERT`为了将`历史记录`添加到 `PERCONA_SCHEMA.xtrabackup_history`表中,
`SELECT`权限,以便使用`innobackupex --incremental-history-name`和 `innobackupex --incremental-history-uuid`查找`PERCONA_SCHEMA.xtrabackup_history`表中`innodb_to_lsn`的值
4.3.3 Percona XtraBackup 演示
4.3.3.1 创建全备和恢复
全备
各文件说明:
(1)xtrabackup_checkpoints --备份类型(如完全或增量)、备份状态(如是否已经为prepared状态)和LSN(日志序列号)范围信息;
(2)xtrabackup_binlog_info --mysql服务器当前正在使用的二进制日志文件及至备份这一刻为止二进制日志事件的位置。
(3)xtrabackup_binlog_pos_innodb --二进制日志文件及用于InnoDB或XtraDB表的二进制日志文件的当前position。
(4)xtrabackup_binary --备份中用到的xtrabackup的可执行文件;
(5)backup-my.cnf --备份命令用到的配置选项信息;
2.恢复
全备恢复
1、prepare
prepare,这个过程类似innodb的`crash recovery`,也可以理解为是“apply”的过程。
全备prepare的命令:`innobackupex --apply-log $basedir`。
在--apply-log的时候,可以指定`--use-memory`,增大其值加快速度,若不指定,默认值为`100MB`。
2、恢复过程
全备和增备都是这一个恢复命令,只需要加上--copy-back参数即可`innobackupex --copy-back $basedir`。
将`$basedir`的数据恢复到`datadir`,datadir无需指定,将会读取my.cnf获得。
默认是需要`datadir内为空的`(或者没有创建),如果要`强制写`,则需要加参数: `--force-non-empty-directories`
4.3.3.2 增量备份和恢复
两种增量备份方法
第一种,总是针对basedir做增量,这个方式恢复起来就特别简单了,只需要将最后一次的增量备份合并到全量备份里,就可以恢复了。
第二种,总是针对上一次的增量,做增量备份。这个方式的恢复,就要逐一合并了。
下面模拟第二种,对空间有要求。
1.创建全备
2.先模拟插入点数据,创建第一次增量
3.创建第一个增量备份
4.再插入点数据,创建再次增量
5.再创建一个增量备份
6.增量数据大小
7.增量恢复
8.模拟故障
9.恢复数据
4.3.2.3 备份及恢复过程总结
总结一下xtrabackup备份及恢复全过程:
1、备份操作,需要提供具有足够权限的MySQL用户,并且mysqld启动用户需要对datadir有rwx的权限。
2、prepare,将未提交的事务回滚,将已提交的事务写入数据文件。
3、停止mysqld服务
4、mv data/ data_bak_.../
5、copyback回去
6、修改权限新的datadir权限
7、启动服务
4.3.2.4 备份压缩
1.压缩对比
2.解压缩安装qpress
[qpress链接](http://www.quicklz.com/)
3.使用qpress解压缩所有文件
4.3.2.5 部分备份和还原
1.创建部分备份,部分备份有3个选项可以使用:
`--include`:设置正则表达式的格式,匹配的就备份
`--table-file`:在文件中指定要备份的表,然后通过这个选项传入文件
`--database`:指定数据库列表
副主题
2. 使用database方式innobackupex可以传递用空格隔开的数组,格式为:databasename[.tablename]
4.3.2.6 备份原理
1.`innobackupex` 在启动后,会先 fork 一个进程 ,启动 `xtrabackup`进程,然后就等待 `xtrabackup` 备份完 `ibd` 数据文件;
2.`xtrabackup`在备份 `InnoDB` 相关数据时,是有`2种线程`的,1种是 `redo` 拷贝线程,负责拷贝 `redo 文件`,1种是 `ibd 拷贝线程`,负责拷贝 `ibd 文件`;redo 拷贝线程只有一个,在 ibd 拷贝线程之前启动,在 ibd 线程结束后结束。`xtrabackup`进程开始执行后,先`启动 redo 拷贝线程`,从`最新的 checkpoint 点`开始顺序拷贝 redo 日志;然后再`启动 ibd 数据拷贝线程`,在`xtrabackup`拷贝 ibd 过程中,`innobackupex` 进程一直处于`等待状态`(等待文件被创建)。
3.`xtrabackup`拷贝完成idb后,通知 `innobackupex`(通过创建文件),同时自己进入`等待`(redo 线程仍然继续拷贝);
4.`innobackupex` 收到`xtrabackup`通知后,执行`FLUSH TABLES WITH READ LOCK` (FTWRL),取得`一致性位`点,然后开始备份`非 InnoDB 文件`(包括 frm、MYD、MYI、CSV、opt、par等)。拷贝非 InnoDB * 文件过程中,因为数据库处于`全局只读状态`,如果在业务的主库备份的话,要特别小心,`非InnoDB表`(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。
5.当 `innobackupex`拷贝完所有`非InnoDB表`文件后,通知 `xtrabackup`(通过删文件) ,同时自己进入等待(等待另一个文件被创建);
6.`xtrabackup` 收到`innobackupex`备份完非 InnoDB 通知后,就停止 `redo 拷贝线程`,然后通知`innobackupex redo log 拷贝完成`(通过创建文件);
7.`innobackupex` 收到 redo 备份完成通知后,就开始解锁,执行 `UNLOCK TABLES`;
8.最后 `innobackupex` 和 `xtrabackup` 进程各自完成收尾工作,如资源的释放、写备份元数据信息等,`innobackupex` 等待 `xtrabackup 子进程`结束后退出。
补充
1.通过以上流程图,可以发现一个重要的线索,如果进行物理备份,是不会备份binlog。
2.对于5.1 & 5.5,用xtrabackup for 5.1 or 5.5 在`innodb_flush_log_at_trx_commit=1`情况下备份数据是一致的
3.对于5.6,用xtrabackup for 5.1 or 5.5,即便如果`innodb_flush_log_at_trx_commit=1`,没有sync,有可能会丢失事务
4.对于5.6,用xtrabackup for 5.6,不会丢失事务。
4.4. mydumper
4.4.1 mydumper介绍
mydumper主要特性:
事务性和非事务性表一致的快照
快速的文件压缩
支持导出binlog,默认不支持备份binlog,需要在编译时添加`-DWITH_BINLOG=ON`参数
支持将备份文件切块
多线程备份和多线程恢复,支持对一张表进行多个线程备份
备份时对MyISAM表施加FTWRL(FLUSH TABLES WITH READ LOCK),会阻塞DML语句
以守护进程的工作方式,定时快照和连续二进制日志
支持备份指定库和表
4.4.2 mydumper和myloader原理
4.4.2.1 mydumper备份原理
主要步骤概括
a、连接目标数据库;
b、通过show processlist来判断是否有长查询,根据参数long-query-guard和kill-long-queries决定退出或杀掉长查询;
c、锁定myisam表,flush tables with read lock;针对innodb table开启事务,start transaction;
d、创建worker子线程,缺省为4个;
e、确定候选表,根据类别分别插入innodb_table,non_innodb_table以及table_schemas链表(表结构);
f、将候选表通过g_async_queue_push加入任务队列(队列最后元素是thread shutdown),由worker子线程从队列中读取表信息并执行数据导出
g、执行unlock tables,处理完myisam表后立即解锁,以减少锁定时间;
h、等待worker退出;。
备份文件相关信息
a、所有的备份文件在一个目录中,未指定时为当前目录, 且自动生成备份日期时间文件夹,如export-20150703-145806
b、目录中包含一个 metadata 文件,该文件记录了备份时间点的二进制日志文件名,日志的写入位置
c、如果是在从库进行备份,还会记录备份时同步至主库的二进制日志文件及写入位置
d、每个表有两个备份文件:database.table-schema.sql 表结构文件,database.table.sql 表数据文件
e、如果对表文件分片,将生成多个备份数据文件,可以指定行数或指定大小分片
4.4.2.1 myloader还原原理
如上图所示,mydumper的回复可分为三个阶段:
a、首先由myloader主线程完成建库建表,依次将备份目录下dumpdb-schema-create.sql和dumpdb.dumptable-schema.sql中的建库和建表语句应用到目标数据库实例中;
b、接着myloader主线程会生成多个工作线程,由这些工作线程将所有dumpdb.dumptable.*.sql文件中的记录导入到对应表中,这个阶段是并行的,并行粒度为文件,工作线程完成所有dumpdb.dumptable.*.sql文件数据导入后销毁;
C、最后主线程将dumpdb-schema-post.sql、dumpdb.dumptable-schema-view.sql和dumpdb.dumptable-schema-triggers.sql文件中存在的schema导入对应数据库和表中
4.4.3 mydumper安装
4.4.4 mydumper和myloader演示
mydumper常用参数
1. -t , --threads 使用的线程数,默认是4个
2. -c , --compress 启用压缩
3. -B , --database 对某个库进行备份
4. -T , --tables-list 对某个表进行备份
5. -r , --rows 将指定的行数拆分到chunks中去
6. -G , --triggers 备份触发器
7. -R , --routines 备份存储过程
8. -v , --verbose 更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2
9. -o , --outputdir 备份文件目录
还原
myloader 常用参数
1. -t , --threads 使用的线程数,默认是4个
2. -q , --queries-per-transaction 每个事务的query数量, 默认100
3. -B , --database 指定需要还原的数据库
4. -s , --source-db 还原的数据库
5. -d , --directory 备份文件所在的目录
6. -v , --verbose 更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2
mydumper支持一张表多个线程以chunk的方式批量导出,参数-r:试图用行块来分割表,该参数关闭--chunk-filesize参数。
4.4.5 mydumper和myloader详细参数和用法
mydumper参数
2.myloader参数
3.命令用法
五. 备份周期
一周一个全备,其余每天进行增量备份,备份时间为业务低峰期
六、基于mysqldump备份脚本
1.功能
脚本下载地址
[github](https://github.com/gczheng/bakmysql)
场景一:每天执行一次全量备份.
场景二:每周日执行一次全量备份,然后每天3点执行增量备份.
应用场景:
增量备份在周一到周六凌晨3点,会使用mysqlbinlog 导出sql并使用gzip压缩到指定目录
mysqlbinlog -vv binlog.000044 binlog.000045 binlog.000046 ..... > |gzip > $INCR_BACKUP_DIR/incr.sql.gz
全量备份则使用mysqldump将所有的数据库导出,每周日凌晨3点执行,并会删除N天之前的目录和文件。参数如下:
MYSQLDUMP_OPTION=' --single-transaction --master-data=2 --flush-logs --set-gtid-purged=AUTO --databases'
删除命令(find $BASE_DIR -mtime +$DELETE_DAYS -type d -name "full*" -exec rm -rf {} ;)
2.使用方法
脚本需修改参数:
备份基础目录以/mybak为例,目录的树形结构如下:
2.1 全备
备份命令
./backup_mysql full
计划任务
crontab -e
每天做一次全备,凌晨3点进行全量备份,备份频率可根据项目情况自行调整。
0 3 * * * /bin/sh /scripts/bak_mysql_all.sh full >/dev/null 2>&1
2.2 增量
备份命令
./backup_mysql incr
计划任务
crontab -e
每个小时(除3点外)进行binglog增量备份,备份频率可根据项目情况自行调整。
0 0-2,4-23 * * * /bin/sh /scripts/bak_mysql_all.sh incr >/dev/null 2>&1
使用参考如下:
3.执行备份
3.1 全备执行过程
3.2 全备执行结果
3.3 增备执行结果
执行增量备份之前进行如下操作:
3.4 增备执行结果
3.5 public_position文件是空时,执行增备
如果public_position文件是空的,就会从新执行全备
16.高可用
一、简单复制
一. 复制
常见数据库复制模式对比
1.1 基于binlog刷新和恢复
1.1.1 binlog格式
Table Map : 记录了一些元数据,比如列的类型等等
如果没有这个记录,就不知道第一列(@1)是哪个列,是什么类型等等信息
Rotate :binlog日志分割
Query:查询
Update/Write/Delete Rows:对行的操作
1.1.2 binlog恢复
注意,如果你有 `多个binlog文件`想要恢复, 不要一个一个`顺序恢复`
基于position
基于datetime
1.2 MySQL主从复制架构
主服务器
在 `MySQL 5.7`中, `prepare log` 部分的日志也是 `组提交` 的
`prepare log` 和 `commit log` 写 `redo file`(iblogfile1、iblogfile2)
`binlog` 写 `binlig.00000X` 文件
MySQL Dump Thread 把 `binlog` 推送到远程的Slave服务器
每一个Slave,就会对应有一个`dump线程`
同时,在MySQL主机上还有一个 `Master Thread` 在`每隔1秒`从`redo log buffer中`写入redo file
从服务器
IO Thread 负责 `接收` Dump线程发送过来的 `binlog` ,并且记录到本地的 `relay log`
接受的 `单位` 是 `event`
SQL Thread/Coordinator Thread 负责将relay log中的日志 `回放` 到从机
回放的 `单位` 也是 `event`
有了多线程以后,`coordinator线程`负责`任务指派`,`work thread`负责`回放`
在 MySQL5.6 中的多线程回放是 `基于库` 的, 单个库还是单线程
在 MySQL5.7 中的多线程是在 `主上如何并行执行的` , `从机上也是如何并行回放的`
master-info.log 存放了 `接收` 到的binlog的 `位置` ( event的位置 )
relay-info.log 存放了 `回放` 到的relay log的 `位置` ( event的位置 )
二. 可传输表空间
2.1. innodb 独立表空间导入和导出
操作步骤:
目的服务器:ALTER TABLE t DISCARD TABLESPACE;
源服务器:FLUSH TABLES t FOR EXPORT;
源服务器:拷贝t.ibd,t.cfg文件到目的服务器
源服务器:UNLOCK TABLES;
目的服务器:ALTER TABLE t IMPORT TABLESPACE;
2.2. 演示
1、源服务器查看迁移表状态
源服务器
2、在目标服务器上创建表空间
目标服务器
3、源服务器导出表空间
源服务器
4、在目标服务器上修改 cfg文件和ibd文件的 权限
目标服务器
三 复制环境搭建
3.1. 创建一个复制用户
master服务器
slave服务器
3.2. 备份数据
3.2.1. 准备测试数据
master服务器
3.2.2. 导出数据
3.3. 还原数据
3.4. CHANGE MASTER
3.4.1. 查看master status
3.4.2. change master
slave服务器
3.4.3. 添加并行复制
slave服务器
slave节点
当前演示时的relay-log文件是 binlog.000029
3.5. 复制搭建总结
3.6. 搭建真正的高可靠复制环境
3.6.1. 重要的参数
Master
binlog-do-db = #需要复制的库
binlog-ignore-db = #需要被忽略的库
max_binlog_size = 2048M #默认为1024M
binlog_format = ROW #必须为ROW
transaction-isolation = READ-COMMITTED
expire_logs_days = 7 # binlog保留多少天,看公司计划安排
server-id = 8888 #必须和所有从机不一样,且从机之间也不一样
binlog_cache_size = # binlog缓存的大小,设置时要当心
sync_binlog = 1 #必须设置为1,默认为0
innodb_flush_log_at_trx_commit = 1 #提交事物的时候刷新日志
innodb_support_xa = 1 #确保事务日志写入bin-log 的顺序与是事务的time-line是一致的
Slave
log_slave_updates #将SQL线程回放的数据写入到从机的binlog中去(用于级联复制)
replicate-do-db = #需要复制的库
replicate-ignore-db = #需要忽略的库
replicate-do-table = #需要复制的表
replicate-ignore-table =需要忽略的表
server-id = 8899 #必须在一个复制集群环境中全局唯一
relay-log-recovery = 1 #I/O thread crash safe – IO线程安全
relay-log-info-repository = TABLE # SQL thread crash safe – SQL线程安全
master_info_repository = TABLE
read_only = 1
3.6.2. SQL线程高可靠问题
如果将`relay_log_info_repository` 设置为`FILE` ,MySQL会把回放信息记录在一个 `relay-info.log` 的文件中,其中包含SQL线程 `回放到的Relay_log_name`和`Relay_log_pos` ,以及对应的`Master`的`Master_log_name`和`Master_log_pos`
SQL线程回放event
将回放到的binlog的`文件名` 和`位置`写到`relay-info.log`文件
参数`sync_relay_log_info = 10000` (fsync)代表每回放`10000`个event,`写一次`relay-info.log
如果该参数设置为`1`,则表示`每回放一个event就写一次relay-info.log`,那写入代价很大,且性能很差
设置为1后,即使性能上可以接受,还是会丢最有一次的操作,恢复起来后还是有1062的错误(重复执行event)
1. Slave的库中 `存在数据2和数据3`
2. Slave读取relay-info.log中的 Relay_log_name和Relay_log_pos ,此时记录的是 `回放到数据1的位置`
3. Slave `从数据1开始回放` ,继续 `插入数据2和数据3`
4. 但是,此时的数据库中 `存在数据2和数据3` ,于是发生了 `1062` 的错误(重复记录)
3.6.3. I/O线程高可用
解决问题的方法:
设置参数 `relay-log-recover = 1` ,该参数表示 `当前接收到的relay-log全部删除` ,然后从SQL线程回放到的位置 `重新拉取`(SQL线程通过配置后是可靠的)
所以说,真正的MySQL复制的高可靠是从 5.6 版本开始的,通过设置
relay-log-recover = 1
relay_log_info_repository = TABLE
master_info_repository = TABLE
3.6.4. master_info_repository设置
3.6.5. read_only与super_read_only
3.7. mysqlreplicate 搭建主从复制
3.7.1. 测试
1. 搭建一个备机 node3,并初始化实例;
2. node3 上新建一个用户 'gcdb'@'%' (%可以换成内网网段);
3. 然后在 node3 或 node1 (或者其他任何可以连接到Master/Slave的机器上)执行如下命令
二、高级复制
二. 并行复制(Multi-Threaded Slave)
2.1. MTS介绍
MySQL的并行复制基于组提交:
slave-parallel-type 参数
`DATABASE` 基于`库级别的并行复制`,如果只有一个库,就还是串行(为了兼容5.6)。
`LOGICAL_CLOCK` 基于`逻辑时钟`,主上怎么并行执行,从上也是怎么并行回放的。
slave-parallel-workers `并行复制的线程数`,一般设置为一个组内提交的事务数,线上设置为32足够了
slave_preserve_commit_order `Slave上commit`的顺序`保持一致`,必须为1,否则可能会有GAP锁产生
2.2. 动态调整复制线程数
三. GTID
3.1. GTID的介绍
1.Global Transaction Id entifier -- 全局事物ID
2.GTID = Server_UUID + Transaction_ID
Server_UUID 是全局唯一的
Transaction_ID 是自增的
3.GTID 的作用是替代 Filename + Position
3.2. GTID的意义
未使用GTID
当 `Master宕机` 后,一个 `Slave` 被`选举提升`为`New Master`,如果需要`重建复制关系`,就需要把另外`两个Slave`的 `CHANGE MASTER` 指向 `New Master` ;
那问题来了,原来Slave是指向 `Master` 的 `Filename_M + Position_M` 的位置,现在要指向 `New Master` 上新的 `Filename_N + Position_N` 的位置,由于`基于二进制日志复制` ,定位两个位置步骤繁琐; 此时两个Slave要继续`重建复制关系(CHANGE MASTER)`会比较麻烦。
使用GTID
和上面一样的场景,`选举机制`提升为`New Master的GTID` 执行到最新事务, `两个Slave`需要重新指向 `New Master` ,由于 `使用了GTID` ,目前 `Slave-A` 获取到的事务对应GTID为`GTID_A` , `Slave-B` 获取到的事务对应GTID为`GTID_B`;
此时 `New Master` 上GTID是存在 `GTID_A 和 GTID_B`,那两个Slave就可以直接使用 `GTID_A 和 GTID_B` 这两个GTID,通过指向 `New Master`接着重建复制;
3.3. GTID的配置
注意:
1.MySQL5.6 必须开启参数 `log_slave_updates` (5.6版本的限制)
2.MySQL5.6 升级到gtid模式需要`停机重启`
3.MySQL5.7 版本开始可以不开启 `log_slave_updates`
4.MySQL5.7.6 版本开始可以`在线升级`成`gtid模式`
3.4. 基于GTID的复制
3.4.1. 配置基于GTID的复制
1.master节点的配置文件加入
2.slave 节点加入
3.查看metadata信息
3.4.2. 跳过GTIDs
Slave节点
3.4.3. CHANGE MASTER
Slave节点
3.4.4. 复制完成
master节点
slave节点
3.5. GTID 与 Filename-Pos的对应
3.6. GTID复制出错的处理
3.6.1. 演示
1.在从机上插入一条记录(模拟误操作)
slave节点
2.在主机上插入同样的记录
master节点
3.查看 Slave上的状态
slave节点
3.6.2. 处理复制错误
1.将Slave上的 `gtid_next` 指向 `执行失败` 的那个 `gtid`
这里执行失败的 gtid 报错信息中已经给出: '9dc847d8-bf72-11e7-9ec4-000c2998e4f1:73-74'
如果不看报错信息,可以看 Retrieved_Gtid_Set 和 Executed_Gtid_Set 的对比结果
2.执行一个空的事物,即`begin;commit`;
这样就把 `失败的gtid` 对应到了一个 `空的事务` 上,这个步骤即为 “跳过” 的意思
3.将 `gtid_next` 设置(还原)为 `automatic`
slave节点
3.6.3. 测试复制
1.Master端插入一个测试数据
master节点*
2.查看Slave2上的数据是否同步
slave节点*
3.7. 其他注意事项
1. reset slave all使用该命令时 `不会清空数据` ,仅仅是清空 `show slave status\G`里面的信息,所以在使用该命令之前,请 `先记录show slave status\G`的信息。
2. GTID在开启GTID后,不能在一个事物中使用`创建临时表的语句`,需要使得`autocommit=1;` 才可以。在开启GTID后,不能使用 `create table select ...`的语法来创建表了,因为这其实是`多个事物`了,GTID没法对应
一.半同步和无损复制
从 MySQL5.5 开始,MySQL推出了`semi-sync replication (半同步复制)`
至少有一个Slave节点收到binlog后再返回( IO线程接收到即可 )
减少数据丢失风险
不能完全避免数据丢失
超时后,切换回异步复制
从 MySQL5.7.2 开始,MySQL推出了`lossless semi-sync replication (无损复制)`
二进制日志(binlog)先写远程( IO线程接收到即可 )
可保证数据完全不丢失
1.1. loss less / semi-sync replication插件安装
1、手工安装
2、写入配置文件
1.2. semi-sync replication
1.3. loss less semi-sync replication
1.4. 半同步复制与无损复制的对比
ACK的时间点不同
`半同步复制`在`InnoDB层`的`Commit Log后`等待ACK,主从切换会有数据`丢失`风险。
`无损复制`在`MySQL Server层`的`Write binlog后`等待ACK,主从切换会有数据`变多`风险。
主从数据一致性
`半同步复制`意味着在Master节点上,这个刚刚提交的事务对数据库的修改,对其他事务是可见的。因此,如果在等待Slave ACK的时候crash了,那么会对其他事务出现`幻读`,`数据丢失`。
`无损复制`在write binlog完成后,就传输binlog,但还没有去写commit log,意味着当前这个事务对数据库的修改,其他事务也是`不可见的`。因此,不会出现幻读,数据丢失风险。
因此5.7.2引入了`无损复制(after_sync)模式`,带来的主要收益是解决 `after_commit`导致的`master crash`后`数据丢失问题`,因此在引入`after_sync模式`后,所有提交的数据`已被复制`,故障切换时数据一致性将得到提升。
1.5. 演示无损/半同步复制
master server
slave server
master server
slave server
master server
1.6. 两种复制方式的性能
蓝色的 `Normal Slave` 是 `异步复制`
性能很好,但是随着并发数的增长,性能有所下降
绿色的 `Enhanced mysqlbinlog` 是 `无损复制`
随着并发数的增长,性能几乎是线性增长的,在高并发下,性能会优于异步复制
紫色的 `Normal Semi Slave` 是 半同步复制
性能较低
1. `等待ACK回包`问题上,其实两种复制的开销是一样的,没有区别,都是网络的等待开销。
2. `无损复制`由于在 `write binlog` (commit 的第二步)后,需要等待ACK,后续的`事务无法提交`,这样就 `堆积` 了`N多个需要落盘的事务`(半同步复制由于已经提交了事务,没有堆积事务的效果),通过 `组提交` 机制`一次 fsync的多个事务`(半同步复制也有组提交,只是一次 `fsync` 的事务数没那么多), 相当于提高了`I/O性能` ;所以`线程(事务)越多,效果越明显`,以至于有上图中超过异步复制的效果。(无损复制的组提交比例比原版的高3~4倍)
1.7. rpl_semi_sync_master_wait_for_slave_count
四. 级联复制
4.1. 级联复制的介绍
4.2. 级联复制的场景
4.2.1. 跨机房的复制
4.2.2. 库的拆分
4.3. 级联复制测试
`Master --> Slave A --> Slave C` 是级联复制,Master到Slave A 和 Master到Slave B 之前已部署完,`直接做 Slave A到Slave C 的级联复制`
1、在Master端新建一个DB名为 `mts库` ,用于在 Slave3 上测试参数 `replicate_do_db`。
master节点
2、在Slave C上增加如下参数
3、确认在slave A 已添加log_slave_updates,并建立通用账号'repl'@'192.168.88.%'
4、change master
Slave C 节点
五.多源复制
5.1. 多源复制的介绍
5.2. 多源复制的演示
副主题
1. master准备数据
master A 节点
2.mysqldump 备份导出导入
Slave 节点
3 change master
Slave 节点
验证
master A 节点
master B 节点
slave A 节点
5.3.使用场景
如果不做额外的配置,是 `会有错误` 的;
如果配置了 `slave_skip_errors = ddl_exist_errors` ,且 `没有重复数据` 话,复制关系还是正常的。这种操作可以起到 `数据聚合`的效果。将分库分表后的数据聚合在一起,以供其他应用进行分析(前提是数据不能有重复)。但是最合适的场景还是将`不同的库`进行复制。
中间件的unique key
三、MHA
一、MHA 简介
1、提供的功能
自动化监控并执行自动故障转移,最小化宕机时间,通常为10-30s
9-12秒内检测到master故障,
7-10秒选择关闭master避免出现裂脑,
几秒钟内,将差异中继日志(relay log)应用到新的master上
交互式主服务器故障转移
MHA可以被定义成手动地实现故障转移,而不必去理会master的状态,即不监控master状态,确认故障发生后可通过MHA手动切换
非交互式主服务器故障转移
即不监控Master状态,但是发生故障后可通过MHA实现自动转移。
在线切换Master到另外一台服务器
场景:RAID卡/内存故障、硬件升级维护、升级版本等维护,需要手动切换主库的情况
MHA能够在0.5-2秒内实现切换,0.5-2秒的写阻塞通常是可接受的,所以你甚至能在非维护期间就在线切换master。诸如升级到高版本,升级到更快的服务器之类的工作,将会变得更容易。
2、MHA的优点
Perl语言开发的开源脚本,容易二次开发
自动化监控并执行自动故障转移,最小化宕机时间
自动补齐数据,维护数据一致性
切换过程中支持调用其他脚本的接口
支持在线切换master(仅阻塞写入)
多个集群集中监控管理
支持基于GTID的复制模式
部署简单,对现有架构无需复杂更改及配置
服务器器无性能损失(心跳缺省为每3s)
支持任意存储引擎
无需增加大量备用或闲置服务器
3、MHA的缺点:
需要编写脚本或利用第三方工具来实现VIP的配置
需要基于SSH免认证配置,存在一定的安全隐患
二、MHA 原理
1、架构图
2、MHA 恢复原理
三、环境
四、搭建主从
1、配置主从
2、 配置 lossless semi-sync replication (无损复制)
master (主备)
slave(Slave A )配置
添加hosts
五、 安装MHA
1、下载包和安装依赖包
2、安装MHA manager
在所有的 MySQL上安装 `Node 节点`;在 MHA 的管理节点安装`manager 节点`。
3、安装MHA Node
4、 配置免秘钥
mha管理节点:
mysql节点各自生成公私钥,并将公钥拷贝给其他mysql节点
测试ssh是否免密码登录
5、MHA配置
1、创建和修改配置文件
在manager节点上创建配置文件(app1.cnf)
在manager节点创建全局配置文件(masterha_default.cnf)
在manager节点上修改故障转移脚本(master_ip_failover)
2、 检查 SSH/复制/MHA Manager 的配置
检查SSH 情况:masterha_check_ssh --conf=/etc/masterha/app1.cnf
检查复制情况:masterha_check_repl --conf=/etc/masterha/app1.cnf
检查MHA 状态:masterha_check_status --conf=/etc/masterha/app1.cnf
3、验证(MHA Manager 配置)
session A
session B
session A
session B
六、部署负载均衡
1、部署 keepalived 和 lvs
2、创建检查从库脚本(check_slave.py)
两台都需要创建脚本
3、修改配置文件(keepalived.conf)
redis01主机修改keepalived.conf
redis02主机修改keepalived.conf
4、绑定IP
master 主备节点绑定写vip ,222网段的ens256网卡来绑定192.168.222.99
从库主备节点(node03,node04)绑定读vip ,lo网卡来绑定192.168.222.100
5、验证绑定情况
1.验证写vip
在manager 节点验证写vip,写采用vip迁移模式,单节点
stop master (node01)
查看管理日志
上面日志显示master成功切换到node02
验证写vip是否切换到node02
new master
2.验证读vip
在manager 节点验证读vip
在redis01 查看lvs (node03和node04均摊)
node04 停止mysql
在redis01 查看lvs,node04 被剔除
只剩下node03在负载
启动 node04 mysql
在redis01 查看lvs (node04成功加入)
读vip (node03和node04均摊)
四、Cetus中间件&MHA
六 总结
1 、目录的树形结构
2、mysql客户端问题
3、master_ip_failover failed
4、多网卡cetus配置问题
5、重新构建MHA
删除mha.failover.complete文件
mha.cnf 把主机信息重新添加
masterha_default.cnf里面修改 masterha_secondary_check -s 连接测试
五 MHA和Cetu联动切换
1、添加mail告警功能
修改配置
启动sendmail测试
修改sendmail脚本
2、切换主库
1、node02 会话
2、node05 会话
session B
session A
session B切换后Cetus中查看读写状态
session A切换后mha.cnf 配置里面原主库会被清除掉
3 、邮件告警
四、MHA和cetus配置
1、创建和修改配置文件
在manager节点上创建cetus配置文件(cetus.cnf)
在manager节点上创建cetus的user和proxy.配置文件(users.json和proxy.conf)
在manager节点创建全局配置文件(masterha_default.cnf)
在manager节点上创建配置文件(mha01.cnf)
在manager节点上修改故障转移脚本(master_ip_failover)
2、检查 SSH/复制/MHA Manager 的配置
检查SSH 情况:masterha_check_ssh --conf=/etc/mha.cnf
检查复制情况:masterha_check_repl --conf=/etc/mha.cnf
检查MHA 状态:masterha_check_status --conf=/etc/mha.cnf
检查masterha_secondary_check脚本中mysql客户端安装位置
3、启动MHA manager
session A
session B
session A
session B
4、启动cetus
启动前保证启动配置文件的权限为660
守护进程模式启动Cetus
session A
查看Cetus状态
session B
5、验证cetus读写分离功能
session A
session B
session A
session B
验证简单读写
三、安装MHA和Cetus
1、下载包和安装依赖包
2、安装MHA Node
3、安装MHA manager
在所有的 MySQL上安装 `Node 节点`;在 MHA 的管理节点安装`manager 节点`。
4、安装Cetus
1.安装说明
创建编译目录:在源码主目录下创建独立的目录build,并转到该目录下
编译:利用cmake进行编译,指令如下
安装:执行make install进行安装
配置:Cetus运行前还需要编辑配置文件
启动:Cetus可以利用bin/cetus启动
2.安装实施
5、cetus替换mha部分文件
二、搭建主从
1、配置主从
搭建基于GTID主从复制环境
若开启主从延迟检测需创建库proxy_heart_beat和表tb_heartbeat
创建用户和密码(默认用户对tb_heartbeat有读写权限)
确认Cetus可以远程登录MySQL
2、配置 hosts
添加hosts
3、配置免秘钥
mha管理节点:
mysql节点各自生成公私钥,并将公钥拷贝给其他mysql节点
测试ssh是否免密码登录
一、主机环境
虚拟机配置
主机信息
借用官方架构图
五、Cetus sharding
一、主机环境
虚拟机配置
主机信息
借用官方架构图
二、搭建环境
1、准备环境
5.7.17以上版本(分布式事务功能需要)
数据库设计(即分库,根据业务将数据对象分成若干组)
创建用户和密码
确认Cetus可以远程登录MySQL
根据MySQL后端信息配置users.json、sharding.json和shard.conf(variables.json可选配),具体配置说明详见[Cetus 分库(sharding)配置文件说明](https://github.com/Lede-Inc/cetus/blob/master/doc/cetus-shard-profile.md)
[Github]https://github.com/jeanron100/mysql_mgr_test
搭建5个实例端口分别为33061~33065
创建测试库
三、Cetus安装
1、下载包和安装依赖包
2、Cetus安装
1.安装说明
创建编译目录:在源码主目录下创建独立的目录build,并转到该目录下
编译:利用cmake进行编译,指令如下
安装:执行make install进行安装
配置:Cetus运行前还需要编辑配置文件
启动:Cetus可以利用bin/cetus启动
2.安装实施
四、Cetus配置
1、创建和修改配置文件
在manager节点上创建cetus的user和proxy.配置文件(users.json和proxy.conf)
2、启动cetus
启动前保证启动配置文件的权限为660
守护进程模式启动Cetus
session A
session B
session C
session D
3、导入数据
分别创建库和表
先导入到employees库,然后备份出来再分批导入到employees_hash和employees_range中cetus不支持load data infile,不支持lock tables语法,导入employees具体请看README.md
4、验证cetus分库功能
Cetus主机
mysql主机(多实例)
五、Cetus测试各种限制
1、JOIN的使用限制
2、DISTINCT的限制
3、CASE WHEN/IF 的限制
4、中文列名的限制
5、查询业务的限制
六、基于Consul和MGR的MySQL高可用架构
一、Consul
1、Consul简介
1. 多数据中心服务发现(DNS + HTTP)
2. 支持健康检查.
3. 单数据中心微服务
4. 内置Web UI,用于编辑K/V和查看健康检查状态
5. 支持热配置,不用重启服务
6. 支持编排任务
1. Consul Cluster由部署和运行了`Consul Agent`的节点组成。 在Cluster中有两种角色:`Server`和 `Client`。
2. Server和Client的角色和Consul Cluster上运行的应用服务无关, 是基于Consul层面的一种角色划分.
3. Consul Server: 用于维护Consul Cluster的状态信息, 实现数据一致性, 响应RPC请求。> 官方建议是: 至少要运行3个或者3个以上的Consul Server。 多个server之中需要选举一个leader, 这个选举过程Consul基于Raft协议实现. 多个Server节点上的Consul数据信息保持强一致性。 在局域网内与本地客户端通讯,通过广域网与其他数据中心通讯。
4. Consul Client: 只维护自身的状态, 并将HTTP和DNS接口请求转发给服务端。
5. Consul 支持多数据中心, 多个数据中心要求每个数据中心都要安装一组Consul cluster,多个数据中心间基于gossip protocol协议来通讯, 使用`Raft算法`实现一致性
2、准备环境
node05、node06部署成单机多实例MGR,端口分别(33061~33065)
3、Consul 安装
步骤如下:
目录结构
4、Consul配置文件
consul server 配置文件`advertise_addr`(主机IP)和`node_name`(主机名),(node09、node10、node11)三个主机修改对应信息`"domain":"gczheng"`, 所以后缀是servers.gczheng
consul client 配置文件`bind_addr`修改为成对应的主机ip(node01、node02、node03、node04、node05、node06、node12、audit01)
proxysql 配置文件
mysql_mgr_write_3306.json
mysql_mgr_read_3306.json
5、Consul 服务检查脚本
check_mysql_mgr_master.sh
check_mysql_mgr_slave.sh
proxysql_check.sh
6、Consul启动
consul client启动(node01、node02、node03、node04、node05、node06)
二、MGR搭建
1、MGR配置
直接使用杨建荣的快速搭建mgr脚本,配置多实例(node05)(一主四从)
[脚本地址:Github](https://github.com/jeanron100/mysql_mgr_test)
手动搭建MGR(node01、node02、node03、node04)(多主模式)
请自行搭建
MGR默认账号
`GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%' IDENTIFIED BY 'rpl_pass';`
`GRANT ALL ON *.* TO 'gcdb'@'%' IDENTIFIED BY 'iforgot';`
2、MGR查看
三 、Consul测试
1、MGR(多主模式)+ Consul模式
1.1 、Consul UI界面
consul
mysql_3306_r
mysql_3306_w
1.2、Consul 检查DNS解析
域名转发
1.3、切换测试
1、关闭node04节点
查看mgr状态
查看consul 状态解析域名(mysql_3306_w)
Consul 界面查看
2、恢复node04节点
mysql_3306_w服务
查看consul 状态
2、MGR(单主模式)+ Consul模式 + PorxySQL
2.1、PorxySQL配置
安装配置步骤
安装请自行参考官方文档[安装指南](https://github.com/sysown/proxysql/wiki)
修改proxysql.cnf 配置文件,配置后端mysql连接
修改proxysql.json配置文件
启动consul服务读取proxysql.json配置
配置域名转发(访问proxysql的客户端),指向consul服务器
配置后端mysql登录管理端(mysql -P6032 -h127.0.0.1 -uadmin -padmin)配置后端mysql(audit01,node12)
确认配置没问题,两个主机启动consul
2.2 、查看页面
2.3、检查DNS解析
2.4、切换测试
1、测试proxysql负载均衡
2、测试proxysql宕机或者roxysql 服务不可用
node12 ifdown ens224网口
audit日志显示如下
域名解析
ping
node12 ifup ens224网口
域名解析等待5s时间,域名解析到182
pin
3、注意事项
恢复节点:
域名解析:
17.Online DDL
原生ddl
pt-online-schema-change
gh-ost
MySQL总结问答
1.MySQL版本类问题
MySQL版本类常见问题
你如何决定是否对数据库版本进行升级?
升级前需要考虑什么
升级可以给业务带来的益处
是否可以解决业务上某一个方面的痛点
JSON全复制还是修改部分复制
多线程复制
多源复制
增加GTID
HASH索引
是否可以解决运维上某一个方面的痛点
增加PS库功能
增加SYS库功能
Online DDL
MGR高可用
升级可能对业务带来的影响
对原业务程序的支持是否有影响
JDBC版本的支持
python版本的支持
SQL_MODE 各版本版本不同
对原业务程序的性能是否有影响
PS库对性能的影响
MySQL查询优化器的变化
索引失效
数据库升级方案的制定
评估受影响的业务系统
升级系统对应的业务系统
升级JDBC/PYTHON的版本
升级时间
升级后的数据库环境检查
系统表差异
配置参数无效
权限是否正确
升级后业务的检查
升级失败的回滚方案
升级失败回滚的步骤
方案1、安装回老版本,恢复备份数据
方案2、滚动升级,保留一个从库,提升老版本从库为主库
回滚后的数据库环境检查
回滚后的业务检查
如何对MySQL进行升级
数据库升级的步骤
主从同步滚动升级
对待升级数据库进行全备
升级slave服务器版本
对周边工具进行测试
高可用手动进行主从切换
升级master服务器版本
升级完成对业务检查
MySQL主备切换流程
准备工作
备库硬件
磁盘健康检查
RAID卡充放电
备库OS
crontab
crontab -l
检查各个crontab脚本的日志信息
确认crontab的修改时间(备份前还是备份后?)
硬盘空间
df -lh
ioutil
iostat -dx 1
备库MySQL
alter.log
my.cnf
buffer pool size
log_slave_updates
server-id检查
binlog
清除binlog的间隔
binlog文件数
主备脚本文件
mydumper
文件个数一致
应用
App
Search
DW
验证
功能测试
App程序日志
留意新主库的性能情况
QPS+TPS
Buffer Pool Hit
Load
alter.log
切换过程
主库
备库
主备完全同步
Why
机房切换
主库机器异常
容灾演习
App是如何做的
动态数据源切换
人工更改IP地址
DB需要保证状态是健康可靠的
MySQL版本选择
MySQL8新特性
InnoDB功能
innodb select for update跳过锁等待
Online DDL原子化
Undo空间自动回收
新增innodb_dedicated_server参数
redo & undo 日志加密
服务器类功能
MyISAM系统表全部换成InnoDB表
增加角色管理
增加资源组
支持不可见索引
新增降序索引
支持直方图
窗口函数
JSON特性增强
增加SET_VAR语法
日志分类更详细
group by不再隐式排序
参数修改持久化
自增变量持久化
默认字符集由latin1变为utf8mb4
MySQL,Percona,MariaDB之间的区别和优缺点
2.用户管理类问题
用户管理类常见问题
如何在给定场景下来为某用户授权?
如何定义MySQL数据库账号
MySQL常用的用户权限
如何为用户授权
用户管理
创建用户
设置密码
修改用户
删除用户
权限管理
授予权限
收回权限
查看权限
如何保证数据库帐号的安全?
数据库用户管理流程规范
最小权限原则
密码强度原则
密码过期原则
限制历史密码重用原则
如何迁移数据库帐号?
导出用户建立授权语句
pt-show-grants
exp_grants.sh
3.服务器配置类问题
请分析一个Group By语句的异常原因
如何比较系统运行配置和配置文件中的配置是否一致?
pt-config-diff对比
举几个MySQL中关键性能参数
4.MySQL日志类问题
日志常见问题
常见日志有那些?
错误日志log-error
默认是关闭的,记录严重的警告和错误信息,每次启动和关闭的详细信息等。
二进制日志binary log
主从复制及备份恢复(了解)
慢查询日志slow log
是什么
配置版
怎么玩
说明
查看是否开启及如何开启
默认
SHOW VARIABLES LIKE '%slow_query_log%';
开启
set global slow_query_log=1;
那么开启了慢查询日志后,什么样的SQL才会记录到慢查询日志里面呢?
Case
查看当前多少秒算慢
SHOW VARIABLES LIKE 'long_query_time%';
设置慢的阙值时间
为什么设置后看不出变化?
需要重新连接或新开一个会话才能看到修改值。 SHOW VARIABLES LIKE 'long_query_time%';
或者通过set session long_query_time=1来改变当前session变量;
记录慢SQL并后续分析
查询当前系统中有多少条慢查询记录
日志分析工具MySQLdumpslow
查看mysqldumpslow的帮助信息
s: 是表示按照何种方式排序;
c: 访问次数
l: 锁定时间
r: 返回记录
t: 查询行数
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
t:即为返回前面多少条的数据;
g:后边搭配一个正则匹配模式,大小写不敏感的;
mysqldumpslow常用命令
通用日志general log
编码启用
配置启用
中继日志 relay log
我们在什么情况下使用这些日志?
错误日志
分析排查mysql运行错误
启动/重启/关闭
记录未授权的访问信息
通用日志
分析客户端发送到mysql的实际请求
慢查询日志
将执行成功的并符合条件的查询记录到日志中
查找需要优化的SQL
二进制日志
记录所有对数据库的数据修改
基于时间点的日志备份和恢复
主从复制
统计表的访问频次
中继日志
临时记录从主库同步过来的二进制日志
如何通过日志来审计用户活动?
内部插件模式
McAfee MySQL Audit Plugin
MariaDB Audit plugin
旁路监听模式
mysql-sniffer
360网神审核
明御数据库审计
5.存储引擎类问题
说说你了解的传储引擎及其适用场景?
各引擎简介
MyISAM存储引擎
默认MyISAM的表会在磁盘中产生3个文件
frm文件(framework)
存放表结构
myd文件(data)
存放表数据
myi文件(index)
存放表索引
堆表分式存储
堆表将索引和数据分开,索引中叶子节点存放的是数据的位置,而不是数据本身
表级锁
非事物型引擎
可以在创建的时候指定数据文件和索引文件的存储位置,只有MyISAM表支持
DATA DIRECORY [=] 数据保存的绝对路径
INDEX DIRECTORY [=] 索引文件保存的绝对路径
MyISAM单表最大支持的数据量2的64次方条记录
每个表最多可以建立64个索引
如果是复合索引,每个复合索引最多包含16个列,索引值最大长度是1000B
引擎的存储格式
定长(FIXED 静态)
是指字段中不包含VARCHAR/TEXT/BLOB
动态(DYNAMIC)
只要字段中包含了VARCHAR/TEXT/BLOB
压缩(COMPRESSED)
myisampack创建
适合场景
读操作远大于写的操作
不需要使用事物的场景
InnoDB存储引擎
设计遵循ACID模型,支持事务,具有从服务崩溃中恢复的能力,能够最大限度保护用户的数据
支持行级锁,可以提升多用户并发时的读写性能
支持外键,保证数据的一致性和完整性
InnoDB表的数据以主键聚集存储的。每个InnoDB表都有一个称为聚簇索引的主键索引,用于组织数据以最小化主键查找的I/O
创建InnoDB表之后会产生两个文件
.frm表结构文件
.ibd数据和索引存储表空间中
自适应hash索引
适合场景
多数OLTP场景
需要使用事物的场景
MyISAM与InnoDB的区别
在什么情况下InnoDB无法在线修改表结构?
增量全文索引
增加空间索引
删除主键
增加自增列
修改列的类型
修改表字符集
在无法进行在线修改表结构的情况下,要如何操作?
原生ddl
pt-online-schema-change
gh-ost
InnoDB是如何实现事务的?
什么事务?
事物的实现
InnoDB读操作是否阻塞写操作?
InnoDB 存储引擎特性
InnoDB各版本功能对比
老版本InnoDB
支持ACID,行锁设置,MVCC
MySQL 5.4之前的默认InnoDB
InnoDB 1.0.x
增加了compress和dynamic功能
MySQL版本 5.1到5,4 ,MySQL Plugin
InnoDB 1.1.x
增加了Linux AIO,多回滚段
MySQL版本5.5
InnoDB1.2.x
增加了全文索引支持,在线索引添加
Fully ACID
原子性(Atomicity)
Auto commit
COMMIT statement
ROLLBACK statement
Operational data from the INFORMATION_SCHEMA tables
一致性(Consistency)
InnoDB doublewrite buffer
crash recovery
隔离性(Isolation)
Auto commit
SET ISOLATION LEVEL statement
The low-level details of InnoDB locking
持久性(Durability)
InnoDB doublewrite buffer
innodb_flush_log_at_trx_commit
sync_binlog
innodb_file_per_table
在存储设备(如磁盘驱动器,SSD或RAID阵列)中写入缓冲区
操作系统是否支持fsync()系统调用
备份策略
存储设备中的电池备份缓存
不间断电源(UPS)
对于分布式或托管数据应用程序
MVCC
InnoDB架构
Buffer Pool缓冲池
Change Buffer更改缓冲区
Adaptive Hash Index自适应哈希索引
Redo Log Buffer重做日志缓冲区
System Tablespace系统表空间
InnoDB数据字典
Doublewrite Buffer 双写缓冲池
Undo log撤消日志
File-Per-Table Tablespaces独立表空间
副主题
副主题
General Tablespaces一般表空间
Undo Tablespace撤消表空间
Temporary Tablespace临时表空间
Redo Log重做日志
InnoDB的特点
Row-level Locking
支持行级锁,可以提升多用户并发时的读写性能
Foreign key support
朝着正无穷取整,比如 3/2 ,1.5 就取2
High performance、High scalability、High availability
Automatic deadlock detection
索引和算法
索引的类型
B+树索引
常用的索引类型
找到数据页
参考资料
http://blog.csdn.net/hguisu/article/details/7786014
http://blog.csdn.net/u013235478/article/details/50625677
B+树索引的原理:
系统从磁盘读取数据是以block为单位的,一个block为4KB,InnoDB存储引擎中有页(Page)的概念,每一页的读取是连续的block,所以大小的设置是4KB的整数倍。
时间复杂度O(h),h层级的深度
一棵m阶的B-Tree有如下特性:
1. 每个节点最多有m个孩子。
2. 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
3. 若根节点不是叶子节点,则至少有2个孩子
4. 所有叶子节点都在同一层,且不包含其它关键字信息
5. 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
6. 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
7. ki(i=1,…n)为关键字,且关键字升序排序。
8. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
保持平衡据有旋转的功能。
哈希索引
自动生成,不能人为干预
全文索引
优化器选择不使用索引的情况
范围查找
Join链接操作
锁
latch和lock
latch
轻量级锁
lock
重量级锁
扩展知识
hexdump
hexdump是Linux下的一个二进制文件查看工具
MySQL DDL为什么成本高?
在修改表结构时, 究竟会发生什么
表结构在InnoDB引擎中是什么样的呢?
DDL成本的五个维度
Instant: 此变更可以"立刻"完成
In Place: 此变更由InnoDB引擎独立完成, 不需要使用Redo log等, 可以节省开销
Rebuild Table: 此变更会重建聚簇索引, 一般情况下, 涉及到数据变更时才需要重建聚簇索引
Permits Concurrent DML: 此变更进行时, 是否允许其他DML变更同一张表. 此特性关系到变更是否会长时间阻塞业务
Only Modifies Metadata: 此变更是否只变更元信息, 不涉及数据变更
6.MySQL架构类问题
主从复制问题问题
MySQL的主从复制是如何工作的
复制的基本原理
slave会从master读取binlog来进行数据同步
三步骤+原理图
master将改变记录到二进制日志(binary log)。这些记录过程叫做二进制日志事件,binary log events
slave将master的binary log events拷贝到它的中继日志(relay log)
slave重做中继日志中的事件,将改变应用到自己的数据库中。 MySQL复制是异步的且串行化的
复制的基本原则
Master 和 Slave 上配置不同 的 server-id ,且binlog_format 设置为ROW 格式
每个master可以有多个salve
MySQL主从复制的配置步骤
比较基于GTID方式复制和基于日志点的复制
什么是基于日志点的复制
传统的主从复制方式
slave 请求Master的增量日志依赖于日志偏移量
配置链路是需要指定Master log file和 master log pos参数
什么是基于GTID的复制
GTID = Server_UUID + Transaction_ID
Server_UUID 是全局唯一的
Transaction_ID 是自增的
slave增量同步Master的数据依赖其未同步的事务ID
配置复制链路时,slave可以根据已同步的事务ID继续自动同步
两种复制方式的特点
两种复制方式该什么选择
需要兼容老版本MySQL及MariaDB(日志点)
需要使用MMM架构(日志点)
其他(GTID)
如何减少主从复制的延迟
主从复制延迟产生的原因
几种减少主从延迟的处理方法
Master执行大事务
数万行数据更新以及对大表DDL操作
化大事务为小事务,分批更新数据
使用PT-OSC进行Online DDL
网络延迟
减少单次事务处理的数据量以减少产生的日志文件大小
减少主上所同步的从库数量
由于主上多线程的写入从上单线程恢复引起的延迟
使用MySQL5.7之后的多线程复制
使用MGR复制架构
备份myisam表
主从异常问题
索引字节太长
code 1032
高可用架构
内部实现
官方NDB
官方MGR
Percona PXC
MariaDB Galera Cluster
外部实现
MHA
MMM
MOHA
replication-manager
Orchestrator
高可用架构类常见问题
比较MMM和MHA两种高可用架构的优缺点
MMM和MHA架构的作用
对主从复制集群中的Master的监控进行监控
当Master宕机后把写VIP迁移到新的Master
重新配置集群中的其他slave对新的Master同步
MMM适用的主从复制架构
MMM架构需要的资源
MMM架构的配置步骤
MMM架构的优点
MMM架构的缺点
MMM架构的适用场景
MHA适用的主从复制架构
MHA架构需要的资源
MHA架构的配置步骤
MHA架构的优点
MHA架构的缺点
MHA架构的适用场景
VIP与脑裂
MOHA
PXC
说说你对MGR的认识
什么是MGR复制
如何解决数据库库读写负载大的问题?
如何解决读负载大的问题
如何解决写负载大的问题
7.MySQL监控类问题
监控常用问题
说说你都MySQL进行过哪些监控
性能类指标
功能性指标
这些监控是如何实现的
zabbix
PMM
8.备份和恢复类问题
基础
安装MySQL
按文档基本步骤执行
复制bin
复制man
启动MySQLd后执行MySQLd_secure_install
.my.cnf
导出MySQL.user数据
select into outfile
information_schema.columns
简单的管理帐号
创建一个空数据库
create database
分配一个账号给这个数据库
create user
grant
进阶
创造一个实际的数据库
设置存储引擎
default-storage-engine=INNODB
设置数据位置
innodb_data_home_dir
innodb_log_group_home_dir
设定服务器和客户端的字符集
客户端的字符集一定要设定,不然导入中文是乱码
一旦客户端的字符集和导入时不同,显示居然是乱码。。。
原因
导入数据时从客户端发出的字符集用client
服务器收到后,转成connection
服务器给客户端的结果,会转成result
MySQL db < file
file太大,按表格分割了
tablespaces
多个表空间,只有最后一个表空间会增大
别用max
书写各种查询应用
安装perl对应的module
DBI,很好安装
DBD
MySQL/include复制
perl Makefile.PL的配置
MySQL/lib复制,运行时需要
连接MySQLd
DBI->connect
DBI->disconnect
perldoc DBI
设置log系统
输出位置
log_output=TABLE,FILE
只影响general_log和slow_log
也就是其他的log输出仍然是文件,不受此设置影响
general_log=1
连接和sql操作都被记录下来
输出目录在data_dir,而不是innodb_data_dir
log_slow_queries=slow.log
耗时查询会被记录在这里
long_query_time=2
默认10秒太长了
错误和警告log默认都是打开的
log_bin
binlog_format=MIXED
修改操作的记录
数据库恢复用的
中级
备份和恢复
增强可靠性
优化
高级
存储过程和视图
table分割
常见问题
备份计划是什么?
备份恢复时间
备份恢复失败如何处理
mysqldump和xtrabackup实现原理
9.MySQL连接类问题
Too many Connection
分支主题

0 条评论
下一页











