后端Java知识指北
2022-09-23 15:02:04 99 举报AI智能生成
很全面的知识汇总
作者其他创作
大纲/内容
JVM
意义 屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果
工具
mat
http://spotify.github.io/threaddump-analyzer/
jconsole
VisualVM
GC分析
gcviewer
GChisto
Jstat
jmap
jstack
jhat
arthas
参数
-Xss 设置每个线程可使用的内存大小,即栈的大小。在相同物理内存下,减小这个值能生成更多的线程,当然操作系统对一个进程内的线程数还是有限制的,不能无限生成。线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大,如果该值设置过大,就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误。
-Xms 初始堆大小
-Xmx 最大堆大小
-Xmn 新生代大小
-XX:NewRatio:设置新生代和老年代的比值。如:为3,表示年轻代与老年代比值为1:3
-XX:SurvivorRatio:新生代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:为3,表示Eden:Survivor=3:2,一个Survivor区占整个新生代的1/5
-XX:MaxTenuringThreshold:设置转入老年代的存活次数。如果是0,则直接跳过新生代进入老年代
-XX:PermSize、-XX:MaxPermSize:分别设置永久代最小大小与最大大小(Java8以前)
-XX:MetaspaceSize、-XX:MaxMetaspaceSize:分别设置元空间最小大小与最大大小(Java8以后)
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行老年代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器新生代收集方式为并行收集时,使用的CPU数。并行收集线程数。
-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;
XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
实践
https://developer.ibm.com/zh/articles/j-lo-jvm-optimize-experience/
https://www.javazhiyin.com/51851.html
例子
垃圾收集器
Serial
参数控制:-XX:+UseSerialGC 串行收集器
串行收集器 单线程
新生代、老年代使用串行回收;
新生代复制算法、老年代标记-压缩
垃圾收集的过程中会Stop The World(服务暂停)
PraNew
-XX:+UseParNewGC ParNew收集器
-XX:ParallelGCThreads 限制线程数量
Serial收集器的多线程版本,
控制参数、收集算法、回收策略等等 和Serial收集器完全一样。
Parallel Scavenge
参数控制:-XX:+UseParallelGC
-XX:+UseAdaptiveSizePolicy 这是一个开关参数,打开参数后,就不需要手工指定细节参数
类似ParNew收集器
Parallel收集器更关注系统的吞吐量。
可以通过参数来打开自适应调节策略,
也可以通过参数控制GC的时间不大于多少毫秒或者比例;
新生代复制算法、老年代标记-压缩
老年代收集器
Serial Old
一个单线程的老年代版本收集器
一种是在JDK1.5及以前的版本中和Parallel Scavenge收集器搭配使用
Parallel Old
参数控制: -XX:+UseParallelOldGC 使用Parallel收集器+ 老年代并行
Parallel Old是Parallel Scavenge收集器的老年代版本
使用多线程和“标记-整理”算法。
CMS
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于“标记-清除”算法实现的。
针对老年代的回收
[
初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象,速度很快,需要“Stop The World”。
并发标记(CMS concurrent mark):进行GC Roots Tracing的过程,在整个过程中耗时最长。
重新标记(CMS remark):为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长一些,但远比并发标记的时间短。此阶段也需要“Stop The World”。
并发清除(CMS concurrent sweep)
整个过程中耗时最长的并发标记和并发清除过程收集器线程都可以与用户线程一起工作
优点
并发收集、低停顿,因此CMS收集器也被称为并发低停顿收集器(Concurrent Low Pause Collector)。
缺点
对CPU资源非常敏感 其实,面向并发设计的程序都对CPU资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但会因为占用了一部分线程(或者说CPU资源)而导致应用程序变慢,总吞吐量会降低。CMS默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在4个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着CPU数量的增加而下降。但是当CPU不足4个时(比如2个),CMS对用户程序的影响就可能变得很大,如果本来CPU负载就比较大,还要分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了50%,其实也让人无法接受。
无法处理浮动垃圾(Floating Garbage) 可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生。这一部分垃圾出现在标记过程之后,CMS无法再当次收集中处理掉它们,只好留待下一次GC时再清理掉。这一部分垃圾就被称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。
标记-清除算法导致的空间碎片 CMS是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象。
如果对象分配率高于CMS回收的效率,将导致在CMS完成之前老年代就被填满,这种状况成为“并发模式失败”,同样也会引起full GC。可以调节-XX:CMSInitiatingOccupancyFraction和新生代的堆大小。
相关参数
-XX:+UseConcMarkSweepGC - 启用CMS,同时-XX:+UseParNewGC会被自动打开。
-XX:CMSInitiatingOccupancyFraction - 设置第一次启动CMS的阈值,默认是68%。
-XX:+UseCMSInitiatingOccupancyOnly - 只是用设定的回收阈值,如果不指定,JVM仅在第一次使用设定值,后续则自动调整。
-XX:+CMSPermGenSweepingEnabled - 回收perm区。
-XX:+CMSClassUnloadingEnabled - 相对于并行收集器,CMS收集器默认不会对永久代进行垃圾回收(在1.7中是默认关闭,但是在1.8中是默认打开的)。如果希望对永久代进行垃圾回收,则可以打开此标志,同时打开-XX:+CMSPermGenSweepingEnabled 92%默认值。
-XX:+CMSConcurrentMTEnabled - 并发的CMS阶段将会启动多个GC线程和其他线程并发工作,默认为true。
-XX:+UseCMSCompactAtFullCollection - 在full GC的时候进行整理(mark sweep compact),默认为true。
-XX:+CMSFullGCsBeforeCompaction - 在上一次CMS并发GC执行过后,到底还要再执行多少次**full GC**(注意不是CMS GC)才会做压缩,默认是0。如果增大这个参数,会使full GC更少做压缩,但也就更容易使CMS的老年代受碎片化问题的困扰。 本来这个参数就是用来配置降低full GC压缩的频率,以期减少某些full GC的暂停时间。CMS回退到full GC时用的算法是mark-sweep-compact,但compaction是可选的,不做的话碎片化会严重些但这次full GC的暂停时间会短些,这是个取舍。
-XX:+CMSParallelRemarkEnabled - 并行remark,以减少remark的等待时间。默认为true。
-XX:+CMSScavengeBeforeRemark - 强制remark之前开始一次minor GC,可以减少remark的等待时间,因为老生代的对象有的会依赖于新生代的对象,当增加了这个命令时会在remark之前执行一次minor GC的操作,从而可以减少老生代到新生代的可到达对象数。默认为false。
G1
设计初衷是为了尽量缩短处理超大堆时产生的停顿。在回收的时候将对象从一个小堆区复制到另一个小堆区,这意味着G1在回收垃圾的时候同时完成了堆的部分内存压缩,相对于CMS的优势而言就是内存碎片的产生率大大降低。
横跨整个堆内存
上一代的垃圾收集器一样在逻辑上被划分Eden、Survivor和老年代,但是各种角色的region个数都不是固定的。它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,而都是一部分Region(不需要连续)的集合。
特征
并行与并发 G1 能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短“Stop The World”停顿时间,部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让Java程序继续执行。
分代收集 与其他收集器一样,分代概念在G1中依然得以保留。虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但它能够采用不同方式去处理新创建的对象和已存活一段时间、熬过多次GC的旧对象来获取更好的收集效果。
空间整合 G1从整体来看是基于“标记-整理”算法实现的收集器,从局部(两个Region之间)上来看是基于“复制”算法实现的。这意味着G1运行期间不会产生内存空间碎片,收集后能提供规整的可用内存。此特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次GC。
可预测的停顿 这是G1相对CMS的一大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了降低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在GC上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了
步骤
初始标记(Initial Marking) 仅仅只是标记一下GC Roots 能直接关联到的对象,并且修改TAMS(Nest Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以的Region中创建对象,此阶段需要停顿线程,但耗时很短。 STW (stop-the-world)
并发标记(Concurrent Marking) 从GC Root 开始对堆中对象进行可达性分析,找到存活对象,此阶段耗时较长,但可与用户程序并发执行。
最终标记(Final Marking 重新标记阶段) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,这阶段需要停顿线程,但是可并行执行。STW (stop-the-world)
筛选回收(Live Data Counting and Evacuation 复制/清除阶段) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。STW (stop-the-world)
图例
参数
-XX:+UseG1GC 启用G1垃圾收集器
-XX:MaxGCPauseMillis=n 指定期望的最大停顿时间,有大概率保证在该范围内,但并非一定能实现。 ms
-XX:G1HeapRegionSize=n 设置的 G1 区域的大小。值是 2 的幂,范围是 1 MB 到 32 MB 之间。目标是根据最小的 Java 堆大小划分出约 2048 个区域。
-XX:ParallelGCThreads=n 设置 STW 工作线程数的值。将 n 的值设置为逻辑处理器的数量。n 的值与逻辑处理器的数量相同,最多为 8。如果逻辑处理器不止八个,则将 n 的值设置为逻辑处理器数的 5/8 左右。这适用于大多数情况,除非是较大的 SPARC 系统,其中 n 的值可以是逻辑处理器数的 5/16 左右。
-XX:ConcGCThreads=n 设置并行标记的线程数。将 n 设置为并行垃圾回收线程数 (ParallelGCThreads) 的 1/4 左右。
-XX:InitiatingHeapOccupancyPercent=45 设置触发标记周期的 Java 堆占用率阈值。默认占用率是整个 Java 堆的 45%。
-XX:G1ReservePercent=n 设置堆内存保留为假天花板的总量,以降低提升失败的可能性,默认值是 10。
不要设置年轻代大小 通过-Xmn明确地设置年轻代大小来插手G1收集器的默认行为。
收集时G1收集器将不再遵照暂停时间指标。所以本质上,设置年轻代大小将不会启用暂停时间目标。
G1收集器将不能按需扩张、收缩年轻代空间。自从大小被固定之后,大小将不再会被改变。
收集时G1收集器将不再遵照暂停时间指标。所以本质上,设置年轻代大小将不会启用暂停时间目标。
G1收集器将不能按需扩张、收缩年轻代空间。自从大小被固定之后,大小将不再会被改变。
总结
ZGC
环境 : JDK 11中推出的一款低延迟垃圾回收器
设计目标
停顿时间不超过10ms;
停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
支持8MB~4TB级别的堆(未来支持16TB)。
解决痛点
很多低延迟高可用Java服务的系统可用性经常受GC停顿的困扰。GC停顿指垃圾回收期间STW(Stop The World),当STW时,所有应用线程停止活动,等待GC停顿结束。
CMS新生代的Young GC、G1和ZGC都基于 标记-整理算法
G1 复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是STW的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。
G1未能解决转移过程中准确定位对象地址的问题。
ZGC在标记、转移和重定位阶段几乎都是并发的,这是ZGC实现停顿时间小于10ms目标的最关键原因。
原理
ZGC只有三个STW阶段:初始标记,再标记,初始转移。其中,初始标记和初始转移分别都只需要扫描所有GC Roots,其处理时间和GC Roots的数量成正比,一般情况耗时非常短;
再标记阶段STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。
ZGC几乎所有暂停都只依赖于GC Roots集合大小,停顿时间不会随着堆的大小或者活跃对象的大小而增加。
与ZGC对比,G1的转移阶段完全STW的,且停顿时间随存活对象的大小增加而增加。
关键技术
色指针
JVM是如何判断对象被移动过呢?就是利用对象引用的地址,即着色指针。
着色指针是一种将信息存储在指针中的技术。
ZGC实际仅使用64位地址空间的第0~41位,而第42~45位存储元数据,第47~63位固定为0。
读屏障技术
解决了转移过程中准确访问对象的问题,实现了并发转移。大致原理描述如下:并发转移中“并发”意味着GC线程在转移对象的过程中,应用线程也在不停地访问对象。假设对象发生转移,但对象地址未及时更新,那么应用线程可能访问到旧地址,从而造成错误。而在ZGC中,应用线程访问对象将触发“读屏障”,如果发现对象被移动了,那么“读屏障”会把读出来的指针更新到对象的新地址上,这样应用线程始终访问的都是对象的新地址。
读屏障是JVM向应用代码插入一小段代码的技术。当应用线程从堆中读取对象引用时,就会执行这段代码。需要注意的是,仅“从堆中读取对象引用”才会触发这段代码。
效果图
注意事项
参数样例
-Xms10G -Xmx10G -Xms -Xmx:堆的最大内存和最小内存,这里都设置为10G,程序的堆内存将保持10G不变。
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m -XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize:设置CodeCache的大小, JIT编译的代码都放在CodeCache中,一般服务64m或128m就已经足够。我们的服务因为有一定特殊性,所以设置的较大,后面会详细介绍。
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC 启用ZGC的配置。
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6 -XX:ConcGCThreads:并发回收垃圾的线程。默认是总核数的12.5%,8核CPU默认是1。调大后GC变快,但会占用程序运行时的CPU资源,吞吐会受到影响。 -XX:ParallelGCThreads:STW阶段使用线程数,默认是总核数的60%。
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5 ZGC发生的最小时间间隔,单位秒。 ///// ZGC触发自适应算法的修正系数,默认2,数值越大,越早的触发ZGC。
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive 是否启用主动回收,默认开启,这里的配置表示关闭。
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/opt/logs/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50m 设置GC日志中的内容、格式、位置以及每个日志的大小。
-XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m -XX:ReservedCodeCacheSize -XX:InitialCodeCacheSize:设置CodeCache的大小, JIT编译的代码都放在CodeCache中,一般服务64m或128m就已经足够。我们的服务因为有一定特殊性,所以设置的较大,后面会详细介绍。
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC 启用ZGC的配置。
-XX:ConcGCThreads=2 -XX:ParallelGCThreads=6 -XX:ConcGCThreads:并发回收垃圾的线程。默认是总核数的12.5%,8核CPU默认是1。调大后GC变快,但会占用程序运行时的CPU资源,吞吐会受到影响。 -XX:ParallelGCThreads:STW阶段使用线程数,默认是总核数的60%。
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5 ZGC发生的最小时间间隔,单位秒。 ///// ZGC触发自适应算法的修正系数,默认2,数值越大,越早的触发ZGC。
-XX:+UnlockDiagnosticVMOptions -XX:-ZProactive 是否启用主动回收,默认开启,这里的配置表示关闭。
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/opt/logs/logs/gc-%t.log:time,tid,tags:filecount=5,filesize=50m 设置GC日志中的内容、格式、位置以及每个日志的大小。
ZGC触发时机
阻塞内存分配请求触发:当垃圾来不及回收,垃圾将堆占满时,会导致部分线程阻塞。我们应当避免出现这种触发方式。日志中关键字是“Allocation Stall”。
基于分配速率的自适应算法:最主要的GC触发方式,其算法原理可简单描述为”ZGC根据近期的对象分配速率以及GC时间,计算出当内存占用达到什么阈值时触发下一次GC”。自适应算法的详细理论可参考彭成寒《新一代垃圾回收器ZGC设计与实现》一书中的内容。通过ZAllocationSpikeTolerance参数控制阈值大小,该参数默认2,数值越大,越早的触发GC。我们通过调整此参数解决了一些问题。日志中关键字是“Allocation Rate”。
基于固定时间间隔:通过ZCollectionInterval控制,适合应对突增流量场景。流量平稳变化时,自适应算法可能在堆使用率达到95%以上才触发GC。流量突增时,自适应算法触发的时机可能会过晚,导致部分线程阻塞。我们通过调整此参数解决流量突增场景的问题,比如定时活动、秒杀等场景。日志中关键字是“Timer”。
主动触发规则:类似于固定间隔规则,但时间间隔不固定,是ZGC自行算出来的时机,我们的服务因为已经加了基于固定时间间隔的触发机制,所以通过-ZProactive参数将该功能关闭,以免GC频繁,影响服务可用性。 日志中关键字是“Proactive”。
预热规则:服务刚启动时出现,一般不需要关注。日志中关键字是“Warmup”。
外部触发:代码中显式调用System.gc()触发。 日志中关键字是“System.gc()”。
元数据分配触发:元数据区不足时导致,一般不需要关注。 日志中关键字是“Metadata GC Threshold”。
基于分配速率的自适应算法:最主要的GC触发方式,其算法原理可简单描述为”ZGC根据近期的对象分配速率以及GC时间,计算出当内存占用达到什么阈值时触发下一次GC”。自适应算法的详细理论可参考彭成寒《新一代垃圾回收器ZGC设计与实现》一书中的内容。通过ZAllocationSpikeTolerance参数控制阈值大小,该参数默认2,数值越大,越早的触发GC。我们通过调整此参数解决了一些问题。日志中关键字是“Allocation Rate”。
基于固定时间间隔:通过ZCollectionInterval控制,适合应对突增流量场景。流量平稳变化时,自适应算法可能在堆使用率达到95%以上才触发GC。流量突增时,自适应算法触发的时机可能会过晚,导致部分线程阻塞。我们通过调整此参数解决流量突增场景的问题,比如定时活动、秒杀等场景。日志中关键字是“Timer”。
主动触发规则:类似于固定间隔规则,但时间间隔不固定,是ZGC自行算出来的时机,我们的服务因为已经加了基于固定时间间隔的触发机制,所以通过-ZProactive参数将该功能关闭,以免GC频繁,影响服务可用性。 日志中关键字是“Proactive”。
预热规则:服务刚启动时出现,一般不需要关注。日志中关键字是“Warmup”。
外部触发:代码中显式调用System.gc()触发。 日志中关键字是“System.gc()”。
元数据分配触发:元数据区不足时导致,一般不需要关注。 日志中关键字是“Metadata GC Threshold”。
ZGC日志
ZGC停顿原因
调优实践
常见搭配
总结
有关概念
并行和并发
并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行。而垃圾收集程序运行在另一个CPU上。
吞吐量
吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
吞吐量是长时间内未使用于垃圾收集的总时间的百分比。吞吐量包含分配内存所花费的时间(不过通常不需要调整分配的速度)。
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
吞吐量是长时间内未使用于垃圾收集的总时间的百分比。吞吐量包含分配内存所花费的时间(不过通常不需要调整分配的速度)。
延迟 是应用程序响应度的表现,垃圾收集暂停会影响应用程序的响应性。
空间量 是进程的工作集,以页和缓存线为衡量。在具有有限物理内存或者多处理器的系统上,空间量可能可伸缩。Promptness是对象死亡到内存可用之间的时间,这是分布式系统的一个重要考量因素,包括RMI。
Minor GC 和 Full GC
新生代GC(Minor GC):指发生在新生代的垃圾收集动作,因为Java对象大多都具备朝生夕灭的特性,所以Minor GC非常频繁,一般回收速度也比较快。
老年代GC(Major GC / Full GC):指发生在老年代的GC,出现了Major GC,经常会伴随至少一次的Minor GC(但非绝对的,在Parallel Scavenge收集器的收集策略里就有直接进行Major GC的策略选择过程)。Major GC的速度一般会比Minor GC慢10倍以上。
垃圾回收算法
引用计数算法
引用计数是垃圾收集器中的早期策略。在这种方法中,堆中每个对象实例都有一个引用计数。当一个对象被创建时,就将该对象实例分配给一个变量,该变量计数设置为1。当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b引用的对象实例的计数器+1),但当一个对象实例的某个引用超过了生命周期或者被设置为一个新值时,对象实例的引用计数器减1。任何引用计数器为0的对象实例可以被当作垃圾收集。当一个对象实例被垃圾收集时,它引用的任何对象实例的引用计数器减1。
优点:引用计数收集器可以很快的执行,交织在程序运行中。对程序需要不被长时间打断的实时环境比较有利。
缺点:无法检测出循环引用。如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0。
缺点:无法检测出循环引用。如父对象有一个对子对象的引用,子对象反过来引用父对象。这样,他们的引用计数永远不可能为0。
可达性分析算法
从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点,无用的节点将会被判定为是可回收的对象。
作为GC Roots的对象
虚拟机栈中引用的对象(栈帧中的本地变量表);
方法区中类静态属性引用的对象;
方法区中常量引用的对象;
本地方法栈中JNI(Native方法)引用的对象。
复制算法
它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用的内存空间一次清理掉,这样一来就不容易出现内存碎片的问题。
高昂的代价,因为能够使用的内存缩减到原来的一半。
标记-清除算法
标记-清除算法分为两个阶段:标记阶段和清除阶段。标记阶段的任务是标记出所有需要被回收的对象,清除阶段就是回收被标记的对象所占用的空间。
会造成内存碎片
标记-整理算法
为了解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。该算法标记阶段和Mark-Sweep一样,但是在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动(美团面试题目,记住是完成标记之后,先不清理,先移动再清理回收对象),然后清理掉端边界以外的内存。
标记-整理算法采用标记-清除算法一样的方式进行对象的标记,但在清除时不同,在回收不存活的对象占用的空间后,会将所有的存活对象往左端空闲空间移动,并更新对应的指针。标记-整理算法是在标记-清除算法的基础上,又进行了对象的移动,因此成本更高,但是却解决了内存碎片的问题。
三个阶段
标记阶段,即从GC Roots集合开始,标记活跃对象;
转移阶段,即把活跃对象复制到新的内存地址上;
重定位阶段,因为转移导致对象的地址发生了变化,在重定位阶段,所有指向对象旧地址的指针都要调整到对象新的地址上。
分代收集算法
它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),在堆区之外还有一个代就是永久代(Permanet Generation)。老年代的特点是每次垃圾收集时只有少量对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收,那么就可以根据不同代的特点采取最适合的收集算法。
HotSpot算法
枚举根结点
当执行系统停顿下来后,并不需要一个不漏的检查完所在执行上下文和全局的引用位置,在HotSpot的实现中,使用一组称为OopMap的数据结构来存放对象引用
安全点
在这些特定的位置,线程的状态可以被确定
位置
方法调用指令
循环跳转指令
异常跳转指令
中断方式
抢占式
GC发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它跑在安全点上
主动式
设置一个标志,各个线程执行时主动轮询这个标志,发现中断标志为真时就自己中断挂起
安全区域
背景:线程Sleep状态或者Blocked状态的时候,无法响应JVM中断,走到安全的地方,JVM也不能等他们,这样就无法进行GC
安全区域是指在一段代码中,引用关系不会发生变化,这个区域中的任何地方开始GC都是安全的。
方法区回收时机
该类所有的实例都已经被回收,也就是Java堆中不存在该类的任何实例;
加载该类的ClassLoader已经被回收;
该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
常见知识点
-verbose:gc 打印关于每次收集堆和垃圾收集的信息。
作为GC Roots的对象包括4种情况
虚拟机栈中引用的对象(栈帧中的本地变量表);
方法区中类静态属性引用的对象;
方法区中常量引用的对象;
本地方法栈中JNI(Native方法)引用的对象。
JVM的内存结构
随线程而生、随线程而灭
程序计数器
虚拟机栈
本地方法栈
堆区
方法区
新生代和老年代的区别
所谓的新生代和老年代是针对于分代收集算法来定义的,新生代又分为Eden和Survivor两个区。
加上老年代就这三个区。
数据会首先分配到Eden区 当中(当然也有特殊情况,如果是大对象那么会直接放入到老年代(大对象是指需要大量连续内存空间的java对象)。),当Eden没有足够空间的时候就会 触发jvm发起一次Minor GC。
如果对象经过一次Minor GC还存活,并且又能被Survivor空间接受,那么将被移动到Survivor空 间当中。并将其年龄设为1,对象在Survivor每熬过一次Minor GC,年龄就加1,当年龄达到一定的程度(默认为15)时,就会被晋升到老年代 中了,当然晋升老年代的年龄是可以设置的。
如果老年代满了就执行:Full GC 因为不经常执行,因此采用了 Mark-Compact算法清理
GC是什么时候触发的
Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。
然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。
因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Full GC
年老代(Tenured)被写满;
持久代(Perm)被写满;
System.gc()被显示调用;
上一次GC之后Heap的各域分配策略动态变化
并行垃圾收集器
ParallelGC
ParallelGC
串行和并行垃圾收集器之间的主要区别在于并行垃圾收集器使用多线程去加快垃圾收集速度。
使用命令行选项-XX:+UseParallelGC启用并行垃圾收集器。默认情况下,使用该选项,minor和major垃圾收集都并行运行,以进一步减少垃圾收集开销。
允许指定行为,而不是指定分代堆的大小和其他低级别的调优细节。
最大垃圾收集暂停时间:最大垃圾收集暂停时间目标用命令行选项-XX:MaxGCPauseMillis=<N>指定。这被解释为一个提示,期望暂停时间是<N>毫秒或者更小的时间。默认情况下,没有最大暂停时间目标。如果指定了暂停时间目标,则会调整堆大小和与垃圾收集相关的其他参数,以使垃圾收集暂停时间小于指定值。但是,可能并不总是满足所需的暂停时间目标。这些调整可能会导致垃圾收集器降低应用程序的总吞吐量。
吞吐量:吞吐量目标是根据进行垃圾收集所花费的时间与在垃圾收集外所花费的时间(称为应用程序时间)来衡量的。目标由命令行选项-XX:GCTimeRatio=<N>指定,该选项将垃圾收集时间与应用程序时间的比率设置为1/(1 + N)。
空间量(堆大小) 用选项-Xmx<N>来指定最大堆大小。另外,垃圾收集器有一个隐藏的目标,即只要满足其他目标,就可以最小化堆的大小。(能力守恒)
使用线程数的计算 -XX:ParallelGCThreads=<N>来控制
在具有<N>个硬件线程并且<N>大于8的机器上,并行垃圾收集器使用<N>固定的分数作为垃圾收集器的线程。
对于较大的<N>值,这个分数约为5/8。
当<N>值比8小的时候,使用的分数即为<N>。在选定的平台上,分数下降到5/16。
减少垃圾收集线程的数量并增大年老代的大小将减少此碎片效应
并行垃圾收集器目标的优先级
目标按如下顺序处理:最大暂停时间,吞吐量和最小堆大小目标。
首先满足最大暂停时间目标,只有在达到这个目标之后,吞吐量目标才得以实现。相似地,只有在前两个目标实现之后,才会考虑足迹目标。
并行垃圾收集器分代堆大小调整
垃圾收集器保留的统计信息(如平均暂停时间)将在每次垃圾收集结束时更新。
调用System.gc()会忽略保留统计信息和调整分代堆大小。
分代堆大小的固定百分比来增量增长或者缩小分代堆大小的,以便分代可以增加或者减少到他期待的堆大小。
增长和缩小分代堆大小是根据不同的速率进行的。默认情况下,增长以20%的增量增长,收缩以5%的增量收缩。
使用年轻代命令行-XX:YoungGenerationSizeIncrement=<Y>和年老代命令行-XX:TenuredGenerationSizeIncrement。
分代收缩的百分比由命令行标识-XX:AdaptiveSizeDecrementScaleFactor=<D>。如果增长率是X%,则收缩率为X/D%。
并行垃圾收集器默认堆大小
可以使用选项-Xms(初始堆大小)和-Xmx(最大堆大小)来指定初始堆和最大堆大小。
如果知道应用程序需要多少堆才能正常工作,那么将-Xms和-Xmx设置为相同的值。如果不知道,那么JVM将首先使用初始化堆大小,然后逐步增加Java堆大小直到在堆使用和性能之间找到平衡。
其他的参数和选项会影响这些默认值。要验证默认值,请使用-XX:+PrintFlagsFinal选项并且在输出中查找-XX:MaxHeapSize。
类加载机制
类加载器 负责读取 Java 字节代码,并转换成java.lang.Class类的一个实例
类加载器除了用于加载类外,还可用于确定类在Java虚拟机中的唯一性。
即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。
即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。
种类
启动类加载器,Bootstrap ClassLoader,加载JACA_HOME\lib,或者被-Xbootclasspath参数限定的类
扩展类加载器,Extension ClassLoader,加载\lib\ext,或者被java.ext.dirs系统变量指定的类
应用程序类加载器,Application ClassLoader,加载ClassPath中的类库
自定义类加载器,通过继承ClassLoader实现,一般是加载我们的自定义类
双亲委派模型
双亲委派是指每次收到类加载请求时,先将请求委派给父类加载器完成(所有加载请求最终会委派到顶层的Bootstrap ClassLoader加载器中),如果父类加载器无法完成这个加载(该加载器的搜索范围中没有找到对应的类),子类尝试自己加载。
类加载过程 加载,连接,初始化;
优点
避免同一个类被多次加载;
每个加载器只能加载自己范围内的类;
问题
解释 对于静态字段,只有直接定义这个字段的类才会被初始化,因此通过其子类来引用父类中定义的静态字段,只会触发父类的初始化而不会触发子类的初始化。
Java对象
对象的创建
1、检查参数是否在常量池中定位到一个类的符号引用;该类是否被加载、解析、初始化过
若没有做进行类加载
2、若有则分配内存
内存绝对规整
用“指针碰撞”来分配内存
内存不规整
用“空闲列表”来分配内存
线程安全
对分配内存空间的工作进行同步处理
采用CAS+失败重试的方式保证更新操作的原子性
每个线程分配一块本地线程分配缓冲区
TLAB
-XX:+/-UseTLAB
3、始化已分配内存为零值(保证类型不赋初值可以使用)
4、上面工作完成后,执行init方法按照程序员意愿初始化对象
对象的内存布局
对象头
存储运行时数据
存储类型指针
如果对象是数组对象,还有一个保存数组长度的空间,占4个字节
实例数据
是对象真正存储的有效信息
对齐填充
起占位符的作用
对象创建流程图
对象的访问定位
使用句柄
堆中有句柄池,存储到实例数据和类型数据的指针;栈中的引用指向对象的句柄地址
优点
- reference中地址相对稳定;
- 对象被移动(GC时)时只会改变句柄中的实例数据指针
直接指针
栈中的引用直接存储对象地址,到方法区中类型数据的指针包含在对象实例数据中
优点
访问速度快,节省了一次指针定位的开销
垃圾对象的判定
对象的引用
强引用
存在就不回收
软引用
将要发生内存溢出之前
实现缓存
弱引用
下一次垃圾回收
回调函数中防止内存泄露
虚引用
对对象的生存时间没有影响
能在这个对象被收集器回收时收到一个系统通知
引用计数法
难以解决对象之间相互循环引用的问题
根搜索算法
从GC Roots向下搜索建立引用链;一个对象如果到GC Roots没有任何引用链相连时,证明对象不可用
GC Roots
虚拟机栈中引用的对象
本地方法栈中引用的对象
方法区中类静态属性引用的对象
方法区中常量引用的对象
堆中垃圾回收过程
1、如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记
2、判断对象是否有必要执行finalize()方法,(没有覆盖,被调用过,都没有必要执行),放入F-Queue队列
3、放入F-Queue中,进行第二次标记
4、被拯救的移除队列,被两次标记的被回收
方法区中垃圾回收
废弃常量
没有任何一个对象引用常量池中的“abc”常量
无用的类(满足条件可以被回收,非必然)
1、该类所有的实例都已经被回收
2、加载该类的加载器被回收
3、该类对应的javalang.Class对象没有在任何地方被引用,无法通过反射访问该类的方法
运行时数据区组成
线程私有
程序计数器
当前线程所执行的字节码的行号指示器:
- 如果正在执行的是Java方法,计数器记录的是正在执行的虚拟机字节码指令的地址;
- 如果正在执行Natvie方法,计数器值为空(Undefined)
作用
Java虚拟机字节码解释器通过改变这个计数器的值来选取下一条要执行的字节码指令
JVM规范中唯一没有规定任何OutOfMemoryError的情况
虚拟机栈
用途:为JVM执行Java方法服务
编译期间完成分配
结构:栈帧:局部变量表、操作数栈、动态链接、方法出口
基本类型变量,(boolean,byte,char,short,int,float,long,double)
对象句柄
方法参数
方法的局部变量
两种异常:StackOverFlowError、如果可以动态扩展的话会产生(OutOfMemoryError) -Xss设置栈大小
本地方法栈
用途:为虚拟机使用到的native方法服务
两种异常:StackOverFlowError、OutOfMemoryError
线程共有
方法区
用途:用于存储已被JVM加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
需要垃圾回收
运行时常量池
内容:存放编译产生的字面量(常量final)和符号引用
类和接口的全限定名
字段的名称和描述符
方法的名称和描述符
特点:运行时常量池相对于Class文件常量池的一个重要特征是具备动态性
Java语言并不要求常量一定只有编译期才能产生,运行期间也能将新的常量放入池中
异常:(无法扩展)OutOfMemoryError
方法区的GC
参考垃圾对象的判定
GC堆
目的:存放对象实例和数组
需要垃圾回收gc管理的主要区域
分代处理
目的:更好的回收内存和更快的分配内存
新生代
Eden空间
From Survivor空间
To Survivor空间等
老年代
空间结构:逻辑连续的空间,物理可以不连续
优先分配TLAB(Thread Local Allocation Buffer),减少加锁,提高效率
异常:如果在堆中没有完成内存分配,并且堆也无法扩展时,会抛出OutOfMemoryError
-Xms初始堆大小 -Xmx最大堆大小
并不是所有的对象都在堆中分配
编写高效优雅Java程序
编写高效优雅的Java程序
1、构造器参数太多怎么办?
比较好的初始化方式是用Builder构造者模式。初始化直接采用链式初始化的方式进行初始化。
2、不需要实例化的类应该构造器私有
一些工具类提供的都是静态方法,这些类是不应该提供具体的实例的。
3、不要创建不必要的对象
避免无意中创建的对象,如自动装箱
可以在类的多个实例之间重用的成员变量,尽量使用static。
4、避免使用终结方法
finalizer方法,jdk不能保证何时执行,也不能保证一定会执行。如果有确实要释放的资源应该用try/finally。
5、使类和成员的可访问性最小化
编写程序和设计架构,最重要的目标之一就是模块之间的解耦。使类和成员的可访问性最小化无疑是有效的途径之一。
6、使可变性最小化
尽量使类不可变,不可变的类比可变的类更加易于设计、实现和使用,而且更不容易出错,更安全。
继承容易破坏封装性,而且会使子类的实现依赖于父类。
复合则是在类中增加一个私有域,引用类的一个实例,这样的话就避免了依赖类的具体实现。
只有在子类确实是父类的一个子类型时,才比较适合用继承。
7、优先使用复合
继承容易破坏封装性,而且会使子类的实现依赖于父类。
复合则是在类中增加一个私有域,引用类的一个实例,这样的话就避免了依赖类的具体实现。
只有在子类确实是父类的一个子类型时,才比较适合用继承。
8、接口优于抽象类
java是个单继承的,但是类允许实现多个接口。
所以当发生业务变化时,新增接口,并且需要进行业务变化的类现新接口即可。但是抽象类有可能导致不需要变化的类也不得不实现新增的业务方法。
在JDK里常用的一种设计方法是:定义一个接口,声明一个抽象的骨架类实现接口,骨架类类实现通用的方法,而实际的业务类可以同时实现接口又继承骨架类,也可以只实现接口。
如HashSet实现了implements Set接口 但是又extends 类AbstractSet,而AbstractSet本身也实现了Set接口。其他如Map,List都是这样的设计的。
9、可变参数要谨慎使用
可变参数是允许传0个参数的
如果是参数个数在1~多个之间的时候,要做单独的业务控制。
10、返回零长度的数组或集合,不要返回null
方法的结果返回null,会导致调用方的要单独处理为null的情况。返回零长度,调用方可以统一处理,如使用foreach即可
11、优先使用标准的异常
要尽量追求代码的重用,同时减少类加载的数目,提高类装载的性能。
12、用枚举代替int常量
声明的一个枚举本质就是一个类,每个具体的枚举值就是这个枚举类的实例
使用枚举比int常量的好处
常量传播导致的修改不一致问题
常量值修改变动的问题
打印时,需要配套一个字符串说明
13、将局部变量的作用域最小化
1、 在第一次使用的地方进行声明
2、 局部变量都是要自行初始化,初始化条件不满足,就不要声明
最小化的好处,减小局部变量表的大小,提示性能;
同时避免局部变量过早声明导致不正确的使用。
14、精确计算,避免使用float和double
可以使用int或者long以及BigDecimal。
15、当心字符串连接的性能
在存在大量字符串拼接或者大型字符串拼接的时候,尽量使用StringBuilder和StringBuffer。
Java
Java基础
四种对象引用
强引用
弱引用
软引用
幻像引用
Lamada
函数接口(内置)
Consumer void accept(T t) :将T 类型的参数应用于该方法
Supplier T get():返回类型为T 的对象
Function<T,R> R apply(T t):输出T类型的参数返回R类型的结果
Predicate boolean test(T t): 确定类型为T 的参数是否满足test逻辑
@FunctionalInterface (接口注解)
Stream (parallelStream)
获取方法
从 Collection 和数组
BufferedReader
静态工厂
java.util.stream.IntStream.range()
java.nio.file.Files.walk()
自己构建
.......
操作类型
Intermediate
concat
distinct
peek
parallel
sequential
unordered
map (mapToInt, flatMap 等)
有状态
filter
distinct
sorted
limit
skip
Terminal
forEach 遍历
forEachOrdered 去重
sorted 排序
iterator
toArray
Short-circuiting
allMatch
anyMatch
noneMatch
findFirst
findAny
limit
规约操作
min
max
count
sum
通用
collect
常用场景 某个功能在Stream接口中没找到,十有八九可以通过collect()方法实现
例子
使用collect()生成Collection
使用collect()生成Map
使用collect()做字符串join
......
reduce
常用场景 : 从一堆值中生成一个值
重写形式
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)
<U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
Function.identity() 返回一个输出跟输入一样的Lambda表达式对象,等价于形如t -> t形式的Lambda表达式
集合
Collections 工具类
常见考点
ArrayList和Vector的区别
HashMap和Hashtable的区别
List和Map的区别
Set里的元素是不能重复的,那么用== 以及 equals()
Collection和Collections的区别
说出ArrayList,LinkedList的存储性能和特性
Enumeration和Iterator接口的区别
ListIterator有什么特点
并发集合类是什么?
Java中HashMap的key值要是为类对象则该类需要满足什么条件?
与Java集合框架相关的有哪些最好的实践
ArrayList集合加入1万条数据,应该怎么提高效率
Map
HashMap
升级
在JDK1.7中HashMap使用数组加链表来实现
在JDK1.8中HashMap使用数组+链表+红黑树实现
JDK1.8原理
初始容量16(第一次插入才会真正分配)
每次扩容2倍
如果当前桶的容量大于装填因子*总容量就触发扩容
如果一个链表的节点个数超过8个,并且桶的长度超过64个则链表升级为红黑树,如果没有超过64个则单纯扩容2倍
首先先把hash值高16位和低16位按位与计算,然后计算桶位置算法是 index = (n - 1) & hash相当于index=hash%n
如果一颗红黑树的节点小于6个则红黑树退化为链表
线程不安全
可以存NULL
源码
HashMap实现原理及源码分析
先通过哈希函数计算出实际存储地址
如果两个不同的元素,通过哈希函数得出的实际存储地址相同,产生hash冲突
开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)
再散列函数法
链地址法
HashMap即是采用了链地址法,也就是数组+链表的方式
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
Java hashCode()和equals()的若干问题解答
1.两个对象equals为true,但hashCode不一定相同
2.由于hashMap是哈希表,首先要求HashCode相同,根据hashCode计算出实际存储地址
3.hashMap要求equals为true,hashCode也要相等,存储地址才相同,才能判断为key相同
所以必须要重写hashCode,才能保证key相同.(equals为true,但hashCode不一定相同)
4.根据hashMap存储原理,两个存储对象键相等,那么一定有相同的hashCode,如果没有
相同的hashCode,那么这两个键存储位置一定不同.
5.hashCode方法返回的就是对象存储位置的映像。因此HashCode能够快速的定位对象
所在的地址.两个键相同,必定有相同的hashCode
hashmap实现原理浅析
HashMap为什么线程不安全(hash碰撞与扩容导致)
谈谈HashMap线程不安全的体现
HashMap线程不安全的表现
HashMap并发导致死循环 CurrentHashMap
深入理解HashMap(原理,查找,扩容)
hashMap的数组长度一定保持2的次幂
HashMap的长度为什么要是2的n次方
HashTable
线程安全
默认初始容量11,装填因子0.75
每次扩容容量是2倍+1
直接使用hasoCode的值作为hash值
TreeMap
红黑树实现
key自动排序
LinkedHashMap
链表实现
应用场景
HashMap是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap
线程不安全
ConcurrentHashMap
JDK1.7
实现
分段锁 segment,锁的粒度更加精细
分段的数组+链表的形式
分段的数组+链表的形式
原理
get
get不需要加锁,采取volatile修饰共享变量
这样每次get的时候都可以获取最新的结构更新
由于遍历不需要加锁的原因是因为next是final。要么
是不为空返回,为空的话就加锁重读
这样每次get的时候都可以获取最新的结构更新
由于遍历不需要加锁的原因是因为next是final。要么
是不为空返回,为空的话就加锁重读
put
1.二阶段hash,第一阶段是定位到哪个segment
第二阶段是定位到哪个entry
第二阶段是定位到哪个entry
2.entry中,除了value,还有key,hash和next都是final修饰
意味着不能从中心或者尾部添加或者删除节点,一律添加到头部
意味着不能从中心或者尾部添加或者删除节点,一律添加到头部
3.通过count来统计段内的数据个数,只有新增和删除
会修改这个值,每次都是在上述俩个步骤的最后一步进行修改
会修改这个值,每次都是在上述俩个步骤的最后一步进行修改
remove
由于是final,所以删除节点的时候会删除某个节点
然后那个节点之上都复制,然后最后一个节点指向
被删节点的下一个节点
然后那个节点之上都复制,然后最后一个节点指向
被删节点的下一个节点
resize
扩容只会对段扩容而非整个桶
跟HashMap不同的是,段是先判断
是否需要扩容再put,而hashmap是
先put再判断是否要扩容
跟HashMap不同的是,段是先判断
是否需要扩容再put,而hashmap是
先put再判断是否要扩容
size
先尝试不锁住segment的方式来统计segment的大小
如果统计过程中,容器的count发生变化则采取加锁的方式
如果统计过程中,容器的count发生变化则采取加锁的方式
JDK1.8
取消了分段锁,而是采取了cas和synchronized来保证并发安全,
synchronized只锁住当前链表或者红黑二叉树的首节点,只要hash
不冲突,就不会产生并发,效率很高
synchronized只锁住当前链表或者红黑二叉树的首节点,只要hash
不冲突,就不会产生并发,效率很高
可以认为是JDK1.8版本你的HashMap+CAS和synchronized实现的
cocurrentHashMap的底层机制
Colletion
List
ArrarList
动态数组实现
初始容量10(只有在第一次添加的时候才会真正分配初始容量),每次扩容1.5倍,如果扩容1.5倍还不够就会使用最小容量
线程不安全
实现了RandomAccess接口,支持快速随机访问
ArrayList源码和多线程安全问题分析
删除ArrayList元素的4种正确方法
如何线程安全地遍历List:CopyOnWriteArrayList
LinkedList
双向链表
线程不安全
插入和删除时间复杂度几乎为O(1)
不支持快速随机访问
空间消耗比ArrayList消耗更大(因为每个节点都比ArrayList多了两个引用)
Vector
动态数组实现
线程安全
初始容量10,每次扩容2倍,并且可以指定每次容量的增量
可以理解为加了synchronized的ArrayList
CopyOnWriteArrayList
原理
写入时复制
特点
适合大量读操作,但是不适合大量的写操作
可以读写分离,但并不是读写锁实现的
线程安全
初始容量0,每次写入的时候容量扩容,新的容量=插入容量+旧容量
Set
TreeSet
TreeMap换皮(TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一)
Comparator 放入的对象实现此接口的话 会使用此比较器进项比较排序 否则就是升序排序
底层使用的二叉树(红黑树)结构
HashSet
HashMap换皮
它的底层是哈希表,不能保存重复数据,不保证存取顺序。
HashSet的底层通过HashMap实现的,而HashMap在1.7之前使用的是数组+链表实现,在1.8+使用的数组+链表+红黑树实现。
LinkedHashSet
LinkedHashMap换皮
CopyOnWriteSet
和CopyOnWriteArrayList原理一样
Queue
Deque
常用子类
ArrayDeque
BlockingQueue
常用子类
LinkedBlockingQueue
ArrayBlockingQueue
四组常用API
抛出异常
add
remove
element
有返回值,不会抛出异常
offer
poll
peek
阻塞等待
put
take
超时等待
offer(,,)
poll(,)
使用阻塞队列实现生产者和消费者模型
AbstractQueue
数据类型
java8种基本数据类型
boolean ~
为什么boolean没有规定字节数?
byte 1个字节
char 2个字节
shot 2个字节
int 4个字节
long 8个字节
fload 4个字节
double 8个字节
8种包装类型
分类
Boolean
Byte
Character
Short
Integer
Long
Double
缓冲池
什么是缓冲池?
那些包装类具有缓冲池?
Byte
Short
Character
Integer
Long
String相关
String
改变
在java8中String使用char数组存储数据
在java9中String使用byte数组存储字符串,并且同时使用coder来标识使用了哪种编码
String为什么被声明为final(声明为final的好处?)
什么是StringPool(StringTable)
StringBuilder
线程不安全,可以被改变
StringBuffer
线程安全,内部被synchronized同步
关键字
final
可以声明的位置
类
该类不能被继承
方法
该方法不能被重写
数据
基本类型
使数值不能够被修改
引用类型
引用不能变,但是被引用变量的对象本身可以被修改
final修饰的变量也可以被修改
使用java提供的反射技术,并且关闭安全校验也可以修改其值
static
可以声明的位置
类
方法
成员变量
静态代码块
初始化顺序
1.父类(静态变量,静态代码块)
2.子类(静态变量,静态代码块)
3.父类(实例变量,普通代码块)
4.父类构造方法
5.子类(实例变量,普通代码块)
6.子类构造方法
抽象类和接口
接口
新特性
在java8中接口可以有default方法,也可以有静态方法
但是静态方法不能够被重写,default方法可以被重写
接口中的方法默认都是public的,并且不允许定义为其他的
接口中的字段都是static和final的
抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
抽象类不能被实例化,只能被继承。
异常
分类
Exception
RuntimeException
非运行时异常
运行时异常和非运行时异常区别?
Error
OutOfMemoryError
StackOverflowError
ThreadDeath
...
Exception和Error的区别?
泛型
简介
Java泛型设计原则:只要在编译时期没有出现警告,那么运行时期就不会出现ClassCastException异常.
泛型:把类型明确的工作推迟到创建对象或调用方法的时候才去明确的特殊的类型
使用泛型
泛型类:就是把泛型定义在类上,用户使用该类的时候,才把类型明确下来
泛型方法:某一个方法上需要使用泛型....外界仅仅是关心该方法,不关心类其他的属性
泛型类派生出的子类
子类泛型类型确定
子类泛型类型不确定:继续使用父类定义的泛型
泛型通配符
在泛型中并没有像我们面向对象的继承结构,想要使用任意的泛型类型,我们可以使用通配符!
?号通配符表示可以匹配任意类型,任意的Java类都可以匹配
就只能调对象与类型无关的方法,不能调用对象与类型有关的方法
PECS(Producer Extends Consumer Super)原则
设定通配符上限
<? extends Type>
设定通配符下限
<? super Type>
带有子类限定的可以从泛型读取【也就是--->(? extend T)】-------->Producer Extends
带有超类限定的可以从泛型写入【也就是--->(? super T)】-------->Consumer Super
通配符和泛型方法
如果参数之间的类型有依赖关系,或者返回值是与参数之间有依赖关系的。那么就使用泛型方法
如果没有依赖关系的,就使用通配符,通配符会灵活一些.
使用泛型好处:
代码更加简洁【不用强制转换】程序更加健壮【只要编译时期没有警告,那么运行时期就不会出现ClassCastException异常】可读性和稳定性【在编写集合的时候,就限定了类型】
类型擦除
泛型是提供给javac编译器使用的,它用于限定集合的输入类型,让编译器在源代码级别上,即挡住向集合中插入非法数据
但编译器编译完带有泛形的java程序后,生成的class文件中将不再带有泛形信息,以此使程序运行效率不受到影响,这个过程称之为“擦除“。
泛型的应用
参考BaseDao的编写
反射
概念
1.反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法。
2.反射可以在一个类运行的时候获取类的信息的机制,可以获取在编译期不可能获得的类的信息。
3.对于任意一个对象,都能调用它的任意一个方法和属性。
4.因为类的信息是保存在Class对象中的,而这个Class对象是在程序运行时被类加载器(ClassLoader)动态加载的。
5.当类加载器装载运行了类后,动态获取Class对象的信息以及动态操作Class对象的属性和方法的功能称为Java语音的反射机制。
作用
1.反编译:.class —> .java。
2.通过反射机制访问Java对象中的属性、方法、构造方法等。
涉及到的类
1.Class —— 类的创建;
1.获取Class对象的方法
1.Class c1 = Class.forName("com.mxm.Reflect");
2.Class c2 = Reflect.class;
3.Class c3 = new Reflect().getClass();
2.无参数创建对象
Class c4 = Class。forName("com.mxm.Reflect");
Object o = c4.newInstance();
Object o = c4.newInstance();
3.有参数创建对象
Constructor<?> csr = c4.getConstructor(String.class,,int.class);
Object o = csr.newInstance("王",28);
Object o = csr.newInstance("王",28);
2.Constructor —— 反射类中构造方法;
3.Field —— 反射方法;
1.获取属性
Field field = class.getDeclaredField("name");
使用setAccseeible取消封装,特别是可以取消私有字段的访问权限。
field.setAccessible(true);
field.set(object,"老王");
使用setAccseeible取消封装,特别是可以取消私有字段的访问权限。
field.setAccessible(true);
field.set(object,"老王");
2.Field类描述
1.Field类描述的是属性对象,其中可以获取到很多属性信息,包括名字、属性类型、属性的注解。
3.安全管理
1.在安全管理器中会使用checkPermission方法来检查权限 ,而setAccessible(true)并不是将方法的权限改为public,而是取消Java的权限控制检查,所以即使是public方法,其accessible属性默认也是false。
4.修改属性中的修饰符
Field field = class.getDeclaredField("name");
String prive = Modeifier.toString(field.getModofoers());
String prive = Modeifier.toString(field.getModofoers());
4.Method —— 反射方法;
Method m = class.getDeclaredMethod("setName",String.class);
m.setAccessible(true); //同样需要忽略访问权限的限制
m.invoke(class,"老王");
m.setAccessible(true); //同样需要忽略访问权限的限制
m.invoke(class,"老王");
5.Modifier —— 访问修饰符的信息。
反射进阶
1.获取不到Class
当Class.foeName()中路径获取不到对应的Class时,会抛出异常。
2.获取不到Field
1.确实不存在这个Field,抛出异常。
2.修饰符导致的权限问题,抛出相同异常。
3.获取父类修饰符
1.getField只能获取对象和父类的public修饰的属性。
2.getDeclaredField获取对象中的各种修饰符属性,但是不能获取父类的任何属性。
3.先使用getSupperclass方法可以获取父类的suppereClass对象,再使用getDeclaredField方法获取父类的全部属性
4.获取不到父类的非public的方法
5.获取不到父类的构造方法
6.newInstance方法创建类对象的两种方法
1.Class.newInstance()
使用受到限制,对应的Class中必须存在一个无参数的构造方法,并且必须要有访问权限。
2.Contructor.newInstance()
适应任何类型的构造方法,无论是否有参数都可以调用,只需要setAccessible()方法控制访问权限。
7.反射静态方法
public class TestMethod{
static void test(){}
}
Class cla = Class.foeName("TestMethod");
Method m = cla.getDeclaredMethod("test");
m.invoke(null);
static void test(){}
}
Class cla = Class.foeName("TestMethod");
Method m = cla.getDeclaredMethod("test");
m.invoke(null);
8.反射泛型参数方法
1.Java的泛型擦除概念,泛型T在编译时会自动向上转型为Object
public class Test<T>{
public void test(T t){}
}
Class cla = Test.class;
Method m = cla.getDeclaredMethod("test",Object.class);
m.invoke(new Test<Integer>(),1);
public void test(T t){}
}
Class cla = Test.class;
Method m = cla.getDeclaredMethod("test",Object.class);
m.invoke(new Test<Integer>(),1);
9.反射框架:jOOR
注解知识点
简介
注解其实就是代码中的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相对应的处理。
使用注解来开发相对直观,简洁~
自定义Annotation
注入普通属性其实就三步:
反射出该类的方法
通过方法得到注解上具体的信息
将注解上的信息注入到方法上
注入对象
得到想要类中注入的属性,得到该属性的对象
得到属性对应的写方法,通过写方法得到注解
获取注解详细的信息,将注解的信息注入到对象上
调用属性写方法,将已填充数据的对象注入到方法中
JDK的元Annotation
其实就是元注解就是:用于修饰其他的Annotation定义。
@Retention:用于指定被修饰的Annotation被保留多长时间
RetentionPolicy.SOURCE---Java文件时期
RetentionPolicy.CLASS---Class文件时期
RetentionPolicy.RUNTIME---运行时期
由于我们使用注解常常都是配合反射来使用,所以一般都设置为RunTime时期
@Target:用于指定被修饰的Annotation用于修饰哪些程序单元
TYPE
FIELD
METHOD
PARAMETER
更多脑图和最新原创技术文章可关注公众号:Java3y
CONSTRUCTOR
LOCAL_VARIABLE
ANNOTATION_TYPE
PACKAGE
@Documented
@Documented用于指定被该Annotation修饰的Annotation类将被javadoc工具提取成文档
@Inherited
被修饰过的Annotation将具有继承性
基本Annotation
@Overried
@Overried是告诉编译器要检查该方法是实现父类的...可以帮我们避免一些低级的错误.
@Deprecated
该注解也非常常见,Java在设计的时候,可能觉得某些方法设计得不好,为了兼容以前的程序,是不能直接把它抛弃的,于是就设置它为过时。
@SuppressWarnings
抑制编译器警告【如果我们程序中没有使用新特性(没有使用泛型),编译器默认会警告我们】,使用这个注解会抑制编译器警告
@SafeVarargs
当把一个不是泛型的集合赋值给一个带泛型的集合的时候,这种情况就很容易发生堆污染
@FunctionalInterface
@FunctionalInterface用来指定该接口是函数式接口
学习注解前需要知道的:
在以前我们一般都是使用XML配置来开发的,这种方式是解耦的
但是,随着技术的发展,我们发现并不需要使用XML来解耦
XML配置一旦过多,维护起来和可读性也会有所下降
于是现在更多推崇注解开发!
多线程
JUC
什么是JUC
JUC是java.util.concurrent工具包的简称,他是并发大师Doug Lea的杰作
AQS(AbstractQueuedSynchronizer)队列同步器
是JUC的核心
原理
围绕着一个同步队列和park还有自旋锁实现
获取公平锁和非公平锁的区别
公平锁线程在唤醒的时候不能插队,非公平锁可以插队
详解(以公平锁为例)
lock加锁
lock方法真正调用的是acquire(1方法)
acquire方法
tryAcquire
返回true
加锁成功,不在执行后续方法
返回false
调用addWaiter
调用AcquireQueued
unlock解锁
真正调用的是sync.release方法
该方法会唤醒第一个排队线程,并且把排队线程的上一个节点的ownerThread置为null,然后让head指向该节点
ReentrantLock
可重入可中断锁,他是Lock最重要的实现类之一
FairSync()这个方法是公平锁,调用NonfairSync()方法是非公平锁
CountDownLatch(减法计数器)
用法
创建该对象的时候可以传入一个数值,每次调用countDown就会减一,计数器为零的时候await才不会阻塞
CyclicBarrier(加法计数器)
用法
创建该对象的时候需要设置一个值,并且可以写一个实现Runnable的类,每次调用await就会加1,当加到设定的值后就会触发实现Runnable类的线程开启
Semaphore(信号量)
用法
可以用来做多线程限流,创建该对象的时候可以传入一个资源数量,每次调用acquire就会减少一个资源,资源为零的时候在调用该方法会导致他的线程进入阻塞状态,除非调用release释放锁。
读写锁ReentrantReadWriteLock
读锁和写锁互斥
写锁与写锁互斥
读锁和读锁可以共存
演示
阻塞队列
详情参考容器中的BlockingQueue
SynchronousQueue
容量为一的同步队列
线程池
阿里巴巴开发规范中不允许使用Executors去创建线程池,而是推荐使用ThreadPoolExecutor的方式创建
三大方法
Executors.newSingleThreadExecutor();// 单个线程
Executors.newFixedThreadPool(5); // 创建一个固定的线程池的大小
Executors.newCachedThreadPool(); // 可伸缩
七大参数
int corePoolSize, // 核心线程池大小
int maximumPoolSize, // 最大核心线程池大小
long keepAliveTime, // 超时了没有人调用就会释放
TimeUnit unit, // 超时单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 线程工厂:创建线程的,一般不用动
RejectedExecutionHandler handle // 拒绝策略
4种拒绝策略
假设现在有一个银行,银行的窗口就是线程,进来办理业务的人就是task
new ThreadPoolExecutor.AbortPolicy() // 满了,还有人进来,不处理这个人的,抛出异常
new ThreadPoolExecutor.CallerRunsPolicy() // 哪来的去哪里!
new ThreadPoolExecutor.DiscardPolicy() //队列满了,丢掉任务,不会抛出异常!
new ThreadPoolExecutor.DiscardOldestPolicy() //队列满了,尝试去和最早的竞争,也不会抛出常!
ForkJoin
Future
Excutors
Executors.newCachedThreadPool()
备注:该线程池中的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程,若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
用途:创建一个具有缓存功能的线程池,系统根据需要创建线程,这些线程会被缓存在线程池中。
Executors.newFixedThreadPool(1)
备注:该线程池中的线程数量始终不变,当有一个新的任务提交时,线程中若有空闲线程,则立即执行,若没有则空闲线程,新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
用途:创建一个可重用的、具有固定线程数的线程池。
Executors.newSingleThreadExecutor()
备注:该线程池中的线程数量为 1。
用途:创建一个只有一个线程的线程池,相当于 newFixedThreadPool(int nThreads) 方法调用时传入的参数为 1。
Executors.newScheduledThreadPool(1)
备注:线程池大小为 1,并且可以在固定的延时之后执行或者周期性执行某个任务。
用途:创建只有一条线程的线程池,它可以在指定延迟后执行线程任务。
Executors.newSingleThreadScheduledExecutor()
备注:corePoolSize 指池中所保存的线程数,即使线程是空闲的,也被保存在线程池内。
用途:创建具有指定线程数的线程池,它可以在指定延迟后执行线程任务。
ThreadPoolExecutor
corePoolSize:指定线程池中的线程数量;
maximumPoolSize:指定线程池中的最大线程数量;
keepAliveTime:当线程池中线程数量超过 corePoolSize 时,空闲线程的存活时间;
unit:keepAliveTime 的单位;
threadFactory:线程工厂,用于创建线程,一般用默认的即可;
handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
new ThreadPoolExecutor.CallerRunsPolicy() :
只要线程池没关闭,该策略直接在调用者的线程中,运行当前被丢弃的任务
只要线程池没关闭,该策略直接在调用者的线程中,运行当前被丢弃的任务
new ThreadPoolExecutor.AbortPolicy()
直接抛出异常,阻止系统正常功能
直接抛出异常,阻止系统正常功能
new ThreadPoolExecutor.DiscardPolicy()
该策略默默丢弃无法处理的任务 不予以处理
该策略默默丢弃无法处理的任务 不予以处理
new ThreadPoolExecutor.DiscardOldestPolicy()
该策略丢弃最老的一个请求
该策略丢弃最老的一个请求
workQueue:任务队列,存放提交尚未被执行的任务;
常见问题
并发工具
问题:
如何实现一个流控程序,用于控制请求的调用次数?
如何实现一个流控程序,用于控制请求的调用次数?
答案:
Guava 的 令牌桶实现(生产者/消费者 队列 )
Guava 的 令牌桶实现(生产者/消费者 队列 )
多线程
java中有几种方法可以实现一个线程?
继承Thread类创建线程
实现Runnable接口创建线程
使用Callable和FutureTask创建线程
Callable定义的方法是call,而Runnable定义的方法是run。
Callable的call方法可以有返回值,而Runnable的run方法不能有返回值。
Callable的call方法可抛出异常,而Runnable的run方法不能抛出异常。
Callable的call方法可以有返回值,而Runnable的run方法不能有返回值。
Callable的call方法可抛出异常,而Runnable的run方法不能抛出异常。
如何停止一个正在运行的线程?
使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的方法。
使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
使用interrupt方法中断线程。
notify()和notifyAll()有什么区别?
notify():
唤醒一个处于等待状态的线程,
注意的是在调用此方法的时候,
并不能确切的唤醒某一个等待状态的线程,
而是由JVM确定唤醒哪个线程,而且不是按优先级。
唤醒一个处于等待状态的线程,
注意的是在调用此方法的时候,
并不能确切的唤醒某一个等待状态的线程,
而是由JVM确定唤醒哪个线程,而且不是按优先级。
notifyAll():
唤醒所有处入等待状态的线程;
并可以理解为把他们排进一个队列;
只不过只有头部的线程获得了锁,才能运行;
注意!!并不是给所有唤醒线程一个对象的锁,而是让它们竞争,
当其中一个线程运行完就开始运行下一个已经被唤醒的线程,因为锁已经转移了。
唤醒所有处入等待状态的线程;
并可以理解为把他们排进一个队列;
只不过只有头部的线程获得了锁,才能运行;
注意!!并不是给所有唤醒线程一个对象的锁,而是让它们竞争,
当其中一个线程运行完就开始运行下一个已经被唤醒的线程,因为锁已经转移了。
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
sleep()和 wait()有什么区别?
sleep()是线程类(Thread)的方法,不涉及线程通信,调用时会暂停此线程指定的时间,但监控依然保持,不会释放对象锁,到时间自动恢复;
wait()是Object的方法,用于线程间的通信,调用时会放弃对象锁,进入等待队列,待调用notify()/notifyAll()唤醒指定的线程或者所有线程,才进入对象锁定池准备获得对象锁进入运行状态。
wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用(使用范围)。
sleep()方法必须捕获异常InterruptedException,而wait()\notify()以及notifyAll()不需要捕获异常。
sleep方法只让出了CPU,而并不会释放同步资源锁。
线程执行sleep()方法后会转入阻塞状态。
sleep()方法指定的时间为线程不会运行的最短时间。因此,sleep()方法不能保证该线程睡眠到期后就开始执行。
notify的作用相当于叫醒睡着的人,而并不会给他分配任务,就是说notify只是让之前调用wait的线程有权利重新参与线程的调度。
什么是Daemon线程?它有什么意义?
守护线程与普通线程的唯一区别是:当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;
如果还有一个或以上的非守护线程则不会退出。(以上是针对正常退出,调用System.exit则必定会退出)
JVM 的垃圾回收线程就是 Daemon 线程,Finalizer 也是守护线程。
Thread 的 setDaemon 方法设置现称为守护线程 必须在线程启动之前调用,
当你在一个守护线程中产生了其他线程,那么这些新产生的线程不用设置Daemon属性,都将是守护线程,用户线程同样。
意义 JVM不需要等待它退出,让JVM喜欢什么退出就退出吧,不用管它。
java如何实现多线程之间的通讯和协作?
等待、通知唤醒
锁机制
同步机制
ThreadLocal类
通讯
使用全局变量
共享内存
java中线程的6个状态
NEW 新生
RUNNABLE 运行
BLOCKED 阻塞
WAITING 等待
TIMED_WAITING 超时等待
TERMINATED 终止
锁
什么是可重入锁(ReentrantLock)?
可重入锁,也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。
JAVA环境下 ReentrantLock 和synchronized 都是 可重入锁
可重入锁最大的作用是避免死锁
什么时候应该使用可重入锁?
当一个线程进入某个对象的一个synchronized的实例方法后,其它线程是否可进入此对象的其它方法?
不能
synchronized和java.util.concurrent.locks.Lock的异同?
Lock 能完成synchronized所实现的所有功能;
ReentrantLock
ReadWriteLock
ReentrantReadWriteLock
Lock有比synchronized更精确的线程语义和更好的性能,而且不强制性的要求一定要获得锁
synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且最好在finally 块中释放(这是释放外部资源的最好的地方)。
乐观锁和悲观锁的理解及如何实现,有哪些实现方式?
理解
乐观锁和悲观锁是两种思想,用于解决并发场景下的数据竞争问题。
乐观锁:乐观锁在操作数据时非常乐观,认为别人不会同时修改数据。因此乐观锁不会上锁,只是在执行更新的时候判断一下在此期间别人是否修改了数据:如果别人修改了数据则放弃操作,否则执行操作。
悲观锁:悲观锁在操作数据时比较悲观,认为别人会同时修改数据。因此操作数据时直接把数据锁住,直到操作完成后才会释放锁;上锁期间其他人不能修改数据。
实现
悲观锁
加锁,加锁既可以是对代码块加锁(如Java的synchronized关键字),也可以是对数据加锁(如MySQL中的排它锁)。
乐观锁
CAS机制
CAS操作包括了3个操作数:
需要读写的内存位置(V)
进行比较的预期值(A)
拟写入的新值(B)
需要读写的内存位置(V)
进行比较的预期值(A)
拟写入的新值(B)
如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
CAS是由CPU支持的原子操作,其原子性是在硬件层面进行保证的。
缺点
高竞争下的开销问题
在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
在并发冲突概率大的高竞争环境下,如果CAS一直失败,会一直重试,CPU开销较大。针对这个问题的一个思路是引入退出机制,如重试次数超过一定阈值后失败退出。当然,更重要的是避免在高竞争环境下使用乐观锁。
功能限制
CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;(2)当涉及到多个变量(内存值)时,CAS也无能为力。
CAS的功能是比较受限的,例如CAS只能保证单个变量(或者说单个内存值)操作的原子性,这意味着:(1)原子性不一定能保证线程安全,例如在Java中需要与volatile配合来保证线程安全;(2)当涉及到多个变量(内存值)时,CAS也无能为力。
ABA问题
版本号机制
在数据中增加一个字段version,表示该数据的版本号,每当数据被修改,版本号加1。当某个线程查询数据时,将该数据的版本号一起查出来;当该线程更新数据时,判断当前版本号与之前读取的版本号是否一致,如果一致才进行操作。
例子
AtomicInteger
AtomicReference
........
相关铺垫
公平锁和非公平锁
https://www.jianshu.com/p/f584799f1c77
ReentrantLock 默认采用非公平锁,除非在构造方法中传入参数 true 。
公平锁
严格遵守先来先用
非公平锁
对于非公平锁,只要线程进入了等待队列,队列里面依然是FIFO的原则,跟公平锁的顺序是一样的。因为公平锁与非公平锁的release()部分代码是共用AQS的代码。
队列开头的回合还没进入队列但是申请锁的进行竞争,还没进入队列的拿到了锁 避免线程上下文切换开销
公平和非公平锁的队列都基于锁内部维护的一个双向链表,表结点Node的值就是每一个请求当前锁的线程。公平锁则在于每次都是依次从队首取值
非公平锁在等待锁的过程中, 如果有任意新的线程妄图获取锁,都是有很大的几率直接获取到锁的
(在ReentrantLock中很明显可以看到其中同步包括两种,分别是公平的FairSync和非公平的NonfairSync。公平锁的作用就是严格按照线程启动的顺序来执行的,不允许其他线程插队执行的;而非公平锁是允许插队的。
默认情况下ReentrantLock是通过非公平锁来进行同步的,包括synchronized关键字都是如此,因为这样性能会更好。因为从线程进入了RUNNABLE状态,可以执行开始,到实际线程执行是要比较久的时间的。而且,在一个锁释放之后,其他的线程会需要重新来获取锁。其中经历了持有锁的线程释放锁,其他线程从挂起恢复到RUNNABLE状态,其他线程请求锁,获得锁,线程执行,这一系列步骤。如果这个时候,存在一个线程直接请求锁,可能就避开挂起到恢复RUNNABLE状态的这段消耗,所以性能更优化)
非公平锁在等待锁的过程中, 如果有任意新的线程妄图获取锁,都是有很大的几率直接获取到锁的
(在ReentrantLock中很明显可以看到其中同步包括两种,分别是公平的FairSync和非公平的NonfairSync。公平锁的作用就是严格按照线程启动的顺序来执行的,不允许其他线程插队执行的;而非公平锁是允许插队的。
默认情况下ReentrantLock是通过非公平锁来进行同步的,包括synchronized关键字都是如此,因为这样性能会更好。因为从线程进入了RUNNABLE状态,可以执行开始,到实际线程执行是要比较久的时间的。而且,在一个锁释放之后,其他的线程会需要重新来获取锁。其中经历了持有锁的线程释放锁,其他线程从挂起恢复到RUNNABLE状态,其他线程请求锁,获得锁,线程执行,这一系列步骤。如果这个时候,存在一个线程直接请求锁,可能就避开挂起到恢复RUNNABLE状态的这段消耗,所以性能更优化)
Java互斥锁
互斥是进程同步关系的一种特殊情况,相当于只存在一个临界资源,因此同时最多只能给一个线程提供服务。但是,在实际复杂的多线程应用程序中,可能存在多个临界资源,这时候我们可以借助Semaphore信号量来完成多个临界资源的访问。
并发框架
SynchronizedMap和ConcurrentHashMap有什么区别?
SynchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步
ConcurrentHashMap的实现却更加精细,它对map中的所有桶加了锁。所以,只要有一个线程访问map,其他线程就无法进入map,而如果一个线程在访问ConcurrentHashMap某个桶时,其他线程,仍然可以对map执行某些操作。CAS算法
CopyOnWriteArrayList可以用于什么应用场景?
多读少写的场景
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
线程安全
什么叫线程安全?servlet是线程安全吗?
Servlet不是线程安全的
线程安全就是说多线程访问同一代码,不会产生不确定的结果。
同步有几种实现方法?
Java基础 -> 多线程 -> 线程安全 -> 线程同步
为什么代码会重排序?
一个是编译器编译的的时候,一个是处理器运行的时候。
指令重排使得具有相似功能单元的指令接连执行来减少流水线中断的情况。
volatile有什么用?能否用一句话说明下volatile的应用场景?
作为指令关键字,确保本条指令不会因编译器的优化而省略,且要求每次直接读值,即不是从寄存器里取备份值,而是去该地址内存存储的值。
对变量的写操作不依赖于当前值且该变量没有包含在具有其他变量的不变式中。
理解
立即可见
立即可见
请说明下java的内存模型及其工作流程。
Java内存模型规范了Java虚拟机与计算机内存是如何协同工作的。
Java虚拟机是一个完整的计算机的一个模型,因此这个模型自然也包含一个内存模型——又称为Java内存模型。
知识点
调用栈和本地变量存放在线程栈上,对象存放在堆上
一个本地变量可能是原始类型,在这种情况下,它总是“呆在”线程栈上。
一个本地变量也可能是指向一个对象的一个引用。在这种情况下,引用(这个本地变量)存放在线程栈上,但是对象本身存放在堆上。
一个对象可能包含方法,这些方法可能包含本地变量。这些本地变量任然存放在线程栈上,即使这些方法所属的对象存放在堆上。
一个对象的成员变量可能随着这个对象自身存放在堆上。不管这个成员变量是原始类型还是引用类型。
静态成员变量跟随着类定义一起也存放在堆上。
存放在堆上的对象可以被所有持有对这个对象引用的线程访问。
当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。
如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
与硬件关联
并发容器和框架
如何让一段程序并发的执行,并最终汇总结果?
使用CyclicBarrier 在多个关口处将多个线程执行结果汇总, CountDownLatch 在各线程执行完毕后向总线程汇报结果。
CyclicBarrier : N个线程相互等待,任何一个线程完成之前,所有的线程都必须等待。
CountDownLatch : 一个线程(或者多个), 等待另外N个线程完成某个事情之后才能执行。
如何合理的配置java线程池?如CPU密集型的任务,基本线程池应该配置多大?IO密集型的任务,基本线程池应该配置多大?用有界队列好还是无界队列好?任务非常多的时候,使用什么阻塞队列能获取最好的吞吐量?
java线程池参数 参考 ThreadPoolExecutor
如果是CPU密集型应用,则线程池大小设置为N+1。
如果是IO密集型应用,则线程池大小设置为2N+1。
1. 有界队列有助于避免资源耗尽的情况发生。但他带来了新的问题:当队列填满后,新的任务怎么办?所以有界队列适用于执行比较耗资源的任务,同时要设计好相应的饱和策略。
2. 无界队列和有界队列刚好相反,在资源无限的情况下可以一直接收新任务。适用于小任务,请求和处理速度相对持平的状况。
3. 其实还有一种同步移交的队列 SynchronousQueue ,这种队列不存储任务信息,直接将任务提交给线程池。可以理解为容量只有1的有界队列,在特殊场景下有特殊作用,同样得设计好相应的饱和策略。
2. 无界队列和有界队列刚好相反,在资源无限的情况下可以一直接收新任务。适用于小任务,请求和处理速度相对持平的状况。
3. 其实还有一种同步移交的队列 SynchronousQueue ,这种队列不存储任务信息,直接将任务提交给线程池。可以理解为容量只有1的有界队列,在特殊场景下有特殊作用,同样得设计好相应的饱和策略。
如何使用阻塞队列实现一个生产者和消费者模型?请写代码。
多读少写的场景应该使用哪个并发容器,为什么使用它?比如你做了一个搜索引擎,搜索引擎每次搜索前需要判断搜索关键词是否在黑名单里,黑名单每天更新一次。
CopyOnWriteArrayList、CopyOnWriteArraySet
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
Java中的锁
如何实现乐观锁(CAS)?如何避免ABA问题?
查看 多线程 -> 常见问题 -> 锁 -> 乐观锁 -> CAS
读写锁可以用于什么应用场景?
比如网上共享白板,共享文档等都适用。
读写锁逻辑:
1. 当读写锁是写加锁状态时, 在这个锁被解锁之前, 所有试图对这个锁加锁的线程都会被阻塞。
2. 当读写锁在读加锁状态时, 所有试图以读模式对它进行加锁的线程都可以得到访问权,但是以写模式对它进行枷锁的线程将阻塞。
3. 当读写锁在读模式锁状态时, 如果有另外线程试图以写模式加锁, 读写锁通常会阻塞随后的读模式锁请求, 这样可以避免读模式锁长期占用, 而等待的写模式锁请求长期阻塞。
读写锁逻辑:
1. 当读写锁是写加锁状态时, 在这个锁被解锁之前, 所有试图对这个锁加锁的线程都会被阻塞。
2. 当读写锁在读加锁状态时, 所有试图以读模式对它进行加锁的线程都可以得到访问权,但是以写模式对它进行枷锁的线程将阻塞。
3. 当读写锁在读模式锁状态时, 如果有另外线程试图以写模式加锁, 读写锁通常会阻塞随后的读模式锁请求, 这样可以避免读模式锁长期占用, 而等待的写模式锁请求长期阻塞。
什么场景下可以使用volatile替换synchronized?
状态标志:把简单地volatile变量作为状态标志,来达成线程之间通讯的目的,省去了用synchronized还要wait,notify或者interrupt的编码麻烦。
替换重量级锁:如果某个变量仅是单次读或者单次写操作,没有复合操作(i++,先检查后判断之类的)就可以用volatile替换synchronized。
并发编程
并发编程模型中的两个关键问题
线程之间如何通信
线程之间如何同步
通信的两种机制
共享内存
消息传递
三个特性
原子性:一个或多个操作在CPU执行过程中不被中断的特性
可见性:一个线程对共享变量的修改,另一个线程能立刻看到
有序性:程序执行的顺序按照代码的先后顺序执行
JMM(java内存模型)
Java的并发采用的是共享内存模型
JMM定义了Java 虚拟机(JVM)在计算机内存(RAM)中的工作方式,它试图屏蔽各种操作系统的内存访问差异,以实现java程序在各种平台下都能达到一致的内存访问效果
JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
synchronized、volatile、LOCK,可以解决可见性问题
8总内存间交互操作
read 把一个变量的值从主内存传输到工作内存
load 在read之后执行,把read得到的值放入工作内存的变量副本中
use 把工作内存中一个变量的值传递给执行引擎。
assign 作用于工作内存的变量,它把一个从执行引擎收到的值赋值给工作内存的变量
store 作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
write 作用于主内存的变量,它把store操作从工作内存中的一个变量的值传送到主内存的变量中
lock 作用于主内存的变量,把一个变量标识为一条线程独占状态
unlock 作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
java内存模型中的重排序
为什么需要指令重排序?
因为指令重排序能够提高性能
指令重排序的种类
编译器优化的重排序
指令级并行的重排序
内存系统的重排序
规则
as-if-serial 不管如何重排序,都必须保证代码在单线程下的运行正确。
带来的问题
解决方案
使用锁同步
在临界区内的代码可以重排序,但是由于互斥特性,其他线程感受不到重排序带来的影响
基于happens-Before规则编程
可以使用内存屏障的方法禁止重排序,我们遵守happens-Before规则底层就是使用了内存屏障
happens-before 规则
程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
volatile 变量规则:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
Happens-Before 规则可以解决有序性问题
线程start()规则:指的是主线程A启动子线程B后,子线程B能看到主线程在启动线程B前的操作。
线程join()规则:指的是线程A调用线程B的interrupt()方法,Happens-Before 于线程B检测中断事件(也就是Thread.interrupted()方法)。这个也很容易理解。
线程的interrupt()规则:指的是线程A调用线程B的interrupt()方法,Happens-Before 于线程B检测中断事件(也就是Thread.interrupted()方法)。这个也很容易理解。
finalize()规则:指的是对象的构造函数执行、结束 Happens-Before 于finalize()方法的开始。
happens-before 与 JMM 的关系
线程同步的方式
synchronized
同步方法
同步代码块
volatile
ThreadLocal
ReentrantLock
使用队列
原子变量
CountDownLatch
IO
Linux网络IO模型
同步和异步,阻塞和非阻塞
ajax的同步异步
ajax属性async 同步异步区别(入门使用级)
同步异步,阻塞非阻塞理解
阻塞和非阻塞,同步和异步
同步阻塞
1.老王用水壶煮水,并且站在那里,不管水开没开,每隔一定时间看看水开了没
同步非阻塞
2.老王还是用水壶煮水,不再傻傻的站在那里看水开,跑去寝室上网,但是还是会每隔一段时间过来看看水开了没有,水没有开就走人
异步阻塞
3.老王这次使用高大上的响水壶来煮水,站在那里,但是不会再每隔一段时间去看水开,而是等水开了,水壶会自动的通知他。
异步非阻塞
4.老王还是使用响水壶煮水,跑到客厅上网去,等着响水壶自己把水煮熟了以后通知他
同步和异步
同步就是烧开水,需要自己去轮询(每隔一段时间去看看水开了没),异步就是水开了,然后水壶会通知你水已经开了,你可以回来处理这些开水了。
同步和异步是相对于操作结果来说,会不会等待结果返回。
同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞
阻塞和非阻塞
阻塞就是说在煮水的过程中,你不可以去干其他的事情,非阻塞就是在同样的情况下,可以同时去干其他的事情
阻塞和非阻塞是相对于线程是否被阻塞
阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回
简述linux同步与异步、阻塞与非阻塞概念以及五种IO模型
聊聊阻塞与非阻塞、同步与异步、I/O模型
阻塞I/O模型
进程会一直阻塞,直到数据拷贝完成
非阻塞IO模型
非阻塞IO通过进程反复调用IO函数(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的
IO复用模型
主要是select和epoll;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听
信号驱动IO
两次调用,两次返回
异步IO模型
数据拷贝的时候进程无需阻塞
阻塞调用是指调用结果返回之前,当前线程会被挂起
线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行
函数只有在得到结果之后才会返回
15分钟读懂进程线程、同步异步、阻塞非阻塞、并发并行
阻塞I/O(Blocking I/O)
进程会一直阻塞,直到数据拷贝完成
非阻塞I/O (NonBlocking I/O)
非阻塞IO通过进程反复调用IO函数(多次系统调用,并马上返回);在数据拷贝的过程中,进程是阻塞的
I/O复用(I/O Multiplexing)
主要是select和epoll;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听
信号驱动I/O (SIGIO)
两次调用,两次返回
异步I/O (Asynchronous I/O )
数据拷贝的时候进程无需阻塞
BIO编程
传统的BIO编程
网络编程的基本模型是C/S模型,即两个进程间的通信。
服务端提供IP和监听端口,客户端通过连接操作想服务端监听的地址发起连接请求,通过三次握手连接,如果连接成功建立,双方就可以通过套接字进行通信。
传统的同步阻塞模型开发中,ServerSocket负责绑定IP地址,启动监听端口;Socket负责发起连接操作。连接成功后,双方通过输入和输出流进行同步阻塞式通信。
BIO的服务端通信模型
采用BIO通信模型的服务端,通常由一个独立的Acceptor线程负责监听客户端的连接
它接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理没处理完成后,通过输出流返回应答给客户端,线程销毁
典型的一请求一应答通信模型
最大的问题
当客户端并发访问量增加后,服务端的线程个数和客户端并发访问数呈1:1的正比关系,Java中的线程也是比较宝贵的系统资源,线程数量快速膨胀后,系统的性能将急剧下降,随着访问量的继续增大,系统最终就死-掉-了
伪异步I/O编程
如果使用CachedThreadPool线程池,其实除了能自动帮我们管理线程(复用),看起来也就像是1:1的客户端线程数模型
使用FixedThreadPool我们就有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N:M的伪异步I/O模型。
最大的问题
读取数据较慢时(比如数据量大、网络传输慢等),大量并发的情况下,其他接入的消息,只能一直等待,这就是最大的弊端。
NIO就能解决这个难题
常见操作
磁盘操作:File
字节操作:InputStream 和 OutputStream
字符操作:Reader 和 Writer
对象操作:Serializable
网络操作:Socket
新的输入/输出:NIO和AIO
NIO
NIO是指JDK1.4开始提供的新的api,他是一个非阻塞面向缓冲区的高性能IO
如果理解NIO是面向缓冲区的呢?
NIO和BIO的区别
NIO是面向块的BIO是面向流的
NIO是非阻塞的,BIO是阻塞的
非阻塞的有什么用?
直接缓冲区与非直接缓冲区
非直接缓冲区需要经过一个copy的阶段从内核空间copy到用户空间
直接缓冲区不需要经过copy阶段
使用直接缓冲区的两种方式
使用ByteBuffer的allocateDirect方法
使用FileChannel的map方法
NIO的三个核心部分
buffer缓冲区
本质
数组
状态变量
capacity 最大容量
position 当前已经读写的字节数
还可以读写的字节数
常用实现
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
Channel管道
管道的理解
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。可以理解为管道就是火车道,缓冲区就是火车。
常用管道
FileChannel 从文件中读写数据。
DatagramChannel 能通过UDP读写网络中的数据。
SocketChannel 能通过TCP读写网络中的数据。
ServerSocketChannel可以监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel
管道和流的区别
管道可以同时进行读写,而流只能读或者只能写
管道可以实现异步读写数据
管道可以从缓冲读数据,也可以写数据到缓冲
Selector选择器
一个组件,可以检测多个NIO channel,看看读或者写事件是否就绪。
多个Channel以事件的方式可以注册到同一个Selector,从而达到用一个线程处理多个请求成为可能。
多个Channel以事件的方式可以注册到同一个Selector,从而达到用一个线程处理多个请求成为可能。
Java IO编程全解(四)——NIO编程
创建NIO服务端的主要步骤
1.打开ServerSocketChannel,监听客户端连接
2.绑定监听端口,设置连接为非阻塞模式
3.创建Reactor线程,创建多路复用器并启动线程
4.将ServerSocketChannel注册到Reactor线程中的Selector上,监听ACCEPT事件
5.Selector轮询准备就绪的key
6.Selector监听到新的客户端接入,处理新的接入请求,完成TCP三次握手,简历物理链路
7.设置客户端链路为非阻塞模式
8.将新接入的客户端连接注册到Reactor线程的Selector上,监听读操作,读取客户端发送的网络消息
9.异步读取客户端消息到缓冲区
10.对Buffer编解码,处理半包消息,将解码成功的消息封装成Task
11.将应答消息编码为Buffer,调用SocketChannel的write将消息异步发送给客户端
常见问题
Buffer是一个对象,包含一些要写入或者读出的数据
在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;
在写入数据时,也是写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
通道 Channel
我们对数据的读取和写入要通过Channel,它就像水管一样,是一个通道。通道不同于流的地方就是通道是双向的,可以用于读、写和同时读写操作。
多路复用器 Selector
Selector提供选择已经就绪的任务的能力
Selector会不断轮询注册在其上的Channel,如果某个Channel上面发生读或者写事件,这个Channel就处于就绪状态,会被Selector轮询出来
然后通过SelectionKey可以获取就绪Channel的集合,进行后续的I/O操作。
一个Selector可以同时轮询多个Channel,因为JDK使用了epoll()代替传统的select实现,所以没有最大连接句柄1024/2048的限制。
所以,只需要一个线程负责Selector的轮询,就可以接入成千上万的客户端
Reactor模式
AIO编程
异步的套接字通道时真正的异步非阻塞I/O,对应于UNIX网络编程中的事件驱动I/O(AIO)。他不需要过多的Selector对注册的通道进行轮询即可实现异步读写,从而简化了NIO的编程模型
Netty
Netty应用
Netty是什么?为什么要用Netty?
第一个Netty程序
Netty核心组件初步了解
Hello,Netty
Netty组件再了解
Channel、EventLoop 和ChannelFuture
ChannelHandler 和ChannelPipeline
内置通信传输模式
ByteBuf
解决粘包,半包问题
编解码器框架
序列化问题
单元测试
Netty进阶和实战
基于Netty的Web服务器
实现UDP通信
WebSocket通信
基于STOMP的SpringBoot
基于Netty
深入Netty
引导过程分析
Channel和Unsafe分析
ChannelPipeline和ChannelHandler分析
EventLoop和EventLoopGroup分析
Future和Promise分析
高性能
高可靠
安全性
Java 网络IO编程总结(BIO、NIO、AIO均含完整实例代码)
各种I/O的对比
I/O的对比
基础框架
测试框架
Junit4j
TestNG
Mockito
JCommander
Guava
缓存
集合[Collections]
不可变集合: 用不变的集合进行防御性编程和性能提升。
新集合类型: multisets, multimaps, tables, bidirectional maps等
强大的集合工具类: 提供java.util.Collections中没有的集合工具
扩展工具类:让实现和扩展集合类变得更容易,比如创建Collection的装饰器,或实现迭代器
基本工具 [Basic utilities]
Throwables:简化了异常和错误的传播与检查
排序: Guava强大的”流畅风格比较器”
常见Object方法: 简化Object方法实现,如hashCode()和toString()
前置条件: 让方法中的条件检查更简单
使用和避免null:null是模棱两可的,会引起令人困惑的错误,有些时候它让人很不舒服。很多Guava工具类用快速失败拒绝null值,而不是盲目地接受
令牌桶
Java 反射机制工具类
数学工具类
发布-订阅模式的组件通信,但组件不需要显式地注册到其他组件中
比Object.hashCode()更复杂的散列实现,并提供布鲁姆过滤器的实现
简化I/O尤其是I/O流和文件的操作,针对Java5和6版本
非常有用的字符串工具,包括分割、连接、填充等操作
并发[Concurrency]
ListenableFuture:完成后触发回调的Future
Service框架:抽象可开启和关闭的服务,帮助你维护服务的状态逻辑
POI
SLF4j
slf4j日志的接口
slf4j日志接口的理解
为什么使用SLF4J而不是Log4J来做Java日志
Java日志框架:slf4j作用及其实现原理
log4j日志的使用
log4j日志的使用
log4j日志级别配置详解
logback日志使用
logback日志的理解
logback日志的使用
Logback的配置和使用(终极)
hibernate-validator
SpringBoot中使用hibernate-validator进行参数校验
JAVA中通过Hibernate-Validation进行参数验证
其他
代码优化
JAVA性能优化:35个小细节让你提升java代码的运行效率
正则表达式
JDBC
①JDBC介绍
Java Data Base Connectivity
它是可以执行SQL语句的Java API
sun公司只是提供了JDBC API【接口】,数据库厂商负责实现
②JDBC编码步骤
导入MySQL或者Oracle驱动包
装载数据库驱动程序(Driver)
获取到与数据库连接(Connection)
获取可以执行SQL语句的对象(Statement)
执行SQL语句(增删改查)
得到执行SQL返回的结果(ResultSet)
关闭连接(close资源)
③写一个简单工具类
由于每次使用JDBC都会有相同的代码:获取Connection、close资源
因此,我们写一个简单的工具类来获取Connecion和close资源。减少重复的代码
driver、url、username、password是经常会变的,写在配置文件上是一种不错的选择
④:PreparedStatment和Statement区别
1.Statement会频繁编译SQL。
1.PreparedStatement可对SQL进行预编译,提高效率,预编译的SQL存储在PreparedStatement对象中
2.Statement对象编译SQL语句时,如果SQL语句有变量,就需要使用分隔符来隔开,如果变量非常多,就会使SQL变得非常复杂。
2.PreparedStatement可以使用占位符,简化sql的编写
3. 正因为Statement对象需要拼接,那么可能会有SQL注入问题
3.PreparedStatement使用占位符,没有SQL注入问题
4.Statement批处理可以 可以向数据库发送不同的SQL语句
4.PreparedStatement批处理只能对同一种类型的SQL语句
⑤API实战
获取自动增长主键列
设置了主键为自动增长的话,我们很多时候在业务上是需要得到主键去进行其他操作的(插入操作)。
通过getGeneratedKeys得到主键列
处理二进制和大文本数据
Oracle
Oracle使用的是BLOB这个字段来进行操作
获取到Oracle的BLOB对象,把二进制数据放到这个指针里面,指针指向BLOB字段
Mysql
使用setCharacterStream()处理大文本
使用setBinaryStream()处理二进制
调用数据库的存储过程
使用的是CallableStatement对象来进行调用
存储过程语法: {call [(,, ...)]}
函数的语法:{?= call [(,, ...)]}
元数据
元数据其实就是数据库,表,列的定义信息
利用元数据可以对我们的工具类再进行抽象和封装,形成更加好用的组件
⑥事务隔离级别
一个SESSION所进行的所有更新操作要么一起成功,要么一起失败
Serializable【可避免脏读,不可重复读,虚读】
Repeatable read【可避免脏读,不可重复读】
Read committed【可避免脏读】
Read uncommitted【级别最低,什么都避免不了】
⑦工具类升级版
有了元数据API基础,我们可以使用策略模式来实现封装
结果集的操作交由调用者来进行实现,而我仅仅定义接口的行为
⑧数据库连接池
原生JDBC频繁地打开、关闭连接造成系统性能低下,因此需要数据库连接池
自己编写数据库连接池
连接使用List集合来进行装载,初始化多个Connection,需要连接时就把集合的元素返回出去
使用动态代理来实现把资源返回给List集合。
开源数据库连接池
C3P0
DBCP
Druid
代码配置分析
src/main/resources
application.properties
application.properties
# 数据源配置
# 初始化大小,最小,最大
# 配置获取连接等待超时的时间
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
# 配置一个连接在池中最小生存的时间,单位是毫秒
# 检测连接是否有效的sql
# PSCache Mysql下建议关闭
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
# 合并多个DruidDataSource的监控数据
# entity扫描的包名
# Mapper.xml所在的位置
# 开启MyBatis的二级缓存
# pagehelper
# 日志配置
src/main/java
com.xxxx
SpringBootStudentMybatisDruidApplication.java
filters
DruidStatFilter.java
DruidStatFilter.java
@WebFilter
DruidStatViewServlet.java
DruidStatViewServlet.java
@WebServlet
druid
DruidDataSourceConfig.java
DruidDataSourceConfig.java
@Configuration
@ConditionalOnClass
(com.alibaba.druid.pool.DruidDataSource.class)
@ConditionalOnProperty
(name = "spring.datasource.type", havingValue = "com.alibaba.druid.pool.DruidDataSource", matchIfMissing = true)
@ServletComponentScan
("com.xiaolyuh.filters")
@Bean
@Primary
DruidDataSourceProperty.java
DruidDataSourceProperty.java
pom.xml
pom.xml
⑨使用dbutils框架
dbutils框架其实就是类似我上面升级版的工具类,它是官方的组件
该类简化了SQL查询,配合ResultSetHandler使用,可以完成大部分的数据库操作,大大减少了代码量
⑩实现分页
mysql
Mysql分页语法:
@start---偏移量,不设置就是从0开始【也就是(currentPage-1)*lineSize】
@length---长度,取多少行数据
@start---偏移量,不设置就是从0开始【也就是(currentPage-1)*lineSize】
@length---长度,取多少行数据
oracle
Oracle分页:
Oracle的分页依赖于ROWNUM这个伪列,ROWNUM主要作用就是产生行号。
分页原理:
1:子查询查出前n行数据,ROWNUM产生前N行的行号
2:使用子查询产生ROWNUM的行号,通过外部的筛选出想要的数据
Mybatis
简介
Mybatis也是ORM框架的一种
使用Mybatis的主要原因是Mybatis比Hibernate的灵活性更高
处理复杂的业务的时候会更加方便
映射文件
Statement的实际位置就等于namespace+StatementId
占位符:
#{}解析传递进来的参数数据
更多脑图和最新原创技术文章可关注公众号:Java3y
${}对传递进来的参数原样拼接在SQL中
主键返回
mysql通过LAST_INSERT_ID()实现
oracle通过序列来实现
resultMap
resultMap我们用来告诉Mybaits如何将返回的查询结果进行封装
如果列名和属性名是完全一致的话,那么我们是可以省略的。但是一般来说都是不一样的,所以往往还是需要resultMap
在resultMap内部还可以使用两个节点标签
association:将关联查询信息映射到一个pojo类中。
collection:将关联查询信息映射到一个list集合中。
如果在集合中还有对象的关系要体现出来的话,那我们只能使用ofType。
如果集合中都是对象本身基本属性了,那么可以使用resultMap
resultType
如果是一个简单的对象(没有引用类型)或者返回简单类型数据,我们就可以直接使用resultType来用了
总的来说,resultMap是用得非常多的一个节点
映射关系
一对一
一对多
多对多
其实我们编好了SQL语句,看看在实际中是否需要拿到关联关系的数据如果需要就配置resultMap-->通过association和collection如果不需要直接返回我们原生的resultMap就行了
Mapper代理
需要实现的规范:
mapper.xml中namespace指定为mapper接口的全限定名
此步骤目的:通过mapper.xml和mapper.java进行关联。
mapper.xml中statement的id就是mapper.java中方法名
mapper.xml中statement的parameterType和mapper.java中方法输入参数类型一致
mapper.xml中statement的resultType和mapper.java中方法返回值类型一致.
Mapper代理返回值问题
如果是返回的单个对象,返回值类型是pojo类型,生成的代理对象内部通过selectOne获取记录
如果返回值类型是集合对象,生成的代理对象内部通过selectList获取记录。
快速入门
主配置文件
配置数据库信息
加载映射文件
映射文件
描述具体方法对应的SQL语句
工作流程
通过Reader对象读取Mybatis映射文件通过SqlSessionFactoryBuilder对象创建SqlSessionFactory对象获取当前线程的SQLSession事务默认开启通过SQLSession读取映射文件中的操作编号,从而读取SQL语句提交事务关闭资源
更多脑图和最新原创技术文章可关注公众号:Java3y
Mybatis的SQL语句是需要手写的,在程序中通过映射文件的命名空间.sql语句的id来进行调用!
动态SQL
Mybatis支持一些判断标签,于是我们就可以通过这些标签来完成动态CRUD的操作了
主配置文件
自定义别名,在映射文件中我们就可以使用别名了
加载映射文件
设置延迟加载
配置数据库的信息
Mybatis配置文件详解
缓存
一级缓存
Mybatis默认是开启一级缓存的
一级缓存是基于sqlSession的缓存
实现原理就是:通过一个Map来实现同一个sqlsession再次发出相同的sql,就从缓存中取不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
与Spring整合之后,使用的是Mappper代理对应,一级缓存是失效的~
同一线程里面两次查询同一数据所使用的sqlsession是不相同的
二级缓存
Mybaits的二级缓存是需要自己在配置文件中配置的
二级缓存是基于Mapper(同一个命名空间)的缓存
查询结果映射的pojo需要实现 java.io.serializable接口
禁用二级缓存
useCache="false"
刷新缓存
执行增删改操作默认是会刷新缓存的,但我们也可以配置不刷新(不建议使用)
flushCache="false"
Mybatis和Ehcache框架整合
优点和缺点
优点:对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度
缺点:因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空
逆向工程
在pom中添加插件
编写自动生成的配置文件
如果出错了,注意版本的问题
mybatis - 动态SQL
Spring
容器
AnnotationConfigApplicationContext
配置类
包扫描
组件添加
@ComponentScan
@Bean
指定初始化销毁
初始化其他方式
InitializingBean(初始化设置值之后)
DisposableBean(销毁)
JSR250
@PostConstruct
@PreDestroy
BeanPostProcessor
@Configuration
@Component
@Service
@Controller
@Repository
@Conditional
@Primary
@Lazy
@Scope
@Import
ImportSelector
工厂模式
FactoryBean
&beanName获取Factory本身
组件赋值
@Value
@Autowired
@Qualifier
其他方式
@Resources(JSR250)
@Inject(JSR330,需要导入javax.inject)
@PropertySource
@PropertySources
组件注入
方法参数
构造器注入
ApplicationContextAware
ApplicationContextAwareProcessor
xxxAware
BeanDefinitionRegistryPostProcessor
BeanFactoryPostProcessor子类,可自定义添加bean定义
BeanDefinetionRegistry
BeanDefinetionBuilder
声明式事务源码解读
@EnableTransactionManagement
@Transactional
声明式事务-环境搭建
声明式事务-测试成功
声明式事务-源码分析
Spring容器源码解读
BeanFactory预准备
执行BeanFactoryPostProcessor
注册BeanPostProcessors
初始化MessageSource
初始化事件派发器、监听器等
创建Bean准备
Bean创建完成
容器创建完成
IOC
IOC的基本思路
IOC是什么
如何使用
IOC是大的map对象
IOC是大的map对象
tomcat启动时加载springmvc的war包过程
tomcat启动时加载springmvc的war包过程
BeanFactory与FactoryBean的区别
BeanFactory与FactoryBean的区别
BeanFactory,以Factory结尾,表示它是一个工厂类(接口),用于管理Bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。
以Bean结尾,表示它是一个Bean,不同于普通Bean的是:它是实现了FactoryBean<T>接口的Bean,根据该Bean的ID从BeanFactory中获取的实际上是FactoryBean的getObject()返回的对象,而不是FactoryBean本身,如果要获取FactoryBean对象,请在id前面加一个&符号来获取。
Spring为此提供了一个.FactoryBean的工厂类接口,用户可以通过实现该接口定制实例化Bean的逻辑。在IOC容器的基础上给Bean的实现加上了一个简单工厂模式和装饰模式
BeanFactory 简介以及它 和FactoryBean的区别(阿里面试)
BeanFactory和FactoryBean区别及类装载源码解读
springbean的生命周期
Spring Bean的生命周期(非常详细)
JAVA面试题:Spring中bean的生命周期
Spring bean的生命周期,对比源码详解
Spring:源码解读Spring IOC原理
最详细的Spring核心IOC的源码分析
@Configuration和@Bean的用法和理解
Spring IOC容器初始化过程学习
IoC容器的初始化过程可以分为三步
1.Resource定位(Bean的定义文件定位)
2.将Resource定位好的资源载入到BeanDefinition
3.将BeanDefiniton注册到容器中
spring的源码解读
源码解读(一):spring在web容器中的初始化过程
源码解读(二): spring容器初始化的refresh操作
Spring:源码解读Spring IOC原理
Spring容器初始化过程
AbstractApplicationContext的refresh函数载入Bean定义过程
afterPropertiesSet的使用
简单比较init-method,afterPropertiesSet和BeanPostProcessor
从源码实现的角度解析spring的InitializingBean的afterPropertiesSet方法和init-method区别和应用
AOP
@EnableAspectJAutoProxy
@Before/@After/@AfterReturning/@AfterThrowing/@Around
@Pointcut
AOP源码解读
AnnotationAwareAspectJAutoProxyCreator分析
注册AnnotationAwareAspectJAutoProxyCreator
AnnotationAwareAspectJAutoProxyCreator执行时机
创建AOP代理
获取拦截器链-MethodInterceptor
链式调用通知方法
常见问题
关于 Spring AOP (AspectJ) 你该知晓的一切
jdk动态代理与cglib代理、spring aop代理实现原理
Spring实现AOP的多种方式
springAOP详解
springAOP源码
spring源码解读 AOP原理
Spring源码学习【六】AOP原理解析(一)代理对象的生成
springAOP原理
关于 Spring AOP (AspectJ) 你该知晓的一切
jdk动态代理与cglib代理、spring aop代理实现原理
Spring实现AOP的多种方式
springAOP详解
springAOP源码
spring源码解读 AOP原理
Spring源码学习【六】AOP原理解析(一)代理对象的生成
MVC
springMVC的教程
springMVC的功能
springMVC的功能和优点
springMVC的思想
SpringMVC、Tomcat怎样完成一次Http请求的?
深入理解springMVC 思想
SpringMVC工作原理
SPRINGMVC工作原理图解
springMVC的搭建
史上最全最强SpringMVC详细示例实战教程
springMVC的注解
@requestbody使用
springmvc常用注解标签详解
Controller / RestController
RequestMapping
Resource / Autowired
@Qualifier
@Resource装配顺序:
①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
②如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
③如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
④如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入。
①如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
②如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常。
③如果指定了type,则从上下文中找到类似匹配的唯一bean进行装配,找不到或是找到多个,都会抛出异常。
④如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配。
@Resource的作用相当于@Autowired,只不过@Autowired按照byType自动注入。
Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。
ModelAttribute / SessionAttributes
PathVariable
requestParam
ResponseBody
Component
Repository
Service
@requestbody使用
SpringMVC @RequestBody 处理ajax请求
SpringMVC接收json格式的多个对象参数(变通法)
SpringBoot中使用多个@RequestBody的正确姿势
JSON字符串与JSON对象的区别
@SessionAttributes使用
SpringMVC @SessionAttributes 使用详解以及源码分析
springMVC的异步
springMVC的异步处理
高性能的关键:Spring MVC的异步模式
异步请求
servlet3.0异步处理
返回Callable
返回DeferredResult
springMVC的源码
springmvc依赖包
简单的SpringMVC框架需要引用的jar包[Spring4]
SpringMVC最小依赖包
springmvc工作原理以及源码分析(基于spring3.1.0)
spring源码分析之spring-web web模块分析
WebMvcConfigurer
Spring boot 梳理 - WebMvcConfigurer接口 使用案例
servlet3.0
ServletContainerInitializer
Registration
ServletRegistration
FilterRegistration
ServletContext
事务管理
基于AOP实现
事务的注解配置
把一个DataSource(如DruidDataSource)作为一个@Bean注册到Spring容器中,配置好事务性资源。
把一个@EnableTransactionManagement注解放到一个@Configuration类上,配置好事务管理器,并启用事务管理。
把一个@Transactional注解放到类上或方法上,可以设置注解的属性,表明该方法按配置好的属性参与到事务中。
把一个@EnableTransactionManagement注解放到一个@Configuration类上,配置好事务管理器,并启用事务管理。
把一个@Transactional注解放到类上或方法上,可以设置注解的属性,表明该方法按配置好的属性参与到事务中。
回滚事务
抛出一个未捕获的异常
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()
配置回滚异常
使用@Transactional注解的rollbackFor/rollbackForClassName属性,可以精确配置导致回滚的异常类型,包括checked exceptions。
noRollbackFor/noRollbackForClassName属性,可以配置不导致回滚的异常类型,当遇到这样的未处理异常时,照样提交相关事务。
@Transactional 加于private方法, 无效
@Transactional 加于未加入接口的public方法, 再通过普通接口方法调用, 无效
@Transactional 加于接口方法, 无论下面调用的是private或public方法, 都有效
@Transactional 加于接口方法后, 被本类普通接口方法直接调用, 无效
@Transactional 加于接口方法后, 被本类普通接口方法通过接口调用, 有效
@Transactional 加于接口方法后, 被它类的接口方法调用, 有效
@Transactional 加于接口方法后, 被它类的私有方法调用后, 有效
@Transactional 加于未加入接口的public方法, 再通过普通接口方法调用, 无效
@Transactional 加于接口方法, 无论下面调用的是private或public方法, 都有效
@Transactional 加于接口方法后, 被本类普通接口方法直接调用, 无效
@Transactional 加于接口方法后, 被本类普通接口方法通过接口调用, 有效
@Transactional 加于接口方法后, 被它类的接口方法调用, 有效
@Transactional 加于接口方法后, 被它类的私有方法调用后, 有效
隔离级别
DEFAULT,READ_UNCOMMITTED,READ_COMMITTED,REPEATABLE_READ,SERIALIZABLE
DEFAULT
使用底层数据存储的默认隔离级别。MySQL的默认隔离级别是REPEATABLE-READ。
READ_UNCOMMITTED
读未提交。脏读、不可重复读、幻读都会发生。
READ_COMMITTED
读已提交。脏读不会发生,不可重复读、幻读都会发生。
REPEATABLE_READ
可重复读。脏读、不可重复读都不会发生,幻读会发生。
SERIALIZABLE
可串行化。脏读、不可重复读、幻读都不会发生。
传播特性
1. PROPAGATION_REQUIRED:支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。
2. PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。
3. PROPAGATION_MANDATORY:支持当前事务,如果当前没有事务,就抛出异常。
4. PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起。
5. PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
6. PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
7. PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚。
2. PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。
3. PROPAGATION_MANDATORY:支持当前事务,如果当前没有事务,就抛出异常。
4. PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起。
5. PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
6. PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
7. PROPAGATION_NESTED:支持当前事务,新增Savepoint点,与当前事务同步提交或回滚。
1》PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:它们非常类似,都像一个嵌套事务,如果不存在一个活动的事务,都会开启一个新的事务。使用 PROPAGATION_REQUIRES_NEW时,内层事务与外层事务就像两个独立的事务一样,一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。两个事务不是一个真正的嵌套事务。同时它需要JTA事务管理器的支持。
2》使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
3》PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
4》另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
5》由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
6》PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
2》使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。DataSourceTransactionManager使用savepoint支持PROPAGATION_NESTED时,需要JDBC 3.0以上驱动及1.4以上的JDK版本支持。其它的JTA TrasactionManager实现可能有不同的支持方式。
3》PROPAGATION_REQUIRES_NEW 启动一个新的, 不依赖于环境的 “内部” 事务. 这个事务将被完全 commited 或 rolled back 而不依赖于外部事务, 它拥有自己的隔离范围, 自己的锁, 等等. 当内部事务开始执行时, 外部事务将被挂起, 内务事务结束时, 外部事务将继续执行。
4》另一方面, PROPAGATION_NESTED 开始一个 “嵌套的” 事务, 它是已经存在事务的一个真正的子事务. 潜套事务开始执行时, 它将取得一个 savepoint. 如果这个嵌套事务失败, 我们将回滚到此 savepoint. 潜套事务是外部事务的一部分, 只有外部事务结束后它才会被提交。
5》由此可见, PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于, PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED 则是外部事务的子事务, 如果外部事务 commit, 嵌套事务也会被 commit, 这个规则同样适用于 roll back.
6》PROPAGATION_REQUIRED应该是我们首先的事务传播行为。它能够满足我们大多数的事务需求。
源码解析
spring的启动流程
springweb容器的初始化过程源码
源码解读(一): spring在web容器中的初始化过程
源码解读(二): spring容器初始化的refresh操作
Spring源码情操陶冶-ContextLoader
Spring源码分析2 — 容器启动流程
spring容器初始化的整个流程图
创建WebApplicationContext对象流程
读取XML配置文件,创建beans流程
Spring源码分析3 — spring XML配置文件的解析流程
Spring源码分析4 — spring bean创建和初始化
Spring源码学习--Bean的生命周期
Spring Bean生命周期详解
Spring Bean 的生命周期
如何深入理解Spring源码中Bean的完整生命周期过程
源码
Spring源码学习--Bean的生命周期
Spring源码分析2-容器启动流程
java web项目启动执行顺序
ServletContextListener和ContextLoaderListener的区别
浅谈ContextLoaderListener及其上下文与DispatcherServlet的区别
ContextLoaderListener 初始化过程
spring容器初始化过程
0.spring中WebApplicationContext、DispatcherServlet与web容器的ServletContext关系梳理
ServletContext
Servlet容器在启动时会加载Web应用,并为每个Web应用创建唯一的ServletContext对象。
ServletContext看作一个Web应用的服务器端组件的共享内存
ServletContext与Spring容器(ApplicationContext)的关系
1.ServletContext创建之后,然后读取web.xml中<context-param></context-param>节点内容
2.触发ServletContextEvent事件,ServletContextListener监听这个事件
ServletContextListener有两个抽象方法,分别是ServletContext初始化时调用方法和ServletContext销毁时调用的方法
3.ContextLoaderListener实继承ContextLoader并实现ServletContextListener,所以也监听ServletContextEvent事件,事件触发后ContextLoaderListener会执行初始化方法。
4.ContextLoaderListener监听ServletContextEvent事件,执行初始化contextInitialized(ServletContextEvent event)方法
0.此方法执行contextLoader的initWebApplicationContext(event.getServletContext());的方法
1.先判断是否已经创建过ApplicationContext;
2.创建WebApplicationContext对象(Spring容器)
this.context = createWebApplicationContext(servletContext);
3.转换成ConfigurableWebApplicationContext 对象;
4.执行configureAndRefreshWebApplicationContext方法
封装ApplicationContext上下文数据
其中会从ServletContext中读取applicationContext.xml配置
调用refresh方法完成所有bean的解析初始化创建
5.ConfigurableWebApplicationContext 创建之后放到ServletContext中
spring中WebApplicationContext、DispatcherServlet与web容器的ServletContext关系梳理
spring 上下文和spring mvc上下文和web应用上下文servletContext之间的关系
总结下ServletContext和ApplicationContext
1.Spring 在web容器中通常是通过在web.xml文件中配置切入点来进行相关初始化的
2.当web容器解析web.xml文件时,会初始化ContextLoaderListener类
这个类实现了ServletContextListener,也就是Web容器监听器;
实现了ServletContextListener接口中的contextInitialized和contextDestroyed方法
contextInitialized 是在容器初始化上下文的时候调用的;
contextDestroyed是容器销毁上下文的时候调用的
继承了ContextLoader
ContextLoaderListener加载过程(最详细版)
3.初始化 ContextLoaderListener类
继承ContextLoader,这个类用来执行根应用程序上下文的实际初始化工作
执行static代码块获取ContextLoader.properties
org.springframework.web.context.WebApplicationContext=org.springframework.web.context.support.XmlWebApplicationContext
通过XmlWebApplicationContext类来进行相应的web上下文初始化
ContextLoader初始化过程中,会通过xml中contextConfigLocation的配置,比如springmvc的配置
ServletContextListener方法contextInitialized(ServletContextEvent event)会执行继承自contextLoader的initWebApplicationContext(ServletContext context)方法
实现ServletContextListener接口
0.spring中WebApplicationContext、DispatcherServlet与web容器的ServletContext关系梳理
1.contextInitialized(ServletContextEvent event),执行继承自ContextLoader中的initWebApplicationContext(ServletContext context)方法,获取webApplication上下文环境
webApplicationContext的作用
javaee标准规定了,servlet容器需要在应用项目启动时,给应用项目初始化一个ServletContext作为公共环境容器存放公共信息;
this.context = createWebApplicationContext(servletContext);
创建WebApplicationContext对象(Spring容器),一般会创建前点所述的XmlWebApplicationContext
XmlWebApplicationContext继承AbstractRefreshableWebApplicationContext
AbstractRefreshableWebApplicationContext实现了ConfigurableWebApplicationContext
XmlWebApplicationContext
loadBeanDefinitions(DefaultListableBeanFactory beanFactory)
initBeanDefinitionReader(XmlBeanDefinitionReader beanDefinitionReader)
loadBeanDefinitions(XmlBeanDefinitionReader reader)
String[] getDefaultConfigLocations()
configureAndRefreshWebApplicationContext(cwac, servletContext);
获取web.xml中配置的contextConfigLocation路径
获取应用的访问路径,获取spring相关的XML配置文件的路径
并且刷新当前的WebApplicationContext配置相关
将该上下文对象放入servlet上下文参数中
最后一步方法refresh操作中设定了BeanFactory,整个bean的生命周期也从这个方法中开始
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
ConfigurableWebApplicationContext 创建之后放到ServletContext中
2.contextDestroyed(ServletContextEvent event)
容器销毁
spring的bean生命周期
spring的bean生命周期从spring容器创建完成后,执行configureAndRefreshWebApplicationContext(cwac, servletContext)的最后一步refresh()方法
AbstractApplicationContext类的refresh()方法解析
prepareRefresh();
refresh之prepareRefresh方法
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
读取并解析spring xml配置文件的入口,spring XML配置文件的解析流程
XmlWebApplicationContext:web应用的默认Spring容器
XmlBeanDefinitionReader:读取XML并解析xml文件
DocumentLoader:文件先被读取为了原始的输入流InputStream,然后封装为InputSource。DocumentLoader加载inputSource,解析后得到Document对象
Document:代表一个XML或者HTML标记文件,包含docType,各种element节点等。
BeanDefinition:XML中bean在spring容器中的表示。Document会被解析为BeanDefinition。在Bean创建和初始化中它们会大展拳脚。
BeanDefinitionDocumentReader:解析Document中的节点元素Element,转换为BeanDefinition,并注册他们到BeanDefinition注册表中。默认实现类为DefaultBeanDefinitionDocumentReader
BeanDefinitionParserDelegate:实际解析Document中的节点元素,采用了代理模式。
refreshBeanFactory();
DefaultListableBeanFactory beanFactory = createBeanFactory();
new DefaultListableBeanFactory,创建容器,设置id,个性化配置等
loadBeanDefinitions(beanFactory);
加载xml配置文件,具体子ApplicationContext会实现它。不同子类实现会不同(重点)
分析web应用中默认的spring容器,也就是XmlWebApplicationContext中的loadBeanDefinitions
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
// 创建XmlBeanDefinitionReader,用它来读取XML配置文件
beanDefinitionReader.setEnvironment(getEnvironment());
// 配置beanDefinitionReader的环境和属性
beanDefinitionReader.setResourceLoader(this);
// ApplicationContext也继承了ResourceLoader接口
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
// entityResolver在parse时会用到
initBeanDefinitionReader(beanDefinitionReader);
// 初始化beanDefinitionReader,子类可以实现这个方法,做一些个性化配置和初始化
loadBeanDefinitions(beanDefinitionReader);
// 开始load xml文件,这一步开始才是真正读取XML文件了。前面都是做一些环境配置之类的事情
String[] configLocations = getConfigLocations();
// 获取XML配置文件的地址,前面讲到过的web.xml中的contextConfigLocation元素,它指明了XML配置文件的地址。如果web.xml中没有配置,则读取默认的地址,参看后面分析
getDefaultConfigLocations()
reader.loadBeanDefinitions(configLocation);
int loadCount = loadBeanDefinitions(resource);
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
// 将Resource对象添加到hashSet中,不是很关键
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
// 加载封装好的inputSource对象,读取XML配置文件。关键步骤,后面分析
Document doc = doLoadDocument(inputSource, resource);
// 加载并解析XML文件,解析方案为社区通用方法,不是Spring所特有的
registerBeanDefinitions(doc, resource);
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
// 反射创建documentReader实例,默认为DefaultBeanDefinitionDocumentReader
int countBefore = getRegistry().getBeanDefinitionCount();
// 获取容器中当前beans数量,已经注册的BeanDefinition会存储在一个Map中,获取Map的size即可。
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
// 注册beanDefinition,这是关键所在,后面分析
Element root = doc.getDocumentElement();
// root为<beans />标签
doRegisterBeanDefinitions(root);
// 采用代理进行解析,代理为BeanDefinitionParserDelegate
BeanDefinitionParserDelegate parent = this.delegate;
//创建代理
preProcessXml(root);
// 解析前的处理,DefaultBeanDefinitionDocumentReader没有实现它,子类可以实现,来扩展功能
parseBeanDefinitions(root, this.delegate);
// 解析root内的XML标签,如<import> <alias> <bean>等
parseDefaultElement(ele, delegate);
// 在默认的命名空间url中的元素,是默认定义好的节点,采用parseDefaultElement方法解析
importBeanDefinitionResource(ele);
// 解析<import>
processAliasRegistration(ele);
// 解析<alias>
processBeanDefinition(ele, delegate);
// 解析<bean>
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// 解析Element为BeanDefinition,这是重点,后面详细分析
String id = ele.getAttribute(ID_ATTRIBUTE);
// 获取bean的id属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 获取bean的name属性
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
String className = null;
// 获取class和parent属性
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 反射实例化bean为GenericBeanDefinition
GenericBeanDefinition bd = new GenericBeanDefinition();
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 解析节点中其他属性,如scope, singleton等。后面详细分析
ele.hasAttribute(SINGLETON_ATTRIBUTE)
// 解析singleton
ele.hasAttribute(SCOPE_ATTRIBUTE)
// 解析scope
parseMetaElements(ele, bd);
// 解析子节点meta属性,如果有的话
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
// 将BeanDefinition注册到BeanDefinitionMap中,key为beanName
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
// 发送注册的消息,相应的监听器就会收到并处理消息了
doRegisterBeanDefinitions(ele);
// 解析<beans>
delegate.parseCustomElement(ele);
// 用户自定义的命名空间url中的元素,采用parseCustomElement方法解析
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
// 根据命名空间url获取具体的NamespaceHandler,比如<context:component-scan>对应的就是用户自定义的ContextNamespaceHandler。
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
// 交给用户自定义的NamespaceHandler来解析用户自定义的CustomElement
parseCustomElement()首先根据自定义标签的命名空间,生成具体的NamespaceHandler。
一般要由用户自己定义,然后调用parse方法进行解析,这个也是用户自定义的。
delegate.parseCustomElement(root);
// 子节点不是标准的Element元素,比如用户自定义的,采用parseCustomElement方法解析
postProcessXml(root);
// 解析后的处理,同样没有实现它,子类可以实现。
prepareBeanFactory(beanFactory);
在完成解析,把所有的BeanDenifition注册到bean工厂完成后,开始执行prepareBeanFactory方法。
这个方法是配置工厂的标准上下文特征
refresh之prepareBeanFactory方法
postProcessBeanFactory(beanFactory);
postProcessBeanFactory后处理beanFactory。时机是在所有的beanDenifition加载完成之后,bean实例化之前执行。
比如,在beanfactory加载完成所有的bean后,想修改其中某个bean的定义,或者对beanFactory做一些其他的配置,就可以用此方法。
refresh之postProcessBeanFactory方法
invokeBeanFactoryPostProcessors(beanFactory);
invokeBeanFactoryPostProcessors执行BeanFactory后置处理器,当然前提是你已经在容器中注册过此处理器了。
refresh之invokeBeanFactoryPostProcessors方法
registerBeanPostProcessors(beanFactory);
registerBeanPostProcessors从名称可以看出是用来注册BeanPostProcessor的
BeanPostProcessor
postProcessBeforeInitialization(Object bean, String beanName)
在bean实例化、依赖注入之后,初始化(显示)之前执行
postProcessAfterInitialization(Object bean, String beanName)
在bean实例化、依赖注入之后,初始化(显示)之后执行
refresh之registerBeanPostProcessors方法
BeanFactoryPostProcessor和BeanPostProcessor的区别
BeanFactoryPostProcessor是用来处理bean工厂或者是bean定义的,BeanPostProcessor是用来处理bean实例的。
initMessageSource();
国际化初始
initApplicationEventMulticaster();
初始化应用事件广播器,这事观察者模式得典型应用。
观察者模式由主题Subject和Observer组成。广播器相当于主题Subject,其包含多个监听器。当主题发生变化时会通知所有得监听器。
refresh之initApplicationEventMulticaster方法
onRefresh();
这个方法是空的,解释是在特定的上下文中初始化特别的beans,可以看到其也是用于初始化的
refresh之onRefresh方法
registerListeners();
注册监听器,与广播器是同时存在的。在广播器章节,spring只是初始化的广播器,但是并没有为广播器绑定Listener。
refresh之registerListeners方法
finishBeanFactoryInitialization(beanFactory);
spring bean创建和初始化
AbstractApplicationContext: 定义了spring容器初始化的大部分流程方法,子类必须遵循这个流程,但可以修改流程中的方法,典型的模板模式。bean创建的入口方法finishBeanFactoryInitialization也在这个方法中。
DefaultListableBeanFactory:一种BeanFactory容器实现,实现了ConfigurableListableBeanFactory接口
BeanDefinition:描述bean结构,对应XML中的或者注解中的@Component
AbstractBeanFactory:继承了BeanFactory容器,主要负责getBean创建Bean实例。
bean初始化的步骤
先执行BeanPostProcessor的postProcessBeforeInitialization方法;然后是bean的afterPropertiesSet;然后是xml的init-method方法;最后BeanPostProcessor的postProcessAfterInitialization方法
BeanFactory实例化Bean相关接口
工厂后处理器接口方法
这些方法也是容器级别的,但它们是在上下文装置配置文件之后调用
BeanFactoryPostProcessor、 CustomAutowireConfigurer等
这里说一点,这些类名都很长,有的也挺相似,学习的话要仔细看清楚哪个是哪个。
Bean自身方法
init-method/destroy-method
通过为配置文件bean定义中添加相应属性指定相应执行方法
Bean级生命周期接口
1.BeanNameAware
void setBeanName(String beanName);
//待对象实例化并设置属性之后调用该方法设置BeanName
2.BeanFactoryAware
DefaultListableBeanFactory void setBeanFactory(BeanFactory var1) ;
//待调用setBeanName之后调用该方法设置BeanFactory
3.InitializingBean
void afterPropertiesSet() throws Exception;
//实例化完成之后调用(调用了BeanPostProcessor.postProcessBeforeInitialization方法之后调用该方法)
4.DisposableBean
void destroy() throws Exception;
//关闭容器时调用
容器级Bean生命周期接口
1、抽象类:InstantiationAwareBeanPostProcessorAdapter
实例化前/后,及框架设置Bean属性时调用该接口。
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName)
//在Bean对象实例化前调用
public boolean postProcessAfterInstantiation(Object bean, String beanName)
//在Bean对象实例化后调用(如调用构造器之后调用)
public PropertyValues postProcessPropertyValues(PropertyValues pvs, PropertyDescriptor[] pds, Object bean, String beanName)
//在设置某个属性前调用,然后再调用设置属性的方法
2、接口BeanPostProcessor
public Object postProcessBeforeInitialization(Object o, String s)
//实例化完成,setBeanName/setBeanFactory完成之后调用该方法
public Object postProcessAfterInitialization(Object o, String s)
//全部是实例化完成以后调用该方法
finishRefresh();
在Spring中还提供了Lifecycle,Lifecycle中包含了start/stop方法
实现此接口后Spring会保证在启动的时候调用其start方法开始生命周期,并在Spring结束的时候调用stop方法来结束生命周期
通常用来配置后台程序,在启动后一直运行。而ApplicationContext的初始化最后正是保证了这一功能的实现。
spring XML配置文件的解析流程
spring XML配置文件的解析流程
spring整体源码解析
Jintao_Ma的博客
Spring 源码梳理(一) ClassPathXmlApplicationContext
Spring 源码梳理(二) BeanPostProcessor
Spring 源码梳理(三) 再谈BeanPostProcessor
Spring 源码梳理(四) BeanFactoryPostProcessor
Spring 源码梳理(五) FactoryBean与BeanFactory
Spring 源码梳理(六) BeanNameAware和BeanFactoryAware
Spring 源码梳理(七) 注解源码
渔潭的博客
spring注解源码解析
springbean的源码
org.springframework.beans.factory.annotation.Autowired.class
spring注解的原理与自定义注解的实现
spring自定义注解源码
设计模式
深入解析spring中用到的九种设计模式
Spring 框架的设计理念与设计模式分析
spring中使用到的设计模式总结
观察者设计模式
1.ApplicationContext是实现ApplicationEventPublisher,ApplicationEventPublisher有一个方法publishEvent方法,注入事件ApplicationEvent的子类,实现事件的触发
策略设计模式
Spring 的代理方式有两个 Jdk 动态代理和 CGLIB 代理。这两个代理方式的使用正是使用了策略模式
代理设计模式
装饰器模式
一种是类名中含有Wrapper,另一种是类名中含有Decorator
工厂方法模式
优点
(1)方便解耦,简化开发(高内聚,低耦合):Spring就是一个大容器,可以将所有对象
创建和依赖关系维护,交给Spring管理.(工厂模式)
(2)AOP编程的支持:Spring提供面向切面编程,可以方便的实现对程序进行权限拦
截、运行监控等功能声明式事务的支持只需要通过配置就可以完成对事务的管理,而无需手动编程
(3)方便集成各种优秀框架:Spring不排斥各种优秀的开源框架,其内部提供了对各
种优秀框架(如:Struts、Hibernate、MyBatis等)的直接支持
(4)降低JavaEE API的使用难度:Spring 对JavaEE开发中非常难用的一些API(JDBC、
JavaMail、远程调用等),都提供了封装,使这些API应用难度大大降低
SpringCloud
SpringBoot
SpringBoot快速入门
SpringBoot与微服务之间的关系
环境搭建
集成springmvc
集成mybatis
整合日志
集成jsp
全局异常捕获
拦截器
springAop对参数拦截
拦截器实例
spring boot使用拦截器(以session校验为例)
过滤器
过滤器注解
@Filter中FilterType包含的类型及意义
过滤器实例
spring boot使用过滤器(以session校验为例)
打包部署
热部署
集成Swagger2构建API管理体系
spring-boot | 多线程并发定时任务
进阶
核心组件
starter
actuator
auto-configuration
cli
性能优化
jvm参数
扫包优化
undertow容器
jta+atomikos分布式事务
SpringBoot核心原理实战
@SpringBootApplication源码解读
纯手写打造SpringBoot雏形
框架整合业务逻辑层
整合jsp视图
内置集成tomcat
常见轮子
1.为什么需要微服务
微服务架构和单体架构
单体架构与微服务的优缺点
单体架构
1.复杂性扩散
2.库的复用与耦合
3.可替代成本较高
微服务
单一职责功能,每个服务都很简单
易于规模化开发,单独团队维护、工作分明,职责清晰
改善故障隔离。一个服务宕机不会影响其他服务
架构上系统更加清晰
微服务架构概念
微服务的4个设计原则和19个解决方案
springCloud和springBoot的关系
微服务与分布式架构的区别
分布式服务架构与微服务架构概念的区别与联系是怎样的?
分布式
不同模块部署在不同服务器上
作用:分布式解决网站高并发带来问题
集群
多台服务器部署相同应用构成一个集群
作用:通过负载均衡设备共同对外提供服务
SOA[组装服务/ESB企业服务总线]
业务系统分解为多个组件,让每个组件都独立提供离散,自治,可复用的服务能力
通过服务的组合和编排来实现上层的业务流程
作用:简化维护,降低整体风险,伸缩灵活
微服务[找到服务/微服务网关open API]
架构设计概念,各服务间隔离(分布式也是隔离),自治(分布式依赖整体组合)其它特性(单一职责,边界,异步通信,独立部署)是分布式概念的跟严格执行
SOA到微服务架构的演进过程
作用:各服务可独立应用,组合服务也可系统应用(巨石应用[monolith]的简化实现策略-平台思想)
springCloud相关认识
springboot+springcloud相关面试题
SpringBoot整合SpringCloud
SpringBoot2.0.3整合SpringCloud
@SpringCloudApplication和@SpringBootApplication的区别
2.ResultFul
简介
webService
由于使用的SOAP协议,使用WSDL,这本质上是使用的XML进行内容通信,速度太慢,处理的效率太低
如果想使用本地接口的方式调用,要利用开发工具根据WSDL文件生成很多工具代码,接口任何变动都回导致工具代码重新生成,开发特别繁琐
RestFul
基于webService而来
项目搭建
SpringCloud系列二:Restful 基础架构(搭建项目环境、创建 Dept 微服务、客户端调用微服务)
服务提供方
服务消息方
3.SpringSecurity
服务提供方安全配置
SpringCloud系列三:SpringSecurity 安全访问(配置安全验证、服务消费端处理、无状态 Session 配置、定义公共安全配置程序类)
服务消费方处理
业务抽取
4.Eureka服务注册与发现
服务注册与发现流程
SpringCloud系列四:Eureka 服务发现框架(定义 Eureka 服务端、Eureka 服务信息、Eureka 发现管理、Eureka 安全配置、Eureka-HA(高可用) 机制、Eureka 服务打包部署)
eureka服务器的搭建
服务提供方的注册
相关配置
Eureka安全机制
HA 高可用
打包部署
5.Ribbon负载均衡
Ribbon基本使用
SpringCloud系列五:Ribbon 负载均衡(Ribbon 基本使用、Ribbon 负载均衡、自定义 Ribbon 配置、禁用 Eureka 实现 Ribbon 调用)
负载均衡的实现
自定义Ribbon路由
全局路由
单服务路由
提供方的信息获取
脱离Eureka使用Ribbon
6.Feign接口服务
Feign基本使用
SpringCloud系列六:Feign接口转换调用服务(Feign 基本使用、Feign 相关配置)
相关配置
数据压缩
日志配置
7.Hystrix 熔断机制
服务的雪崩
SpringCloud系列七:Hystrix 熔断机制(Hystrix基本配置、服务降级、HystrixDashboard服务监控、Turbine聚合监控)
服务提供方熔断
服务消费方降级
HystrixDashboard
turbine
8.zuul路由
zuul基本使用
SpringCloud系列八:Zuul 路由访问(Zuul 的基本使用、Zuul 路由功能、zuul 过滤访问、Zuul 服务降级)
路由配置
过滤访问
安全访问
Feign集成
zuul降级
9.Config 分布式配置中心
架构流程
SpringCloud系列九:SpringCloudConfig 基础配置(SpringCloudConfig 的基本概念、配置 SpringCloudConfig 服务端、抓取配置文件信息、客户端使用 SpringCloudConfig 进行配置、单仓库目录匹配、应用仓库自动选择、仓库匹配模式)
github账号
配置中心搭建
客户端读取配置
配置中心实战
config高可用
自动刷新
SpringCloudBus简介
基于SpringCloudBus实现自动刷新
10.SpringCloudStream 消息驱动
基本概念
RabbitMq集成
Stream的生产者
Stream的消费者
自定义通道
分组
RoutingKey设置
11.SpringCloudSleuth 链路跟踪
基本概念
SpringCloud系列十二:SpringCloudSleuth(SpringCloudSleuth 简介、SpringCloudSleuth 基本配置、数据采集)
跟踪服务
客户端配置
数据持久化
rabbitmq收集器
mysql存储器
12.springCloud中常用技术
邮件发送
Springboot实现发送邮箱
springCloud定时邮件发送
13.springCloud中注解探索
TestApplication上的注解
TestApplication.java
springCloud本身的注解
springCloud常用注解解释
springcloud中常用的注解@
springcloud中常用注解
@Autowired和@Resource的区别
springCloud的各种注解
配置文件注解
@Configuration
@Configuration注解探索
Spring @Configuration注解
@Configuration的使用
@Configuration和@Bean的用法和理解
注解下的其他技术
BeanDefinitionRegistryPostProcessor注册bean
DubboRegistryBeansDefinitionRegistryPostProcessor.java
BeanDefinitionRegistryPostProcessor
实现动态添加到spring容器
BeanDefinitionRegistryPostProcessor
EnvironmentAware
environmentaware接口实现环境变量读取和属性对象的绑定
BeanDefinitionRegistryPostProcessor探索
Spring基础-BeanDefinitionRegistryPostProcessor实现动态添加到spring容器
BeanFactoryPostProcessor
改变bean的定义(BeanFactoryPostProcessor接口)
@EnableConfigurationProperties
@EnableConfigurationProperties注解探索
@ConfigurationProperties和@EnableConfigurationProperties配合使用
在Spring Boot中使用 @ConfigurationProperties 注解 @EnableConfigurationProperties
@ConditionalOnProperty
@ConditionalOnProperty注解探索
ConditionalOnProperty
@ConfigurationProperties
@ConfigurationProperties注解实例文件
DubboProperties.java
@ConfigurationProperties注解探索
@ConfigurationProperties 注解
DubboAutoConfiguration.java
@ConditionalOnClass
@ConditionalOnClass注解探索
@ConditionalOnClass的使用探索
@ConditionalOnMissingClass
@ConditionalOnMissingClass注解探索
@Primary
@Primary注解探索
spring @Primary-在spring中的使用
@ConditionalOnMissingBean
@ConditionalOnMissingBean注解探索
@ConditionalOnMissingBean注解源码分析与示例
配置是否初始化Bean的方法
@ConditionalOnBean
@ConditionalOnBean注解探索
@ConditionalOnBean、@ConditionalOnMissingBean注解源码分析与示例
RestTemplateAutoConfiguration.java
@AutoConfigureAfter
@AutoConfigureAfter注解探索
@AutoConfigureAfter注解解析
@NestedConfigurationProperty
@WebServlet
过滤器注册
@Activate
ActiveLimitForServerFilter.java
Dubbo SPI 之 @Activate注解使用和实现解析
java规范的注解
@PostConstruct和@PreConstruct注解
Java开发之@PostConstruct和@PreConstruct注解
14.springCloud监听器探索
SpringBoot-事件监听的4种实现方式
15.springCloud过滤器探索
过滤器注解
@Filter中FilterType包含的类型及意义
过滤器实例
spring boot使用过滤器(以session校验为例)
16.springCloud拦截器探索
springAop对参数拦截
拦截器实例
spring boot使用拦截器(以session校验为例)
17.springCloud整合框架
springCloud切换环境
第一种:在多个文件中配置
第一种方法在多个文件中配置
第二种:在一个文件中配置
在一个文件中配置
第三种:在pom文件中配置
springCloud整合Eureka
单体Eureka的整合
Server服务端源码
服务端主启动类
ServerApp.java
yml文件配置
application.yml
Client服务提供者源码
服务端主启动类
Police.java
PoliceController.java
PoliceServer.java
yml文件配置
application.yml
Client服务调用者源码
服务端主启动类
PersonServer.java
TestController.java
yml文件配置
application.yml
集群Eureka的整合
springCloud整合Ribbon
springCloud整合Feign (服务调用)
springCloud整合Hystrix
springCloud整合Zuul
springCloud整合dubbo教程
融合springCloud与dubbo无缝替换
Spring Cloud与Dubbo共存方案总结
Springboot dubbo的整合以及与springcloud fein的对比
springCloud整合Feign
Spring Cloud Feign使用详解
Zipkin实现服务调用链跟踪
利用SpringCloud Sleuth和Zipkin实现调用链跟踪(一)
项目源码(不理解)
分布式解决的问题
分布式session一致性
分布式全局Id生产方案
分布式事务问题解决
分布式任务调度平台
分布式配置中心
分布式锁方案解决
分布式日志收集系统
网站跨域问题解决
分布式限流方案
手写微服务事务解决框架
dubbo系统调用接口
dubbo源码探索
dubbo的工作原理
Dubbo的底层原理
Dubbo源代码实现一:切入Spring
Dubbo源代码实现二:服务调用的动态代理和负载均衡
dubbo的源码
Dubbo源码解析
Dubbo实现源码分析
深入理解dubbo之服务发布源码分析
深入理解dubbo之服务引用
Dubbo RPC源码解读
dubbo源码解析-服务暴露原理
dubbo服务端处理请求源码分析
dubbo的环境搭建
dubbo与spring整合
maven+springmvc+dubbo+zookeeper
dubbo与springboot整合
Springboot 整合 Dubbo/ZooKeeper 详解
Dubbo的使用探索
Dubbo学习小记
dubbo与spring cloud
cloud/dubbo对比
spring cloud和dubbo的区别
Dubbo架构向SpringCloud架构兼容,过渡
融合spring cloud与dubbo 无缝替换spring cloud微服务间调用协议
Spring Cloud+Dubbo对Feign进行RPC改造
dubbo的面试探索
dubbo的工作原理
dubbo支持哪些序列化协议
hessian的数据结构
为什么PB的效率是最高的
dubbo负载均衡策略和高可用策略都有哪些?动态代理策略呢?
dubbo四种负载均衡策略
dubbo的spi思想是什么
如何基于dubbo进行服务治理、服务降级、失败重试以及超时重试
分布式服务接口的幂等性如何设计(比如不能重复扣款)
分布式服务接口请求的顺序性如何保证
如何自己设计一个类似dubbo的rpc框架
Serverlet容器
Tomcat
SpringBoot优化内嵌的Tomcat ---设置MaxConnections
Tomcat开启APR运行模式,优化并发性能
Springboot Tomcat APR模式详解和实践
springboot 内嵌tomcat APR 模式
springboot 2.X后内置tomcat自定义配置
Jetty
shiro
shiro权限流程原理
Shiro认证授权流程网络教程
认证流程解析
Shiro 认证流程分析
Shiro认证流程和授权流程
shiro登录认证过程讲解
思路清晰易懂(推荐)
授权流程解析
授权源码解析
shiro权限控制实例
springboot、shiro、redis整合
springboot整合shiro系列教程
配置记住我
session管理
统计在线人数
取消url上面的JSESSIONID
同一用户并发登录限制
登录失败次数限制
实现验证码认证
实现自己的登出
登出时,redis中缓存没有清理干净的问题
SpringBoot整合mybatis、shiro、redis细粒度动态权限管理系统实例
github地址
代码
@Configuration ShiroConfig
LifecycleBeanPostProcessor getLifecycleBeanPostProcessor()
管理shiro一些bean的生命周期
ShiroDialect shiroDialect()
配置ShiroDialect,用于thymeleaf和shiro标签配合使用
ShiroFilterFactoryBean shiroFilter(SecurityManager securityManager)
shiroFilterFactoryBean.setSecurityManager(securityManager);
SecurityManager securityManager()
securityManager.setRealm(myShiroRealm())
MyShiroRealm myShiroRealm()
MyShiroRealm myShiroRealm = new MyShiroRealm();
MyShiroRealm extends AuthorizingRealm
AuthenticationInfo doGetAuthenticationInfo(AuthenticationToken token)
AuthorizationInfo doGetAuthorizationInfo(PrincipalCollection principalCollection)
void clearUserAuthByUserId(List<Integer> userIds)
myShiroRealm.setCredentialsMatcher(hashedCredentialsMatcher());
HashedCredentialsMatcher hashedCredentialsMatcher()
hashedCredentialsMatcher.setHashAlgorithmName("md5");//散列算法:这里使用MD5算法;
hashedCredentialsMatcher.setHashIterations(2);//散列的次数,比如散列两次,相当于 md5(md5(""));
securityManager.setCacheManager(cacheManager());
RedisCacheManager cacheManager()
redisCacheManager.setRedisManager(redisManager());
RedisManager redisManager()
securityManager.setSessionManager(sessionManager());
DefaultWebSessionManager sessionManager()
sessionManager.setSessionDAO(redisSessionDAO());
RedisSessionDAO redisSessionDAO()
redisSessionDAO.setRedisManager(redisManager());
shiroFilterFactoryBean.setLoginUrl("/login");
shiroFilterFactoryBean.setSuccessUrl("/usersPage");
shiroFilterFactoryBean.setUnauthorizedUrl("/403");
shiroFilterFactoryBean.setFilterChainDefinitionMap(filterChainDefinitionMap);
AuthorizationAttributeSourceAdvisor authorizationAttributeSourceAdvisor(SecurityManager securityManager)
开启shiro aop注解支持
认证授权流程
权限管理(项目和源码)系列教程
springboot+shiro+jwt+redis无状态token登录
SpringBoot整合shiro+jwt+redis - 无状态token登录
github地址
代码
SpringBoot集成JWT实现token验证
shiro权限验证管理
shiro的权限控制
1.使用shiro的session管理
2.使用缓存读取session
session管理,单点登录
菜单按钮权限管理
shiro整合防止攻击
xss攻击讲解
xss攻击原理及防范
网络攻击-XSS攻击详解
XSS及CSRF攻击防御
CSRF的攻击和防范
DDOS 攻击的防范教程
常见web攻击方法及防御手段总结
XSS过滤JAVA过滤器filter 防止常见SQL注入
shiro的内外部架构
Shiro外部来看
shiro外部架构
shiro外部架构.jpg
Subject:应用代码直接交互的对象是 Subject
SecurityManager:安全管理器;即所有与安全有关的操作都会与SecurityManager 交互
Realm:Shiro 从 Realm 获取安全数据(如用户、角色、权限)
shiro内部架构
shiro内部架构
shiro内部架构.jpg
Subject:任何可以与应用交互的“用户”;
SecurityManager :相当于SpringMVC 中的 DispatcherServlet;是 Shiro 的心脏;
Authenticator:负责 Subject 认证,是一个扩展点,可以自定义实现;
Authorizer:授权器、 即访问控制器,用来决定主体是否有权限进行相应的操作;
Realm:可以有 1 个或多个 Realm,可以认为是安全实体数据源,即用于获取安全实体的;
SessionManager:管理 Session 生命周期的组件;
SessionDAO
用于代替SessionManager执行Session相关的增删改查。
CacheManager:缓存控制器,来管理如用户、角色、权限等的缓存的;
Cryptography:密码模块,Shiro 提高了一些常见的加密组件用于如密码加密/解密。
shiro框架功能简介
Authentication:身份认证/登录,验证用户是不是拥有相应的身份
Authorization:授权,即权限验证,验证某个已认证的用户是否拥有某个权限;
Session Manager:会话管理,即用户登录后就是一次会话,在没有退出之前,它的所有信息都在会话中;
Cryptography:加密,保护数据的安全性,如密码加密存储到数据库,而不是明文存储;
Web Support:Web 支持,可以非常容易的集成到Web 环境;
Caching:缓存,比如用户登录后,其用户信息、拥有的角色/权限不必每次去查,这样可以提高效率;
Concurrency:Shiro 支持多线程应用的并发验证,即如在一个线程中开启另一个线程,能把权限自动传播过去;
Testing:提供测试支持;
Run As:允许一个用户假装为另一个用户(如果他们允许)的身份进行访问;
Remember Me:记住我,这个是非常常见的功能,即一次登录后,下次再来的话不用登录了
Protobuf
https://blog.viakiba.cn/2020/07/14/protobuf-%E6%8E%A2%E7%9F%A5(%E4%B8%8A)/
https://blog.viakiba.cn/2020/07/14/protobuf-%E6%8E%A2%E7%9F%A5(%E4%B8%8B)/
算法与数据结构
复杂度概念
时间复杂度:运行时间长短。
计算方式
大O表示法(渐进时间复杂度):把程序的相对执行时间函数T(n)简化为一个数量级,这个数量级可以是n、n^2、logN等。
推导时间复杂度的几个原则:
如果运行时间是常数量级,则用常数1表示。
只保留时间函数中的最高阶项。
如果最高阶项存在,则省去最高项前面的系数。
时间复杂度对比:O(1) > O(logn) > O(n) > O(nlogn) > O(n^2)。
推导时间复杂度的几个原则:
如果运行时间是常数量级,则用常数1表示。
只保留时间函数中的最高阶项。
如果最高阶项存在,则省去最高项前面的系数。
时间复杂度对比:O(1) > O(logn) > O(n) > O(nlogn) > O(n^2)。
空间复杂度:占用内存大小。
计算方式
常量空间 O(1):存储空间大小固定,和输入规模没有直接的关系。
线性空间 O(n):分配的空间是一个线性的集合,并且集合大小和输入规模n成正比。
二维空间 O(n^2):分配的空间是一个二维数组集合,并且集合的长度和宽度都与输入规模n成正比。
递归空间 O(logn):递归是一个比较特殊的场景。虽然递归代码中并没有显式的声明变量或集合,但是计算机在执行程序时,会专门分配一块内存空间,用来存储“方法调用栈”。执行递归操作所需要的内存空间和递归的深度成正比。
线性空间 O(n):分配的空间是一个线性的集合,并且集合大小和输入规模n成正比。
二维空间 O(n^2):分配的空间是一个二维数组集合,并且集合的长度和宽度都与输入规模n成正比。
递归空间 O(logn):递归是一个比较特殊的场景。虽然递归代码中并没有显式的声明变量或集合,但是计算机在执行程序时,会专门分配一块内存空间,用来存储“方法调用栈”。执行递归操作所需要的内存空间和递归的深度成正比。
常见算法
字符串:暴力匹配、BM、KMP、Trie等。
kmp算法
查找:二分查找、遍历查找等。
排序:冒泡排序、快排、计数排序、堆排序等。
搜索:TFIDF、PageRank等。
聚类分析:期望最大化、k-meanings、k-数位等。
深度学习:深度信念网络、深度卷积神经网络、生成式对抗等。
异常检测:k最近邻、局部异常因子等。
hash算法及常用的hash算法
。。。。。。。
数据结构
数组
读取O(1)、更新O(1)、插入O(n)、删除O(n)、扩容O(n)。
链表
读取O(n)、更新O(1)、插入O(1)、删除O(1)。
栈
入栈O(1)、出栈O(1)。
队列
入队 O(1)、出队 O(1)。
哈希表
写入:O(1)、读取:O(1)、扩容O(n)。
哈希冲突
不同的key通过哈希函数获得的下标有可能是相同的。
解决方式
开放寻址法:例子Threadlocal。
链表法:例子Hashmap。
开放寻址法:例子Threadlocal。
链表法:例子Hashmap。
树
定义
树(tree)是n(n≥0)个节点的有限集。
当n=0时,称为空树。在任意一个非空树中,有如下特点:
有且仅有一个特定的称为根的节点。
当n>1时,其余节点可分为m(m>0)个互不相交的有限集,每一个集合本身又是一个树,并称为根的子树。
当n=0时,称为空树。在任意一个非空树中,有如下特点:
有且仅有一个特定的称为根的节点。
当n>1时,其余节点可分为m(m>0)个互不相交的有限集,每一个集合本身又是一个树,并称为根的子树。
树的遍历
深度优先
前序:根节点、左子树、右子树。
中序:左子树、根节点、右子树。
后序:左子树、右子树、根节点。
广度优先
层序:一层一层遍历。
二叉树
二叉树(binary tree)是树的一种特殊形式。二叉,顾名思义,这种树的每个节点最多有2个孩子节点。注意,这里是最多有2个,也可能只有1个,或者没有孩子节点。
一个二叉树的所有非叶子节点都存在左右孩子,并且所有叶子节点都在同一层级上,那么这个树就是满二叉树。
对一个有n个节点的二叉树,按层级顺序编号,则所有节点的编号为从1到n。如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同,则这个二叉树为完全二叉树。
二叉查找树
二叉查找树在二叉树的基础上增加了以下几个条件:
如果左子树不为空,则左子树上所有节点的值均小于根节点的值。
如果右子树不为空,则右子树上所有节点的值均大于根节点的值。
左、右子树也都是二叉查找树。
如果左子树不为空,则左子树上所有节点的值均小于根节点的值。
如果右子树不为空,则右子树上所有节点的值均大于根节点的值。
左、右子树也都是二叉查找树。
作用
查找==》二分查找。
排序==》中序遍历。
查找==》二分查找。
排序==》中序遍历。
实现方式
链表。
数组:对于稀疏二叉树来说,数组表示法是非常浪费空间的。
链表。
数组:对于稀疏二叉树来说,数组表示法是非常浪费空间的。
二叉堆
B树、B-树、B+树、B*树
排序算法
https://www.cnblogs.com/onepixel/p/7674659.html
设计模式
六大原则
单一职责原则
定义:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责。
问题由来:类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
解决方案:遵循单一职责原则。分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
问题由来:类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
解决方案:遵循单一职责原则。分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多;
提高类的可读性,提高系统的可维护性;
变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响
提高类的可读性,提高系统的可维护性;
变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响
里氏替换原则
所有引用基类的地方必须能透明地使用其子类的对象。
问题由来:有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
解决方案:当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
解决方案:当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
依赖倒置原则
高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
问题由来:类A直接依赖类B,假如要将类A改为依赖类C,则必须通过修改类A的代码来达成。这种场景下,类A一般是高层模块,负责复杂的业务逻辑;类B和类C是低层模块,负责基本的原子操作;假如修改类A,会给程序带来不必要的风险。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
解决方案:将类A修改为依赖接口I,类B和类C各自实现接口I,类A通过接口I间接与类B或者类C发生联系,则会大大降低修改类A的几率。
依赖倒置原则基于这样一个事实:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建起来的架构比以细节为基础搭建起来的架构要稳定的多。在java中,抽象指的是接口或者抽象类,细节就是具体的实现类,使用接口或者抽象类的目的是制定好规范和契约,而不去涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成。
接口隔离原则
客户端不应该依赖它不需要的接口;一个类对另一个类的依赖应该建立在最小的接口上。
问题由来:类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法。
问题由来:类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说不是最小接口,则类B和类D必须去实现他们不需要的方法。
迪米特法则
一个对象应该对其他对象保持最少的了解。
问题由来:类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
解决方案:尽量降低类与类之间的耦合。
解决方案:尽量降低类与类之间的耦合。
开闭原则
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
常见模式
单例模式
简单理解
频繁创建对象、管理对象是一件耗费资源的事,如果我们可以使用一个对象就可以完成功能了,那就使用单例模式吧!
静态.doSomething和单例的区别
使用静态类.doSomething()体现的是基于对象
使用单例设计模式体现的是面向对象。
编写单例模式步骤
构造函数私有化
在类的内部创建实例
提供方法获取该实例
单例模式五种写法
饿汉式
直接在成员变量上new出实例,提供方法返回
普通懒汉式
等到调用方法的时候再创建对象,该方法需要加Synchronized锁
双重检测机制(DCL)懒汉式
基于普通懒汉式的提升,普通懒汉式的效率太低了
1.使用volatile修饰我们的对象引用
2.外部if判断对象是否为null,为null往下执行,不为null直接返回对象
3.使用syn同步进入代码块,使用if判断对象是否为null,为null就创建对象
4.使用volatile修饰成员变量的原因就是防止重排序的问题--->变量还未完全初始化就被线程B返回了
静态内部类懒汉式
创建一个内部类,在内部类直接创建对象
外部类提供方法来获取内部类创建的对象
这种方式是非常方便和友好的,在外部调用的时候,内部类才会创建对象
枚举
public enum Java3y3y {
JAVA_3_Y_3_Y,
}
省事,安全(枚举能够有效防止多次实例化的问题)
工厂模式
简单理解
工厂模式就是让创建对象变得简单而且修改对象时能很方便
另一个方便就是体现在解耦
工厂模式延伸了三类
简单工厂模式
工厂方法模式
抽象工厂模式
工厂方法模式编写
1. 一个抽象工厂类
2. 多个实现工厂类
3. 外部通过工厂拿到对象
优缺点
优点
1:客户端不需要在负责对象的创建,明确了各个类的职责
2:如果有新的对象增加,只需要增加一个具体的类和具体的工厂类即可
3:不会影响已有的代码,后期维护容易,增强系统的扩展性
缺点
需要额外的编写代码,增加了工作量
简单工厂模式编写
1. 就一个实现工厂类,所有的对象交由该工厂类创建
2. 外部通过这个工厂类获取对象
优缺点
优点
就一个具体的工厂来创建对象,代码量少。
缺点
增加了对象就需要修改代码,麻烦
抽象工厂模式
在工厂方法模式下又多了一层抽象,减少了工厂的数量
衍生出了产品族和产品等级(无非就是将公有的功能抽象出来了)
优缺点
优点
减少了工厂的数据
缺点
难以扩展产品族,会修改非常多的类
策略模式
简单理解
将每个算法都封装起来,并且使他们之间可以互换
上下文角色(Context)只是为了简化客户端调用,解耦
策略模式要素
一个通用算法接口
多个实现类
一个上下文角色(Context)
代理模式
简单理解
当前对象不愿意干的,没法干的东西委托给别的对象来做,我只要做好本分的东西就好了
透明代理
在代理中内部直接new出被代理对象。此时使用代理对象对外界来说是透明的
动态代理
使用JDK的API实现动态代理
代理对象拥有目标对象相同的方法【因为参数二指定了对象的接口,代理对象会实现接口的所有方法】
用户调用代理对象的什么方法,都是在调用处理器的invoke方法。【被拦截】
使用JDK动态代理必须要有接口【参数二需要接口】
所有通过动态代理实现的方法全部通过invoke()调用
使用CGLib实现动态代理
如果没有接口的情况下,这种形式可以通过类来实现动态代理,生成的是子类代理
动态代理和静态代理的区别
静态代理需要自己写代理类-->代理类需要实现与目标对象相同的接口
需要自己实现接口下的所有方法
代理对象的生成,是利用JDKAPI,动态地在内存中构建代理对象(需要我们指定创建 代理对象/目标对象 实现的接口的类型),并且会默认实现接口的全部方法。
应用
增强request对象实现中文过滤器
门面模式
简单理解
门面模式提供一个高层次的接口,使得子系统更易于使用
子系统就相当于电脑、冰箱、电视。统一的对象就相当于我们的电闸
门面模式要素
一个高层次的接口
多个实现类
包装模式
简单理解
增强对象有三种方式
继承
包装模式
代理模式
前提:继承的方式不容易扩展(写死),如果类中带有信息也是不能用继承的方式的
于是我们就有包装设计模式给我们很方便的扩展
包装模式使用
前提:拥有一个接口,一个默认实现类
动工:编写一个装饰器(抽象类)->实现接口->以组合的方式来接收默认实现类
使用:要扩展的时候,就继承上面编写的装饰器,定义自己想要扩展的功能
说白了就多了一层抽象,基于这层抽象来方便扩展
应用
IO流用得就很多了:BufferedReader bf = new BufferedReader(new FileReader(new File("aa.txt")));
模板方法模式
简单理解
定义一个操作中的算法框架,而将一些步骤延迟到子类中。
使子类可以不改变一个算法的结构即可重定义该算法的某些步骤
模板方法术语
抽象方法
定义了一个框架,实现对基本方法的调用,完成固定的逻辑。
基本方法
在子类实现,并且在模板方法中被调用
模板方法要素
一个抽象方法,供对外使用
多个基本方法(由子类实现)
数据库
关系数据库
MySql
基本语法
连接数据库
mysql -u用户名 -p密码
对库的操作
创建库
CREATE DATABASE [IF NOT EXISTS] 库名[DEFAULT] CHARACTER SET 字符名 | [DEFAULT] COLLATE 校对规则
查看库
SHOW DATABASES
SHOW CREATE DATABASE 库名【查看数据库创建时的详细信息】
删除库
DROP DATABASE [IF EXISTS] 库名
修改库
ALTER DATABASE [IF NOT EXISTS] 库名[DEFAULT] CHARACTER SET 字符名 | [DEFAULT] COLLATE 校对规则
备份库中的数据和
mysqldump -u 用户名 -p 数据库名 > 文件名.sql【window命令】
Source 文件名.sql【在库下执行】
mysql -uroot -p mydb1> c:\test.sql (window命令)
对表的操作
增加表
CREATE TABLE 表名( 列名 类型 )
修改表
ALTER TABLE 表名 ADD ( 列名 数据类型 );
ALTER TABLE 表名 MODIFY( 列名 数据类型 );
查看表
SHOW TABLES
SHOW CREATE TABLE 表名【查看表的创建细节】
DESC 表名【查看表的结构】
删除表
ALTER TABLE表名DROP(列名);
对表中数据操作
增加
INSERT INTO 表名 ( 列名..)VALUES (数据..);
修改
UPDATE 表名SET 列名=值.. , 列名=值WHERE=条件
删除
DELETE FROM 表名 WHERE=条件
TRUNCATE TABLE【先摧毁整张表,再创建表结构】
查看
SELECT 列名FROM 表名,WHERE 条件,GROUP BY 列名,HAVING BY,ORDER BY 列名
SELECT子句执行顺序
1.FROM
2.WHERE
3.GROUP BY
4. HAVING
5.SELECT
6.ORDER BY
聚集函数
AVG()
MAX()
MIN()
COUNT()
SUM()
通配符检索数据
用LIKE操作符进行过滤
%通配符,匹配0个或多个
_通配符,匹配单个字符
排序检索数据
使用ORDER BY 排序数据
按位置、列名排序
按多个列排序
DESC降序
ASC升序【默认】
分组数据
使用GROUP BY分组
使用HAVING过滤分组
WHERE过滤的是行数据
联结表
FROM字句后边不止一个表,就叫联结
内连接(等值连接)【INNER JOIN】,使用ON子句 消除笛卡尔积
外连接【包含没有相关的行】,LEFT(RIGHT,FULL) OUTER JOIN,
FROM子句跟着是两个相同的表叫自连接
索引
创建
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
更改
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON(columnname(length));
删除
DROP INDEX [indexName] ON mytable;
DROP INDEX [indexName] ON mytable;
查看一个表的索引信息
show index from [tableName];
show index from [tableName];
触发器
/* 触发器 */ ------------------
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
-- 创建触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
参数:
trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
trigger_event指明了激活触发程序的语句的类型
INSERT:将新行插入表时激活触发程序
UPDATE:更改某一行时激活触发程序
DELETE:从表中删除某一行时激活触发程序
tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
-- 删除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替旧的和新的数据
更新操作,更新前是old,更新后是new.
删除操作,只有old.
增加操作,只有new.
-- 注意
1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
-- 字符连接函数
concat(str1,str2,...])
concat_ws(separator,str1,str2,...)
-- 分支语句
if 条件 then
执行语句
elseif 条件 then
执行语句
else
执行语句
end if;
-- 修改最外层语句结束符
delimiter 自定义结束符号
SQL语句
自定义结束符号
delimiter ; -- 修改回原来的分号
-- 语句块包裹
begin
语句块
end
-- 特殊的执行
1. 只要添加记录,就会触发程序。
2. Insert into on duplicate key update 语法会触发:
如果没有重复记录,会触发 before insert, after insert;
如果有重复记录并更新,会触发 before insert, before update, after update;
如果有重复记录但是没有发生更新,则触发 before insert, before update
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
监听:记录的增加、修改、删除。
-- 创建触发器
CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
参数:
trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
trigger_event指明了激活触发程序的语句的类型
INSERT:将新行插入表时激活触发程序
UPDATE:更改某一行时激活触发程序
DELETE:从表中删除某一行时激活触发程序
tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
-- 删除
DROP TRIGGER [schema_name.]trigger_name
可以使用old和new代替旧的和新的数据
更新操作,更新前是old,更新后是new.
删除操作,只有old.
增加操作,只有new.
-- 注意
1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
-- 字符连接函数
concat(str1,str2,...])
concat_ws(separator,str1,str2,...)
-- 分支语句
if 条件 then
执行语句
elseif 条件 then
执行语句
else
执行语句
end if;
-- 修改最外层语句结束符
delimiter 自定义结束符号
SQL语句
自定义结束符号
delimiter ; -- 修改回原来的分号
-- 语句块包裹
begin
语句块
end
-- 特殊的执行
1. 只要添加记录,就会触发程序。
2. Insert into on duplicate key update 语法会触发:
如果没有重复记录,会触发 before insert, after insert;
如果有重复记录并更新,会触发 before insert, before update, after update;
如果有重复记录但是没有发生更新,则触发 before insert, before update
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
存储过程
/* 存储过程 */ ------------------
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
-- 注意
- 没有返回值。
- 只能单独调用,不可夹杂在其他语句中
-- 参数
IN|OUT|INOUT 参数名 数据类型
IN 输入:在调用过程中,将数据输入到过程体内部的参数
OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
INOUT 输入输出:既可输入,也可输出
-- 语法
CREATE PROCEDURE 过程名 (参数列表)
BEGIN
过程体
END
存储过程是一段可执行性代码的集合。相比函数,更偏向于业务逻辑。
调用:CALL 过程名
-- 注意
- 没有返回值。
- 只能单独调用,不可夹杂在其他语句中
-- 参数
IN|OUT|INOUT 参数名 数据类型
IN 输入:在调用过程中,将数据输入到过程体内部的参数
OUT 输出:在调用过程中,将过程体处理完的结果返回到客户端
INOUT 输入输出:既可输入,也可输出
-- 语法
CREATE PROCEDURE 过程名 (参数列表)
BEGIN
过程体
END
用户和权限管理
/* 用户和权限管理 */ ------------------
-- root密码重置
1. 停止MySQL服务
2. [Linux] /usr/local/mysql/bin/safe_mysqld --skip-grant-tables &
[Windows] mysqld --skip-grant-tables
3. use mysql;
4. UPDATE `user` SET PASSWORD=PASSWORD("密码") WHERE `user` = "root";
5. FLUSH PRIVILEGES;
用户信息表:mysql.user
-- 刷新权限
FLUSH PRIVILEGES;
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
- 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
- 只能创建用户,不能赋予权限。
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 密码也需引号,纯数字密码也要加引号
- 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置密码
SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
GRANT ALL PRIVILEGES ON `pms`.* TO 'pms'@'%' IDENTIFIED BY 'pms0817';
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列。
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
-- root密码重置
1. 停止MySQL服务
2. [Linux] /usr/local/mysql/bin/safe_mysqld --skip-grant-tables &
[Windows] mysqld --skip-grant-tables
3. use mysql;
4. UPDATE `user` SET PASSWORD=PASSWORD("密码") WHERE `user` = "root";
5. FLUSH PRIVILEGES;
用户信息表:mysql.user
-- 刷新权限
FLUSH PRIVILEGES;
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 密码(字符串)
- 必须拥有mysql数据库的全局CREATE USER权限,或拥有INSERT权限。
- 只能创建用户,不能赋予权限。
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 密码也需引号,纯数字密码也要加引号
- 要在纯文本中指定密码,需忽略PASSWORD关键词。要把密码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置密码
SET PASSWORD = PASSWORD('密码') -- 为当前用户设置密码
SET PASSWORD FOR 用户名 = PASSWORD('密码') -- 为指定用户设置密码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
GRANT ALL PRIVILEGES ON `pms`.* TO 'pms'@'%' IDENTIFIED BY 'pms0817';
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限。
全局层级:全局权限适用于一个给定服务器中的所有数据库,mysql.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限。
数据库层级:数据库权限适用于一个给定数据库中的所有目标,mysql.db, mysql.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限。
表层级:表权限适用于一个给定表中的所有列,mysql.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限。
列层级:列权限适用于一个给定表中的单一列,mysql.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列。
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
三个范式
-- Normal Format, NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除复合主键就可以避免部分依赖。增加单列关键字。
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF, 第一范式
字段不能再分,就满足第一范式。
-- 2NF, 第二范式
满足第一范式的前提下,不能出现部分依赖。
消除复合主键就可以避免部分依赖。增加单列关键字。
-- 3NF, 第三范式
满足第二范式的前提下,不能出现传递依赖。
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
将一个实体信息的数据放在一个表内实现。
备份与还原
/* 备份与还原 */ ------------------
备份,将数据的结构与表内数据保存起来。
利用 mysqldump 指令完成。
-- 导出
mysqldump [options] db_name [tables]
mysqldump [options] ---database DB1 [DB2 DB3...]
mysqldump [options] --all--database
1. 导出一张表
mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
2. 导出多张表
mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
3. 导出所有表
mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
4. 导出一个库
mysqldump -u用户名 -p密码 --lock-all-tables --database 库名 > 文件名(D:/a.sql)
可以-w携带WHERE条件
-- 导入
1. 在登录mysql的情况下:
source 备份文件
2. 在不登录的情况下
mysql -u用户名 -p密码 库名 < 备份文件
事务
在mysql中myisam不支持事务
事务四大特性(ACID)
原子性
事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
一致性
执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
隔离性
并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
持久性
一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
事务带来的问题
脏读
一个事务读取了另一个事务未提交的数据
当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
不可重复读
一个事务两次读取同一个数据,两次读取的数据不一致
指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读
一个事务两次读取一个范围的 记录,两次读取的记录数不一致。
幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
更新丢失
一个事务的更新覆盖了另一个事务的更新,解决办法使用乐观锁或者使用排它锁
指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
事务隔离级别
读未提交:read uncommitted
读已提交:read committed
Oracle默认隔离级别
可重复读:repeatable read
MySQL默认级别
串行化:serializable
常见问题
对号表示没解决
MySQL InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读)。我们可以通过SELECT @@tx_isolation;
InnoDB 存储引擎的默认支持的隔离级别是 REPEATABLE-READ(可重读),但是可以通过应用加锁读(例如 select * from table for update 语句)来保证不会产生幻读,而这个加锁度使用到的机制就是 Next-Key Lock 锁算法。从而达到了 SQL 标准的 SERIALIZABLE(可串行化) 隔离级别。
设置隔离级别
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
START TARNSACTION |BEGIN:显式地开启一个事务。
COMMIT:提交事务,使得对数据库做的所有修改成为永久性。
ROLLBACK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
COMMIT:提交事务,使得对数据库做的所有修改成为永久性。
ROLLBACK:回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
不可重复读的重点是修改,幻读的重点在于新增或者删除。
索引
查询算法
顺序查找 O(n)
二分查找 有序 O(logn)
二叉排序树查找
特点
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树。
若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
它的左、右子树也分别为二叉排序树。
原理
若b是空树,则搜索失败,否则;
若x等于b的根节点的数据域之值,则查找成功;否则:
若x小于b的根节点的数据域之值,则搜索左子树;否则:
查找右子树
若x等于b的根节点的数据域之值,则查找成功;否则:
若x小于b的根节点的数据域之值,则搜索左子树;否则:
查找右子树
O(log2N)
多叉平衡查找树
B树
结构特征
d为大于1的一个正整数,称为B-Tree的度。
h为一个正整数,称为B-Tree的高度。
每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d。
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null 。
所有叶节点具有相同的深度,等于树高h。
key和指针互相间隔,节点两端是指针。
一个节点中的key从左到右非递减排列。
所有节点组成树结构。
每个指针要么为null,要么指向另外一个节点。
如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于v(key1),其中v(key1)为node的第一个key的值。
如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于v(keym),其中v(keym)为node的最后一个key的值。
如果某个指针在节点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向节点的所有key小于v(keyi+1)且大于v(keyi)。
h为一个正整数,称为B-Tree的高度。
每个非叶子节点由n-1个key和n个指针组成,其中d<=n<=2d。
每个叶子节点最少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶节点的指针均为null 。
所有叶节点具有相同的深度,等于树高h。
key和指针互相间隔,节点两端是指针。
一个节点中的key从左到右非递减排列。
所有节点组成树结构。
每个指针要么为null,要么指向另外一个节点。
如果某个指针在节点node最左边且不为null,则其指向节点的所有key小于v(key1),其中v(key1)为node的第一个key的值。
如果某个指针在节点node最右边且不为null,则其指向节点的所有key大于v(keym),其中v(keym)为node的最后一个key的值。
如果某个指针在节点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向节点的所有key小于v(keyi+1)且大于v(keyi)。
例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找节点个数的渐进复杂度为O(logdN)。
由于插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质,这也是索引会降低增删改数据性能的原因。
B+树
结构特征
每个节点的指针上限为2d而不是2d+1。
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。 (而 B 树的叶子节点并没有包括全部需要查找的信息)
内节点不存储data,只存储key;叶子节点不存储指针。所有的内节点点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的内节点也包含需要查找的有效信息)
数据库索引实际上用的是带有顺序的B+Tree。在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
红黑树
B+Tree/B-Tree的性能会比采用红黑树好
先从B-Tree分析,根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B-Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
- 为什么MYSQL使用B+树作为索引数据结构?
http://blog.csdn.net/kennyrose/article/details/7532032
http://www.xuebuyuan.com/2216918.html
索引的分类
唯一索引
索引列的值必须唯一,但允许有空值
普通索引
即一个索引只包含单个列,一个表可以有多个单列索引(建议一张表索引不要超过5个
优先考虑复合索引)
优先考虑复合索引)
复合索引(联合索引)
即一个索引包含多个列
最左前缀原则
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。
查询的时候如果两个条件都用上了,但是顺序不同,如 city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
主键索引
加速查询+列值唯一+表中只有一个(不可以有 null)
聚簇索引
将数据存储与索引放到了一块,找到索引也就找到了数据
聚簇索引具有唯一性
主键
为什么推荐尽量使用复合索引而不是使用唯一索引呢?
因为MYSQL每次查询只能使用一个索引,如果我们sql语句查询条件包含两个字段,那么使用单值索引需要查询两次,但是复合索引只需要一次即可,有时候覆盖索引完全覆盖可以不回表查询
回表 即普通索引查询方式,则需要先搜索name索引树,得到id的值为3,再到id聚簇索引树搜索一次。这个过程称为回表
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
全文索引
索引的数据结构
B+Tree 索引
MyISAM: B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
hash 索引
二者区别
Hash索引定位快
Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
Hash冲突问题
知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。
B+树是有序的,在这种范围查询中,优势非常大
B+树是有序的,在这种范围查询中,优势非常大
B树和B+树区别
B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
索引的优缺点
优点
提高数据检索效率,降低数据库IO成本,将随机IO变为顺序IO
通过索引列对数据排序,降低数据排序成本,降低CPU的消耗
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
缺点
实际上索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录,所以索引列也是要占用空间的
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如果对表INSERT,UPDATE和DELETE。
因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,
都会调整因为更新所带来的键值变化后的索引信息
因为更新表时,MySQL不仅要不存数据,还要保存一下索引文件每次更新添加了索引列的字段,
都会调整因为更新所带来的键值变化后的索引信息
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立优秀的索引,或优化查询语句
http://www.cnblogs.com/mxmbk/articles/5226344.html
http://www.cnblogs.com/simplefrog/archive/2012/07/15/2592527.html
http://www.open-open.com/lib/view/open1418476492792.html
http://blog.csdn.net/colin_liu2009/article/details/7301089
http://www.cnblogs.com/hongfei/archive/2012/10/20/2732589.html
http://www.cnblogs.com/simplefrog/archive/2012/07/15/2592527.html
http://www.open-open.com/lib/view/open1418476492792.html
http://blog.csdn.net/colin_liu2009/article/details/7301089
http://www.cnblogs.com/hongfei/archive/2012/10/20/2732589.html
什么是回表?
索引优化
Explain(查询语句执行计划)
作用
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询
字段
ID
查询序号,id相同从上往下,id不同id越大优先级越高
select_type
表示示查询中每个select子句的类型
table(重要)
显示这一步所访问数据库中表名称(显示这一行的数据是关于哪张表的),有时不是真实的表名字,可能是简称,例如上面的e,d,也可能是第几步执行的结果的简称
partitions
代表分区表中的命中情况,非分区表,该项为null
type(重要)
对表访问方式,表示MySQL在表中找到所需行的方式,又称“访问类型”。
ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys
指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用(该查询可以利用的索引,如果没有任何索引显示 null)
Key(重要)
key列显示MySQL实际决定使用的键(索引),必然包含在possible_keys中
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度(key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的)
ref
列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows(重要)
表示MySQL估计未来找到所需要的行而要读取的行数
Extra(重要)
这一列包含的是不适合在其他列显示的额为信息
什么是复合索引的最左匹配原则?
索引失效的情况
如果查询条件用or,必须or条件中的每个列都加上索引,否则无效。(尽量使用union代替)
复合索引未用左列字段;
like以%开头;
需要类型转换;
where中索引列有运算;
where中索引列使用了函数;
如果mysql觉得全表扫描更快时(数据少)
查询优化
关联查询
保证被驱动表的join字段有索引
left join时,选择小表为驱动表,大表为被驱动表,因为驱动表一定要做全表扫描。
inner join时,mysql会自己帮你把小结果集的表选为驱动表
子查询尽量不要放在被驱动表。因为子查询会生成虚拟表导致有可能使用不到索引
能够直接关联查询,尽量不用子查询。
慢查询
数据量不同,查询条件不同,sql使用的索引可能是不一样的,要构造多种查询条件去测试。
避免所有字段都返回,尽量使用覆盖索引,解决慢sql问题,终归是与库的磁盘IO、CPU做抗争。
避免隐式转换造成的索引无法使用问题。
制好事务粒度,大事务不仅会严重影响数据库的吞吐量,CPU(死锁检测),也会造成主从的延迟,危害极大。
合理的设置数据库连接池的参数,设置sql语句的timeout,查询量大的地方,需要有降级开关。
新增功能,每一条sql语句,都要进行explain
所谓的慢sql,有些sql并不慢,而是坏sql,调用量低,数据量少的情况,并不慢,慢日志无法捕获。这个时候,需要对功能进行压测,压测需要注意两个问题:
a) 压测脚本的选择,如果使用固定的查询条件,会造成mysql命中缓存,或使用固定索引,压测效果不明显
b) 压测数据库的操作,要逐渐放量,避免将库CPU打满,既要盯UMP的性能曲线,又要关注数据库CPU的使用率。
a) 压测脚本的选择,如果使用固定的查询条件,会造成mysql命中缓存,或使用固定索引,压测效果不明显
b) 压测数据库的操作,要逐渐放量,避免将库CPU打满,既要盯UMP的性能曲线,又要关注数据库CPU的使用率。
读写分离
使用读写分离的方式,降低数据库的压力,读写分离能有效降低库的压力
主从延迟问题。读写分离后,无可避免的会有延迟问题,所以需要甄别好,哪些业务是对延迟敏感的,这类业务,需要继续查询主库。为尽量避免延迟问题,需注意以下几点:
a) 从库的压力,不能过大,如果资源允许,尽量主从的硬件资源相同。
b) 避免使用大事务。
c) 尽量避免大批量的删除、更新操作,尤其是无法使用索引的情况。
a) 从库的压力,不能过大,如果资源允许,尽量主从的硬件资源相同。
b) 避免使用大事务。
c) 尽量避免大批量的删除、更新操作,尤其是无法使用索引的情况。
业务隔离,不同业务使用不同从库。识别出业务的黄金流程。重点业务与其他非重点业务使用不同的从库进行隔离。
架构调整,服务化改造,应用拆分
脱库改造,增加缓存。
a) 对于数据要求实时性不高的场景,并且为了快速的减少系统问题,可采取缓存read-through的方式,该方式系统改造量低,简单。但是要注意,避免不存在的key缓存穿透(不存在key设置特殊值、bloomfilter)。缓存雪崩问题。
b) 数据异构,将依赖的底层数据通过binlake或双写等等方式,异构到jimdb
c) 数据异构,将列表类或多条件复杂查询数据,异构到ES。查询需注意深分页及一次查询的数据量过多问题。
a) 对于数据要求实时性不高的场景,并且为了快速的减少系统问题,可采取缓存read-through的方式,该方式系统改造量低,简单。但是要注意,避免不存在的key缓存穿透(不存在key设置特殊值、bloomfilter)。缓存雪崩问题。
b) 数据异构,将依赖的底层数据通过binlake或双写等等方式,异构到jimdb
c) 数据异构,将列表类或多条件复杂查询数据,异构到ES。查询需注意深分页及一次查询的数据量过多问题。
复杂的统计类功能,使用离线计算的方式,避免实时通过库函数进行计算统计
浏览记录、日志类或其他不重要功能,可通过mq,同步写转异步写
数据库垂直拆分,业务隔离
底层资源进行拆分,按业务维度,不同业务拆分为不同应用 ,使用不同的资源。
数据库水平拆分,分库分表
1.库水平拆分会出现很多问题,无法join,无法聚合查询,可采用异构数据到ES等方式解决。
2、将无用的历史数据进行归档。
2、将无用的历史数据进行归档。
不适合使用Mysql场景
复杂、多字段、模糊查询
针对问题1,对于复杂、模糊查询等,更适合使用ES搜索引擎去处理。
a) 如果对数据的实时性要求不高,建议通过binlake或mq的方式,异步构建ES索引。
b) 如果对数据实时性要求很高,可通过双写的方式处理,失败可以采用异步补偿的方式。另外ES本身段刷新有1秒的延迟,1s后数据才可搜索。如果不可接受并且数据修改频率低,可通过setRefresh方法强制刷新,立刻即可搜索到。写入量大的时候慎用。
a) 如果对数据的实时性要求不高,建议通过binlake或mq的方式,异步构建ES索引。
b) 如果对数据实时性要求很高,可通过双写的方式处理,失败可以采用异步补偿的方式。另外ES本身段刷新有1秒的延迟,1s后数据才可搜索。如果不可接受并且数据修改频率低,可通过setRefresh方法强制刷新,立刻即可搜索到。写入量大的时候慎用。
超大文本的存储(text类型)。大文本查询,会耗费mysql大量的内存空间,造成热数据被置换出去,查询效率降低
建议使用nosql库,hbase、es等存储
日志类大数量的存储
建议使用nosql库,hbase、es等存储
超高并发的查询
简单查询,jimdb是非常好选择。如果有业务需要复杂查询,更建议使用ES多集群方式处理。
常见问题
简述在MySQL数据库中MyISAM和InnoDB的区别
MyISAM:
不支持事务,但是每次查询都是原子的;
支持表级锁,即每次操作是对整个表加锁;
存储表的总行数;
一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
采用菲聚集索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致,但是辅索引不用保证唯一性。
InnoDb:
支持ACID的事务,支持事务的四种隔离级别;
支持行级锁及外键约束:因此可以支持写并发;
不存储总行数;
一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
不支持事务,但是每次查询都是原子的;
支持表级锁,即每次操作是对整个表加锁;
存储表的总行数;
一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
采用菲聚集索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致,但是辅索引不用保证唯一性。
InnoDb:
支持ACID的事务,支持事务的四种隔离级别;
支持行级锁及外键约束:因此可以支持写并发;
不存储总行数;
一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
是否支持MVCC :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。
Datetime 和 Timestamp 区别
通常我们都会首选 Timestamp
时区
DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。
Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
# 查看当前会话时区
SELECT @@session.time_zone;
# 设置当前会话时区
SET time_zone = 'Europe/Helsinki';
SET time_zone = "+00:00";
# 数据库全局时区设置
SELECT @@global.time_zone;
# 设置全局时区
SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
SELECT @@session.time_zone;
# 设置当前会话时区
SET time_zone = 'Europe/Helsinki';
SET time_zone = "+00:00";
# 数据库全局时区设置
SELECT @@global.time_zone;
# 设置全局时区
SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
存储空间 与 时间范围
DateTime 需要耗费 8 个字节的存储空间
DateTime :1000-01-01 000000 ~ 9999-12-31 235959
Timestamp 只需要使用 4 个字节的存储空间,
Timestamp: 1970-01-01 000001 ~ 2037-12-31 235959
其实用long型数值表示 程序做转换 也可!
使用索引的注意事项
在经常需要搜索的列上,可以加快搜索的速度;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;B+Tree
对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
避免 where 子句中对宇段施加函数,这会造成无法命中索引。
在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
在使用 limit offset 查询缓慢时,可以借助索引来提高性能
被频繁更新的字段应该慎重建立索引
尽可能的考虑建立联合索引而不是单列索引
为什么索引能提高查询速度
MySql基础组件
连接器
身份认证和权限相关(登录 MySQL 的时候)。
查询缓存
执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
分析器
没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
第一步,词法分析,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
第二步,语法分析,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
优化器
按照 MySQL 认为最优的方案去执行。
执行器
执行语句,然后从存储引擎返回数据。
存储引擎
MyISAM
文件
frm文件:存储表的定义数据
MYD文件:存放表具体记录的数据
MYI文件:存储索引
特点索引存放的是数据具体存放在磁盘上的地址
InnoDB
一张表最多有16个索引,每个索引的最大长度是255个字节
事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,上图也看到了,InnoDB是默认的MySQL引擎。
ISAM
CSV.....
锁
分类
按照锁机制分类
共享锁(读锁)
MyISAM表共享锁
InnoDb行共享锁
InnoDB排它锁(写锁)
排它锁又称:写锁
当一个事务对某几个上写锁时,不允许其他事务写,但允许读
更不允许其他事务给这几行上任何锁。包括写锁。
两个事务不能锁同一个索引
insert ,delete , update在事务中都会自动默认加上排它锁
行锁必须有索引才能实现,否则会自动锁全表,那么就不是行锁了
按照锁的粒度分类
表锁(偏读)
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
行锁(偏写)
使用行级锁定的主要是InnoDB存储引擎。
排他锁: X锁
事务中显式加锁:SELECT * FROM table_name WHERE ... FOR UPDATE
共享锁:S锁
事务中显式加锁:SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
意向排他锁:IX锁
意向共享锁:IS锁
页锁(DBD引擎采用)
表级锁和行级锁的区别
表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如OLAP系统
行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统
InnoDB存储引擎 行锁的实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁
Record lock:单个行记录上的锁
Gap lock:间隙锁,锁定一个范围,不包括记录本身
(1)防止幻读,以满足相关隔离级别的要求。对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;
(2)为了满足其恢复和复制的需要。
Next-key lock:record+gap 锁定一个范围,包含记录本身
常见问题
innodb对于行的查询使用next-key lock
Next-locking keying为了解决Phantom Problem幻读问题
当查询的索引含有唯一属性时,将next-key lock降级为record key
Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
innoDB使用的是行锁myisam使用的是表锁
行锁退化到表锁
更新的时候没有索引或者索引失效时,InnoDB 的行锁变表锁
间隙锁
间隙锁(Gap Lock)是Innodb在可重复读提交下为了解决幻读问题时引入的锁机制,
意向锁
行锁是行级别的,粒度比较小,好,那我要你在拿行锁之前,必须先拿一个假的表锁,表示你想去锁住表里的某一行或者多行记录。
这样,Mysql 在判断表里有没有记录被锁定,就不需要遍历整张表了,它只需要看看,有没有人拿了这个假的表锁。
这样,Mysql 在判断表里有没有记录被锁定,就不需要遍历整张表了,它只需要看看,有没有人拿了这个假的表锁。
逻辑结构修改
锁表
修改表结构会导致表锁,数据量大修改数据很长,导致大量用户阻塞,无法访问
系统升级,加字段正确方法
首先创建一个和你要执行的alter操作的表一样的空的表结构
执行我们赋予的表结构的修改,然后copy原表中的数据到新表里面。
在原表上创建一个触发器在数据copy的过程中,将原表的更新数据的操作全部更新到新的表中来
copy完成之后,用rename table 新表代替原表,默认删除原表
用插件解决加字段问题
pt-online-schema-change
pt-online-schema-change h=127.0.0.1,u=root,D=mysqldemo,t=product_info --alter "modify product_name varchar(150) not null default '' " --execute
如何给数据库加锁
InnoDB
对于普通SELECT语句,InnoDB不会加任何锁;
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);
开启事务加锁
MyISAM
表锁
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁
如何避免死锁
(1)在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
(2)在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
(3)在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
(4)在REPEATABLE-READ隔离级别下,如果两个线程同时对相同条件记录用SELECT...FOR UPDATE加排他锁,在没有符合该条件记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成READ COMMITTED,就可避免问题。
(5)当隔离级别为READ COMMITTED时,如果两个线程都先执行SELECT...FOR UPDATE,判断是否存在符合条件的记录,如果没有,就插入记录。此时,只有一个线程能插入成功,另一个线程会出现锁等待,当第1个线程提交后,第2个线程会因主键重出错,但虽然这个线程出错了,却会获得一个排他锁。这时如果有第3个线程又来申请排他锁,也会出现死锁。对于这种情况,可以直接做插入操作,然后再捕获主键重异常,或者在遇到主键重错误时,总是执行ROLLBACK释放获得的排他锁。
死锁检测
Innodb死锁检测
通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况:
InnoDB_row_lock_current_waits:当前正在等待锁定的数量;
InnoDB_row_lock_time:从系统启动到现在锁定总时间长度;
InnoDB_row_lock_time_avg:每次等待所花平均时间;
InnoDB_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
InnoDB_row_lock_waits:系统启动后到现在总共等待的次数;
InnoDB_row_lock_time:从系统启动到现在锁定总时间长度;
InnoDB_row_lock_time_avg:每次等待所花平均时间;
InnoDB_row_lock_time_max:从系统启动到现在等待最常的一次所花的时间;
InnoDB_row_lock_waits:系统启动后到现在总共等待的次数;
MySQL官方手册中也提到了这个问题,实际上在InnoDB发现死锁之后,会计算出两个事务各自插入、更新或者删除的数据量来判定两个事务的大小。也就是说哪个事务所改变的记录条数越多,在死锁中就越不会被回滚掉。
但是有一点需要注意的就是,当产生死锁的场景中涉及到不止InnoDB存储引擎的时候,InnoDB是没办法检测到该死锁的,这时候就只能通过锁定超时限制参数InnoDB_lock_wait_timeout来解决。
但是有一点需要注意的就是,当产生死锁的场景中涉及到不止InnoDB存储引擎的时候,InnoDB是没办法检测到该死锁的,这时候就只能通过锁定超时限制参数InnoDB_lock_wait_timeout来解决。
这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
在InnoDB的事务管理和锁定机制中,有专门检测死锁的机制,会在系统中产生死锁之后的很短时间内就检测到该死锁的存在。当InnoDB检测到系统中产生了死锁之后,InnoDB会通过相应的判断来选这产生死锁的两个事务中较小的事务来回滚,而让另外一个较大的事务成功完成。
常规思路
抢占加事务回滚的方式
当事务开始执行时会先获得一个时间戳,数据库程序会根据事务的时间戳决定事务应该等待还是回滚,在这时也有两种机制
wait-die 机制
当执行事务的时间戳小于另一事务时,即事务 A 先于 B 开始,那么它就会等待另一个事务释放对应资源的锁,否则就会保持当前的时间戳并回滚。
wound-wait
当前事务如果先于另一事务执行并请求了另一事务的资源,那么另一事务会立刻回滚,将资源让给先执行的事务,否则就会等待其他事务释放资源
MVCC (多版本并发控制)
https://draveness.me/database-concurrency-control/
分类
MySQL 与 MVCC
MySQL 中实现的多版本两阶段锁协议(Multiversion 2PL)将 MVCC 和 2PL 的优点结合了起来,
每一个版本的数据行都具有一个唯一的时间戳,当有读事务请求时,数据库程序会直接从多个版本的数据项中具有最大时间戳的返回。
更新操作就稍微有些复杂了,事务会先读取最新版本的数据计算出数据更新后的结果,然后创建一个新版本的数据,新数据的时间戳是目前数据行的最大版本 +1:
数据版本的删除也是根据时间戳来选择的,MySQL 会将版本最低的数据定时从数据库中清除以保证不会出现大量的遗留内容。
PostgreSQL 与 MVCC
PostgreSQL 中都是使用乐观并发控制的,这也就导致了 MVCC 在于乐观锁结合时的实现上有一些不同,最终实现的叫做多版本时间戳排序协议(Multiversion Timestamp Ordering),在这个协议中,所有的事务在执行之前都会被分配一个唯一的时间戳,每一个数据项都有读写两个时间戳
当 PostgreSQL 的事务发出了一个读请求,数据库直接将最新版本的数据返回,不会被任何操作阻塞,而写操作在执行时,事务的时间戳一定要大或者等于数据行的读时间戳,否则就会被回滚。
这种 MVCC 的实现保证了读事务永远都不会失败并且不需要等待锁的释放,对于读请求远远多于写请求的应用程序,乐观锁加 MVCC 对数据库的性能有着非常大的提升;虽然这种协议能够针对一些实际情况做出一些明显的性能提升,但是也会导致两个问题,一个是每一次读操作都会更新读时间戳造成两次的磁盘写入,第二是事务之间的冲突是通过回滚解决的,所以如果冲突的可能性非常高或者回滚代价巨大,数据库的读写性能还不如使用传统的锁等待方式。
最佳SQL实践
模糊查询
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决
说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
外键和级联
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风 险;外键影响数据库的插入速度
说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风 险;外键影响数据库的插入速度
使用外键带来的问题
增加了复杂性
增加了额外工作
外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
对分库分表不友好
优点
级联操作方便,减轻了程序代码量;
保证了数据库数据的一致性和完整性;
@Transactional
@Transactional事务不要滥用。事务会影响数据库的QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
大表优化
1. 限定数据的范围
2. 读/写分离
3. 垂直分区
垂直拆分的优点: 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
4. 水平分区
客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现
中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
连接池带来的池化思想
在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。
连接池还减少了用户必须等待建立与数据库的连接的时间。
分库分表之后,id 主键如何处理?
UUID:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
数据库自增 id : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
利用 redis 生成 id : 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
Twitter的snowflake算法 :Github 地址:https://github.com/twitter-archive/snowflake。
美团的Leaf分布式ID生成系统 :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:
一条SQL语句执行得很慢的原因有哪些?
大多数情况是正常的,只是偶尔会出现很慢的情况。
数据库在刷新脏页(flush)
当我们要往数据库插入一条数据、或者要更新一条数据的时候,我们知道数据库会在内存中把对应字段的数据更新了,但是更新之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到 redo log 日记中去,等到空闲的时候,在通过 redo log 里的日记把最新的数据同步到磁盘中去。
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
当我们要往数据库插入一条数据、或者要更新一条数据的时候,我们知道数据库会在内存中把对应字段的数据更新了,但是更新之后,这些更新的字段并不会马上同步持久化到磁盘中去,而是把这些更新的记录写入到 redo log 日记中去,等到空闲的时候,在通过 redo log 里的日记把最新的数据同步到磁盘中去。
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
刷脏页有下面4种场景
redolog写满了
内存不够用了
MySQL 认为系统“空闲”的时候
MySQL 正常关闭的时候
拿不到锁
show processlist
show processlist
在数据量不变的情况下,这条SQL语句一直以来都执行的很慢。
没用到索引
字段没有索引
字段有索引,但却没有用索引
函数操作导致没有用上索引
数据库自己选错索引
MySQL高性能优化规范建议
设计范式
分类
1NF
符合1NF的关系中的每个属性都不可再分
2Nf
二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
3NF
在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。
BCNF
数据库表中如果不存在任何字段对任一候选关键字段的传递函数依赖则符BCNF范式。
Oracle
.........
NoSQL数据库
Redis
基本知识
介绍
Redis 是一个开源,高级的键值存储和一个适用的解决方案,用于构建高性能,可扩展的 Web 应用程序。Redis 也被作者戏称为 数据结构服务器 ,这意味着使用者可以通过一些命令,基于带有 TCP 套接字的简单 服务器-客户端 协议来访问一组 可变数据结构 。(
优点
异常快 - Redis 非常快,每秒可执行大约 110000 次的设置(SET)操作,每秒大约可执行 81000 次的读取/获取(GET)操作。
支持丰富的数据类型 - Redis 支持开发人员常用的大多数数据类型,例如列表,集合,排序集和散列等等。这使得 Redis 很容易被用来解决各种问题,因为我们知道哪些问题可以更好使用地哪些数据类型来处理解决。
操作具有原子性 - 所有 Redis 操作都是原子操作,这确保如果两个客户端并发访问,Redis 服务器能接收更新的值。
多实用工具 - Redis 是一个多实用工具,可用于多种用例,如:缓存,消息队列(Redis 本地支持发布/订阅),应用程序中的任何短期数据,例如,web应用程序中的会话,网页命中计数等。
数据结构
基本数据结构
字符串 String
string 是最常用的一种数据类型,普通的key/value存储都可以归结为string类型,value不仅是string,也可以是数字。其他几种数据类型的构成元素也都是字符串,注意Redis规定字符串的长度不能超过512M
编码 字符串对象的编码可以是int raw embstr
int编码
保存的是可以用long类型表示的整数值
raw编码
保存长度大于44字节的字符串
embstr编码
保存长度小于44字节的字符串
Redis中对于浮点型也是作为字符串保存的,在需要时再将其转换成浮点数类型
哈希表 Hash
编码
hash对象的编码可以是zipmap或者hashtable
当使用zipmap,也就是压缩列表作为底层实现时,新增的键值是保存到压缩列表的表尾。
hashtable 编码的hash表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。Redis中的字典相当于Java里面的HashMap,内部实现也差不多类似,都是通过“数组+链表”的链地址法来解决哈希冲突的,这样的结构吸收了两种不同数据结构的优点。
当使用zipmap,也就是压缩列表作为底层实现时,新增的键值是保存到压缩列表的表尾。
hashtable 编码的hash表对象底层使用字典数据结构,哈希对象中的每个键值对都使用一个字典键值对。Redis中的字典相当于Java里面的HashMap,内部实现也差不多类似,都是通过“数组+链表”的链地址法来解决哈希冲突的,这样的结构吸收了两种不同数据结构的优点。
编码转换
当同时满足下面两个条件使用ziplist编码,否则使用hashtable编码
列表保存元素个数小于512个
每个元素长度小于64字节
hash是一个String类型的field和value之间的映射表
Hash特别适合存储对象
所存储的成员较少时数据存储为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht
Hash命令详解
hset/hget
hset hashname hashkey hashvalue
hget hashname hashkey
hmset/hmget
hmset hashname hashkey1hashvalue1 hashkey2 hashvalue2 hashkey3 hashvalue3
hget hashname hashkey1 hashkey2 hashkey3
hsetnx/hgetnx
hincrby/hdecrby
渐进式扩容
渐进式 rehash 会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及 hash 操作指令中,循序渐进的把旧字典的内容迁移到新字典中。当搬迁完成了,就会使用新的 hash 结构取而代之。
正常情况下,当 hash 表中 元素的个数等于第一维数组的长度时,就会开始扩容,扩容的新数组是 原数组大小的 2 倍。不过如果 Redis 正在做 bgsave(持久化命令),为了减少内存也得过多分离,Redis 尽量不去扩容,但是如果 hash 表非常满了,达到了第一维数组长度的 5 倍了,这个时候就会 强制扩容。
hash 表因为元素逐渐被删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少 hash 表的第一维数组空间占用。所用的条件是 元素个数低于数组长度的 10%,缩容不会考虑 Redis 是否在做 bgsave。
应用场景
对于 hash 数据类型,value 存放的是键值对,比如可以做单点登录存放用户信息。
存放商品信息,实现购物车
优点 / 缺点
优点
同类数据归类整合存储,方便数据管理,比如单个用户的所有商品都放在一个hash表里面。
相比string操作消耗内存cpu更小
缺点
hash结构的存储消耗要高于单个字符串
过期功能不能使用在field上,只能用在key上
redis集群架构不适合大规模使用
列表(链表实现)List
list列表,它是简单的字符串列表,你可以添加一个元素到列表的头部,或者尾部。
编码
列表对象的编码可以是ziplist(压缩列表)和linkedlist(双端链表)。
编码转换
同时满足下面两个条件时使用压缩列表:
列表保存元素个数小于512个
每个元素长度小于64字节
不能满足上面两个条件使用linkedlist(双端列表)编码
常用命令
LPUSH 和 RPUSH 分别可以向 list 的左边(头部)和右边(尾部)添加一个新元素;
LRANGE 命令可以从 list 中取出一定范围的元素;
LINDEX 命令可以从 list 中取出指定下表的元素,相当于 Java 链表操作中的 get(int index) 操作;
实现数据结构
Stack(栈)
LPUSH+LPOP
Queue(队列)
LPUSH + RPOP
Blocking MQ(阻塞队列)
LPUSH+BRPOP
集合 set
集合对象set是string类型(整数也会转成string类型进行存储)的无序集合。注意集合和列表的区别:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
编码
集合对象的编码可以是intset或者hashtable
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值全部设置为null。当使用HT编码时,Redis中的集合SET相当于Java中的HashSet,内部的键值对是无序的,唯一的。内部实现相当于一个特殊的字典,字典中所有value都是NULL。
编码转换
当集合满足下列两个条件时,使用intset编码:
集合对象中的所有元素都是整数
集合对象所有元素数量不超过512
集合对象的编码可以是intset或者hashtable
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合中。
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,这里的每个字符串对象就是一个集合中的元素,而字典的值全部设置为null。当使用HT编码时,Redis中的集合SET相当于Java中的HashSet,内部的键值对是无序的,唯一的。内部实现相当于一个特殊的字典,字典中所有value都是NULL。
编码转换
当集合满足下列两个条件时,使用intset编码:
集合对象中的所有元素都是整数
集合对象所有元素数量不超过512
sadd: 向集合中添加元素 (set不允许元素重复)
smembers: 查看集合中的元素
srem: 删除集合元素
spop: 随机返回删除的key
sdiff :返回两个集合的不同元素 (哪个集合在前就以哪个集合为标准)
smembers: 查看集合中的元素
srem: 删除集合元素
spop: 随机返回删除的key
sdiff :返回两个集合的不同元素 (哪个集合在前就以哪个集合为标准)
应用场景
对于 set 数据类型,由于底层是字典实现的,查找元素特别快,另外set 数据类型不允许重复,利用这两个特性我们可以进行全局去重,比如在用户注册模块,判断用户名是否注册;微信点赞,微信抽奖小程序
另外就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好,可能认识的人等功能。
有序集合 sort set
和集合对象相比,有序集合对象是有序的。与列表使用索引下表作为排序依据不同,有序集合为每一个元素设置一个分数(score)作为排序依据。
编码
有序集合的编码可以使ziplist或者skiplist
有序集合的编码可以使ziplist或者skiplist
当有序结合对象同时满足以下两个条件时,对象使用ziplist编码,否则使用skiplist编码
保存的元素数量小于128
保存的所有元素长度都小于64字节
ziplist编码的有序集合对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。并且压缩列表内的集合元素按分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
skiplist编码的依序集合对象使用zset结构作为底层实现,一个zset结构同时包含一个字典和一个跳跃表
跳跃列表 (SkipList)
使用原因
因为 zset 要支持随机的插入和删除,所以它 不宜使用数组来实现,关于排序问题,我们也很容易就想到 红黑树/ 平衡树 这样的树形结构,为什么 Redis 不使用这样一些结构呢?
性能考虑: 在高并发的情况下,树形结构需要执行一些类似于 rebalance 这样的可能涉及整棵树的操作,相对来说跳跃表的变化只涉及局部
实现考虑: 在复杂度与红黑树相同的情况下,跳跃表实现起来更简单,看起来也更加直观;
实现思路
https://mp.weixin.qq.com/s?__biz=MzA4NTg1MjM0Mg==&mid=2657261425&idx=1&sn=d840079ea35875a8c8e02d9b3e44cf95&scene=21#wechat_redirect
平均时间复杂度
O(log n)
常用命令
zrem: 删除集合中名称为key的元素member
zincrby: 以指定值去自动递增
zcard: 查看元素集合的个数
zcount: 返回score在给定区间中的数量
zrangebyscore: 找到指定区间范围的数据进行返回
zremrangebyrank zset from to: 删除索引
zremrangebyscore zset from to: 删除指定序号
zrank: 返回排序索引 (升序之后再找索引)
zrevrank: 返回排序索引 (降序之后再找索引)
应用场景
对于 zset 数据类型,有序的集合,可以做范围查找,排行榜应用,取 TOP N 操作等。
对于 zset 数据类型,有序的集合,可以做范围查找,排行榜应用,取 TOP N 操作等。
地理位置(GeoHash )
GeoHash 算法将 二维的经纬度 数据映射到 一维 的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算 「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了。
它的核心思想就是把整个地球看成是一个 二维的平面,然后把这个平面不断地等分成一个一个小的方格,每一个 坐标元素都位于其中的 唯一一个方格 中,等分之后的 方格越小,那么坐标也就 越精确
常见命令
增加 geoadd
geoadd company 116.48105 39.996794 juejin
距离 geodist
geodist company juejin ireader km
获取元素位置 geopos
geopos company juejin
获取元素的 hash 值 geohash
geohash company ireader
附近的东西 georadiusbymember 、 georadius
georadiusbymember company ireader 20 km count 3 asc
HyperLogLog
关于基数统计 通常是用来统计一个集合中不重复的元素个数。
实现方案
B 树
B 树最大的优势就是插入和查找效率很高,如果用 B 树存储要统计的数据,可以快速判断新来的数据是否存在,并快速将元素插入 B 树。要计算基础值,只需要计算 B 树的节点个数就行了。
不过将 B 树结构维护到内存中,能够解决统计和计算的问题,但是 并没有节省内存。
不过将 B 树结构维护到内存中,能够解决统计和计算的问题,但是 并没有节省内存。
bitmap
bitmap 可以理解为通过一个 bit 数组来存储特定数据的一种数据结构,每一个 bit 位都能独立包含信息,bit 是数据的最小存储单位,因此能大量节省空间,也可以将整个 bit 数据一次性 load 到内存计算。
bitmap 还有一个明显的优势是 可以轻松合并多个统计结果,只需要对多个结果求异或就可以了,也可以大大减少存储内存。
Java 的 bitSet 实现了该数据结构
应用
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话。
2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
将bit-map扩展一下,用2bit表示一个数即可:0表示未出现;1表示出现一次;2表示出现2次及以上,即重复,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
解法一:可以用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
解法一:可以用位图/Bitmap的方法,申请512M的内存,一个bit位代表一个unsigned int值。读入40亿个数,设置相应的bit位,读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
使用
PFADD
PFCOUNT
PFMEGER
存储
稀疏存储方式
多个连续桶的计数值都是零
多个连续桶的计数值都是零
00xxxxxx:前缀两个零表示接下来的 6bit 整数值加 1 就是零值计数器的数量,注意这里要加 1 是因为数量如果为零是没有意义的。比如 00010101 表示连续 22 个零值计数器。
01xxxxxx yyyyyyyy:6bit 最多只能表示连续 64 个零值计数器,这样扩展出的 14bit 可以表示最多连续 16384 个零值计数器。这意味着 HyperLogLog 数据结构中 16384 个桶的初始状态,所有的计数器都是零值,可以直接使用 2 个字节来表示。
1vvvvvxx:中间 5bit 表示计数值,尾部 2bit 表示连续几个桶。它的意思是连续 (xx +1) 个计数值都是 (vvvvv + 1)。比如 10101011 表示连续 4 个计数值都是 11。
上面第三种方式 的计数值最大只能表示到 32,而 HyperLogLog 的密集存储单个计数值用 6bit 表示,最大可以表示到 63。当稀疏存储的某个计数值需要调整到大于 32 时,Redis 就会立即转换 HyperLogLog 的存储结构,将稀疏存储转换成密集存储。
密集存储
16384 个 6 bit 连续串成
一个字节是由 8 个 bit 组成的,这样 6 bit 排列的结构就会导致,有一些桶会 跨越字节边界,我们需要 对这一个或者两个字节进行适当的移位拼接 才可以得到具体的计数值。
位图 bitmap
bitmap 可以理解为通过一个 bit 数组来存储特定数据的一种数据结构,每一个 bit 位都能独立包含信息,bit 是数据的最小存储单位,因此能大量节省空间,也可以将整个 bit 数据一次性 load 到内存计算。
指令
SETBIT
GETBIT
BITCOUNT
BITPOS
BITOP
BITFIELD
GETBIT
BITCOUNT
BITPOS
BITOP
BITFIELD
使用场景
布隆过滤器
布隆过滤器(Bloom Filter) 就是这样一种专门用来解决去重问题的高级数据结构。
使用场景
大数据判断是否存在:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1 的级别,但是当数据量起来之后,还是只能考虑布隆过滤器。
解决缓存穿透:我们经常会把一些热点数据放在 Redis 中当作缓存,例如产品详情。 通常一个请求过来之后我们会先查询缓存,而不用直接读取数据库,这是提升性能最简单也是最普遍的做法,但是 如果一直请求一个不存在的缓存,那么此时一定不存在缓存,那就会有 大量请求直接打到数据库 上,造成 缓存穿透,布隆过滤器也可以用来解决此类问题。
爬虫/ 邮箱等系统的过滤:平时不知道你有没有注意到有一些正常的邮件也会被放进垃圾邮件目录中,这就是使用布隆过滤器 误判 导致的。
布隆过滤器原理
布隆过滤器的使用
Redis 4.0
bf.add 添加元素
bf.madd 添加多个元素
bf.exists 查询元素是否存在
bf.mexists
bf.reserve 显式创建过滤器
key
error_rate
error_rate 越低,需要的空间越大
initial_size
表示预计放入的元素数量
Java的 Guava带有布隆过滤器实现
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
内存回收和内存共享
内存回收 因为c语言不具备自动内存回收功能,当将redisObject对象作为数据库的键或值而不是作为参数存储时其生命周期是非常长的,为了解决这个问题,Redis自己构建了一个内存回收机制,通过redisobject结构中的refcount实现.这个属性会随着对象的使用状态而不断变化。
创建一个新对象,属性初始化为1
对象被一个新程序使用,属性refcount加1
对象不再被一个程序使用,属性refcount减1
当对象的引用计数值变为0时,对象所占用的内存就会被释放
内存共享 refcount属性除了能实现内存回收以外,还能实现内存共享
将数据块的键的值指针指向一个现有值的对象
将被共享的值对象引用refcount加1 Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为o(1),对于普通字符串,判断复杂度为o(n);而对于哈希,列表,集合和有序集合,判断的复杂度为o(n^2).虽然共享的对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象。
redis的使用场景
时间轴、队列应用场景设计
购物车开发与设计实战
Redis与Lua模拟抢红包实战
网站投票设计与开发实战
redis的底层协议
能谈下Redis的底层协议吗
RESP协议
RESP是什么,在Redis怎么体现
基于TCP的应用层协议RESP
RESP底层使用的是TCP的连接方式,通过tcp进行数据传输,然后根据解析规则解析相应信息,完成交互
持久化
分类
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,触发RDB持久化过程分为手动触发和自动触发
触发机制
手动触发分别对应save和bgsave命令
save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子 进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
自动触发RDB的持久
使用save相关配置,如“save m n”。表示m秒内数据集存在n次修改 时,自动触发bgsave。
执行debug reload命令重新加载Redis时,也会自动触发save操作。
默认情况下执行shutdown命令时,如果没有开启AOF持久化功能则 自动执行bgsave。
如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点,
执行流程
执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进 程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通 过info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒
父进程fork完成后,bgsave命令返回“Background saving started”信息并不再阻塞父进程,可以继续响应其他命令。
子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后 对原有文件进行原子替换。执行lastsave命令可以获取最后一次生成RDB的 时间,对应info统计的rdb_last_save_time选项。
进程发送信号给父进程表示完成,父进程更新统计信息,具体见 info Persistence下的rdb_*相关选项。
优缺点
优点
RDB是一个紧凑压缩的二进制文件,代表Redis在某个时间点上的数据 快照。非常适用于备份,全量复制等场景。比如每6小时执行bgsave备份, 并把RDB文件拷贝到远程机器或者文件系统中(如hdfs),用于灾难恢复。
Redis加载RDB恢复数据远远快于AOF的方式。
缺点
RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运 行都要执行fork操作创建子进程,属于重量级操作,频繁执行成本过高。
DB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式 的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题。
AOF
开启方式
配置:appendonly yes,默认不开启
AOF文件名 通过appendfilename配置设置,默认文件名是appendonly.aof
执行流程
命令写入 (append)
追加到aof_buf(缓冲区)中
文件同步(sync)
Redis使用单线程响应命令,如 果每次写AOF文件命令都直接追加到硬盘,那么性能完全取决于当前硬盘负 载。先写入缓冲区aof_buf中,还有另一个好处,Redis可以提供多种缓冲区同步硬盘的策略,在性能和安全性方面做出平衡
文件重写(rewrite)
AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的
进程内已经超时的数据不再写入文件。
旧的AOF文件含有无效命令,如del key1、hdel key2、srem keys、set a111、set a222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为:lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢 出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
更小的AOF 文件可以更快地被Redis加载
触发
·手动触发:直接调用bgrewriteaof命令。
自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机
·auto-aof-rewrite-min-size:表示运行AOF重写时文件最小体积,默认 为64MB。
auto-aof-rewrite-percentage:代表当前AOF文件空间 (aof_current_size)和上一次重写后AOF文件空间(aof_base_size)的比值。
自动触发时机=aof_current_size>auto-aof-rewrite-minsize&&(aof_current_size-aof_base_size)/aof_base_size>=auto-aof-rewritepercentage
重启加载 (load)
AOF持久化开启且存在AOF文件时,优先加载AOF文件,
AOF关闭或者AOF文件不存在时,加载RDB文件,
加载AOF/RDB文件成功后,Redis启动成功。
AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
Redis 4.0混合持久化
aof-use-rdb-preamble yes
如果开启了混合持久化,aof在重写时,不再是单纯将内存数据转换为RESP命令写入aof文件,而是将重写这一刻之前的内存做rdb快照处理,并且将rdb快照内容和增量的aof修改内存数据的命令存在一起,都写入新的aof文件,新的aof文件一开始不叫appendonly.aof,等到重写完成后,新的aof文件才会进行改名,原子的覆盖原有的aof文件,完成新旧两个aof文件的替换。
于是在redis重启的时候,可以先加载rdb文件,然后再重放增量的aof日志就可以完全替代之前的aof全量文件重放,因此重启效率大幅得到提高。
于是在redis重启的时候,可以先加载rdb文件,然后再重放增量的aof日志就可以完全替代之前的aof全量文件重放,因此重启效率大幅得到提高。
Lua脚本
基本用法
EVAL script numkeys key [key ...] arg [arg ...]
SCRIPT LOAD script
EVALSHA sha1 numkeys key [key ...] arg [arg ...]
SCRIPT EXISTS script [script ...]
SCRIPT FLUSH
SCRIPT KILL
redis-cli --eval /Users/jihite/activeuser.lua user , 1
主要优势
减少网络开销:多个请求通过脚本一次发送,减少网络延迟
原子操作:将脚本作为一个整体执行,中间不会插入其他命令,无需使用事务
复用:客户端发送的脚本永久存在redis中,其他客户端可以复用脚本
可嵌入性:可嵌入JAVA,C#等多种编程语言,支持不同操作系统跨平台交互
发布订阅
思路
Publisher 往 channel 中发布消息时,关注了指定 channel 的 Consumer 就能够同时受到消息。
关注方式( 模式订阅)
命令
# 订阅频道:
SUBSCRIBE channel [channel ....] # 订阅给定的一个或多个频道的信息
PSUBSCRIBE pattern [pattern ....] # 订阅一个或多个符合给定模式的频道
# 发布频道:
PUBLISH channel message # 将消息发送到指定的频道
# 退订频道:
UNSUBSCRIBE [channel [channel ....]] # 退订指定的频道
PUNSUBSCRIBE [pattern [pattern ....]] #退订所有给定模式的频道
缺点
不持久化消息: 如果 Redis 停机重启,PubSub 的消息是不会持久化的,毕竟 Redis 宕机就相当于一个消费者都没有,所有的消息都会被直接丢弃。
没有 Ack 机制,也不保证数据的连续: PubSub 的生产者传递过来一个消息,Redis 会直接找到相应的消费者传递过去。如果没有一个消费者,那么消息会被直接丢弃。如果开始有三个消费者,其中一个突然挂掉了,过了一会儿等它再重连时,那么重连期间的消息对于这个消费者来说就彻底丢失了。
Stream
Redis 5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了 持久化消息队列
Redis Stream 从概念上来说,就像是一个 仅追加内容 的 消息链表,把所有加入的消息都一个一个串起来,每个消息都有一个唯一的 ID 和内容,这很简单,让它复杂的是从 Kafka 借鉴的另一种概念:消费者组(Consumer Group) (思路一致,实现不同)
Consumer Group:消费者组,可以简单看成记录流状态的一种数据结构。消费者既可以选择使用 XREAD 命令进行 独立消费,也可以多个消费者同时加入一个消费者组进行 组内消费。同一个消费者组内的消费者共享所有的 Stream 信息,同一条消息只会有一个消费者消费到,这样就可以应用在分布式的应用场景中来保证消息的唯一性。
last_delivered_id:用来表示消费者组消费在 Stream 上 消费位置 的游标信息。每个消费者组都有一个 Stream 内 唯一的名称,消费者组不会自动创建,需要使用 XGROUP CREATE 指令来显式创建,并且需要指定从哪一个消息 ID 开始消费,用来初始化 last_delivered_id 这个变量。
pending_ids:每个消费者内部都有的一个状态变量,用来表示 已经 被客户端 获取,但是 还没有 ack 的消息。记录的目的是为了 保证客户端至少消费了消息一次,而不会在网络传输的中途丢失而没有对消息进行处理。如果客户端没有 ack,那么这个变量里面的消息 ID 就会越来越多,一旦某个消息被 ack,它就会对应开始减少。这个变量也被 Redis 官方称为 PEL (Pending Entries List)。
消息
消息 ID
消息 ID 如果是由 XADD 命令返回自动创建的话,那么它的格式会像这样:timestampInMillis-sequence (毫秒时间戳-序列号),例如 1527846880585-5,它表示当前的消息是在毫秒时间戳 1527846880585 时产生的,并且是该毫秒内产生的第 5 条消息。
这些 ID 的格式看起来有一些奇怪,为什么要使用时间来当做 ID 的一部分呢? 一方面,我们要 满足 ID 自增 的属性,另一方面,也是为了 支持范围查找 的功能。由于 ID 和生成消息的时间有关,这样就使得在根据时间范围内查找时基本上是没有额外损耗的。
当然消息 ID 也可以由客户端自定义,但是形式必须是 "整数-整数",而且后面加入的消息的 ID 必须要大于前面的消息 ID。
消息内容
消息内容就是普通的键值对,形如 hash 结构的键值对。
命令
增删改查示例
xadd:追加消息
xdel:删除消息,这里的删除仅仅是设置了标志位,不影响消息总长度
xrange:获取消息列表,会自动过滤已经删除的消息
xlen:消息长度
del:删除Stream
独立消费示例
# 从Stream头部读取两条消息
127.0.0.1:6379> xread count 2 streams codehole 0-0
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
2) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
# 从Stream尾部读取一条消息,毫无疑问,这里不会返回任何消息
127.0.0.1:6379> xread count 1 streams codehole $
(nil)
# 从尾部阻塞等待新消息到来,下面的指令会堵住,直到新消息到来
127.0.0.1:6379> xread block 0 count 1 streams codehole $
# 我们从新打开一个窗口,在这个窗口往Stream里塞消息
127.0.0.1:6379> xadd codehole * name youming age 60
1527852774092-0
# 再切换到前面的窗口,我们可以看到阻塞解除了,返回了新的消息内容
# 而且还显示了一个等待时间,这里我们等待了93s
127.0.0.1:6379> xread block 0 count 1 streams codehole $
1) 1) "codehole"
2) 1) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
(93.11s)
创建消费者示例
127.0.0.1:6379> xgroup create codehole cg1 0-0 # 表示从头开始消费
OK
# $表示从尾部开始消费,只接受新消息,当前Stream消息会全部忽略
127.0.0.1:6379> xgroup create codehole cg2 $
OK
127.0.0.1:6379> xinfo codehole # 获取Stream信息
1) length
2) (integer) 3 # 共3个消息
3) radix-tree-keys
4) (integer) 1
5) radix-tree-nodes
6) (integer) 2
7) groups
8) (integer) 2 # 两个消费组
9) first-entry # 第一个消息
10) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
11) last-entry # 最后一个消息
12) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
127.0.0.1:6379> xinfo groups codehole # 获取Stream的消费组信息
1) 1) name
2) "cg1"
3) consumers
4) (integer) 0 # 该消费组还没有消费者
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
2) 1) name
2) "cg2"
3) consumers # 该消费组还没有消费者
4) (integer) 0
5) pending
6) (integer) 0 # 该消费组没有正在处理的消息
组内消费示例
# >号表示从当前消费组的last_delivered_id后面开始读
# 每当消费者读取一条消息,last_delivered_id变量就会前进
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851486781-0
2) 1) "name"
2) "laoqian"
3) "age"
4) "30"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851493405-0
2) 1) "name"
2) "yurui"
3) "age"
4) "29"
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 2 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527851498956-0
2) 1) "name"
2) "xiaoqian"
3) "age"
4) "1"
2) 1) 1527852774092-0
2) 1) "name"
2) "youming"
3) "age"
4) "60"
# 再继续读取,就没有新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 count 1 streams codehole >
(nil)
# 那就阻塞等待吧
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
# 开启另一个窗口,往里塞消息
127.0.0.1:6379> xadd codehole * name lanying age 61
1527854062442-0
# 回到前一个窗口,发现阻塞解除,收到新消息了
127.0.0.1:6379> xreadgroup GROUP cg1 c1 block 0 count 1 streams codehole >
1) 1) "codehole"
2) 1) 1) 1527854062442-0
2) 1) "name"
2) "lanying"
3) "age"
4) "61"
(36.54s)
127.0.0.1:6379> xinfo groups codehole # 观察消费组信息
1) 1) name
2) "cg1"
3) consumers
4) (integer) 1 # 一个消费者
5) pending
6) (integer) 5 # 共5条正在处理的信息还有没有ack
2) 1) name
2) "cg2"
3) consumers
4) (integer) 0 # 消费组cg2没有任何变化,因为前面我们一直在操纵cg1
5) pending
6) (integer) 0
# 如果同一个消费组有多个消费者,我们可以通过xinfo consumers指令观察每个消费者的状态
127.0.0.1:6379> xinfo consumers codehole cg1 # 目前还有1个消费者
1) 1) name
2) "c1"
3) pending
4) (integer) 5 # 共5条待处理消息
5) idle
6) (integer) 418715 # 空闲了多长时间ms没有读取消息了
# 接下来我们ack一条消息
127.0.0.1:6379> xack codehole cg1 1527851486781-0
(integer) 1
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 4 # 变成了5条
5) idle
6) (integer) 668504
# 下面ack所有消息
127.0.0.1:6379> xack codehole cg1 1527851493405-0 1527851498956-0 1527852774092-0 1527854062442-0
(integer) 4
127.0.0.1:6379> xinfo consumers codehole cg1
1) 1) name
2) "c1"
3) pending
4) (integer) 0 # pel空了
5) idle
6) (integer) 745505
常见问题
Stream 消息太多怎么办? | Stream 的上限
定长 Stream 功能。在 xadd 的指令提供一个定长长度 maxlen,就可以将老的消息干掉,确保最多不超过指定长度,
PEL 是如何避免消息丢失的?
在客户端消费者读取 Stream 消息时,Redis 服务器将消息回复给客户端的过程中,客户端突然断开了连接,消息就丢失了。但是 PEL 里已经保存了发出去的消息 ID,待客户端重新连上之后,可以再次收到 PEL 中的消息 ID 列表。不过此时 xreadgroup 的起始消息 ID 不能为参数 > ,而必须是任意有效的消息 ID,一般将参数设为 0-0,表示读取所有的 PEL 消息以及自 last_delivered_id 之后的新消息。
Redis Stream Vs Kafka
Redis 基于内存存储,这意味着它会比基于磁盘的 Kafka 快上一些,也意味着使用 Redis 我们 不能长时间存储大量数据。不过如果您想以 最小延迟 实时处理消息的话,您可以考虑 Redis,但是如果 消息很大并且应该重用数据 的话,则应该首先考虑使用 Kafka。
另外从某些角度来说,Redis Stream 也更适用于小型、廉价的应用程序,因为 Kafka 相对来说更难配置一些。
事务
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(transaction)功能。
> MULTI
OK
> INCR foo
QUEUED
> INCR bar
QUEUED
> EXEC
1) (integer) 1
2) (integer) 1
使用 MULTI命令后可以输入多个命令。Redis不会立即执行这些命令,而是将它们放到队列,当调用了EXEC命令将执行所有命令。
Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。
Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。
Java库
jedis
Lettuce
Redission
Spring Data Redis
Redis 分布式锁
为什么引入分布式锁
我们在系统中修改已有数据时,需要先读取,然后进行修改保存,此时很容易遇到并发问题。由于修改和保存不是原子操作,在并发场景下,部分对数据的操作可能会丢失。在单服务器系统我们常用本地锁来避免并发带来的问题,然而,当服务采用集群方式部署时,本地锁无法在多个服务器之间生效,这时候保证数据的一致性就需要分布式锁来实现。
实现
Redis 锁主要利用 Redis 的 setnx 命令。
加锁命令:SETNX key value,当键不存在时,对键进行设置操作并返回成功,否则返回失败。KEY 是锁的唯一标识,一般按业务来决定命名。
解锁命令:DEL key,通过删除键值对释放锁,以便其他线程可以通过 SETNX 命令来获取锁。
锁超时:EXPIRE key timeout, 设置 key 的超时时间,以保证即使锁没有被显式释放,锁也可以在一定时间后自动释放,避免资源被永远锁住。
加锁解锁伪代码
if (setnx(key, 1) == 1){
expire(key, 30)
try {
//TODO 业务逻辑
} finally {
del(key)
}
}
存在的问题
SETNX 和 EXPIRE 非原子性
如果 SETNX 成功,在设置锁超时时间后,服务器挂掉、重启或网络问题等,导致 EXPIRE 命令没有执行,锁没有设置超时时间变成死锁。
解决这个问题
使用 lua 脚本
if (redis.call('setnx', KEYS[1], ARGV[1]) < 1)
then return 0;
end;
redis.call('expire', KEYS[1], tonumber(ARGV[2]));
return 1;
// 使用实例
EVAL "if (redis.call('setnx',KEYS[1],ARGV[1]) < 1) then return 0; end; redis.call('expire',KEYS[1],tonumber(ARGV[2])); return 1;" 1 key value 100
锁误解除
如果线程 A 成功获取到了锁,并且设置了过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁;随后 A 执行完成,线程 A 使用 DEL 命令来释放锁,但此时线程 B 加的锁还没有执行完成,线程 A 实际释放的线程 B 加的锁。
通过在 value 中设置当前线程加锁的标识,在删除之前验证 key 对应的 value 判断锁是否是当前线程持有。可生成一个 UUID 标识当前线程,使用 lua 脚本做验证标识和解锁操作。
// 加锁
String uuid = UUID.randomUUID().toString().replaceAll("-","");
SET key uuid NX EX 30
// 解锁
if (redis.call('get', KEYS[1]) == ARGV[1])
then return redis.call('del', KEYS[1])
else return 0
end
String uuid = UUID.randomUUID().toString().replaceAll("-","");
SET key uuid NX EX 30
// 解锁
if (redis.call('get', KEYS[1]) == ARGV[1])
then return redis.call('del', KEYS[1])
else return 0
end
超时解锁导致并发
如果线程 A 成功获取锁并设置过期时间 30 秒,但线程 A 执行时间超过了 30 秒,锁过期自动释放,此时线程 B 获取到了锁,线程 A 和线程 B 并发执行。
A、B 两个线程发生并发显然是不被允许的,一般有两种方式解决该问题
将过期时间设置足够长,确保代码逻辑在锁释放之前能够执行完成。
为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间。
不可重入
当线程在持有锁的情况下再次请求加锁,如果一个锁支持一个线程多次加锁,那么这个锁就是可重入的。如果一个不可重入锁被再次加锁,由于该锁已经被持有,再次加锁会失败。
Redis 可通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时释放锁。
本地记录重入次数虽然高效,但如果考虑到过期时间和本地、Redis 一致性的问题,就会增加代码的复杂性。另一种方式是 Redis Map 数据结构来实现分布式锁,既存锁的标识也对重入次数进行计数。
无法等待锁释放
上述命令执行都是立即返回的,如果客户端不可以等待锁释放就无法使用。
解决思路
可以通过客户端轮询的方式解决该问题,当未获取到锁时,等待一段时间重新获取锁,直到成功获取锁或等待超时。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
另一种方式是使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
集群
主备切换
为了保证 Redis 的可用性,一般采用主从方式部署。主从数据同步有异步和同步两种方式,Redis 将指令记录在本地内存 buffer 中,然后异步将 buffer 中的指令同步到从节点,从节点一边执行同步的指令流来达到和主节点一致的状态,一边向主节点反馈同步情况。
在包含主从模式的集群部署方式中,当主节点挂掉时,从节点会取而代之,但客户端无明显感知。当客户端 A 成功加锁,指令还未同步,此时主节点挂掉,从节点提升为主节点,新的主节点没有锁的数据,当客户端 B 加锁时就会成功。
集群脑裂
集群脑裂指因为网络问题,导致 Redis master 节点跟 slave 节点和 sentinel 集群处于不同的网络分区,因为 sentinel 集群无法感知到 master 的存在,所以将 slave 节点提升为 master 节点,此时存在两个不同的 master 节点。Redis Cluster 集群部署方式同理。
当不同的客户端连接不同的 master 节点时,两个客户端可以同时拥有同一把锁。
Redis 以其高性能著称,但使用其实现分布式锁来解决并发仍存在一些困难。Redis 分布式锁只能作为一种缓解并发的手段,如果要完全解决并发问题,仍需要数据库的防并发手段。
zookeeper分布式锁
分布式锁与实现(二)—基于ZooKeeper实现
分布式锁与实现(一) —基于Redis实现
企业部署方案
主从复制模式
工作机制
slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照(即上文所介绍的RDB持久化),并使用缓冲区记录保存快照这段时间内执行的写命令
master将保存的快照文件发送给slave,并继续记录执行的写命令
slave接收到快照文件后,加载快照文件,载入数据
master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化
此后master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性
优缺点
优点
master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点
不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
难以支持在线扩容,Redis的容量受限于单机配置
redis的主从模式搭建及注意事项
Sentinel 模式
基本原理
哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障。
功能
监控master、slave是否正常运行
当master出现故障时,能自动将一个slave转换为master(大哥挂了,选一个小弟上位)
多个哨兵可以监控同一个Redis,哨兵之间也会自动监控
工作机制
在配置文件中通过 sentinel monitor <master-name> <ip> <redis-port> <quorum> 来定位master的IP、端口,一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。
一条连接用来订阅master的_sentinel_:hello频道与获取其他监控该master的哨兵节点信息
定期(一般10s一次,当master被标记为主观下线时,改为1s一次)向master和slave发送INFO命令
定期向master和slave的_sentinel_:hello频道发送自己的信息
定期(1s一次)向master、slave和其他哨兵发送PING命令
另一条连接定期向master发送INFO等命令获取master本身的信息
获取到slave信息后,哨兵也会与slave建立两条连接执行监控。
通过INFO命令,哨兵可以获取主从数据库的最新信息,并进行相应的操作,比如角色变更等。
如果被PING的数据库或者节点超时,哨兵认为其主观下线.进行选举,故障恢复的操作需要由选举的领头哨兵来执行
选举采用Raft算法
发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
如果有超过一半的哨兵同意选举A为领头,则A当选
如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵
选出领头哨兵后,领头者开始对系统进行故障恢复,从出现故障的master的从数据库中挑选一个来当选新的master
所有在线的slave中选择优先级最高的,优先级可以通过slave-priority配置
如果有多个最高优先级的slave,则选取复制偏移量最大(即复制越完整)的当选
如果以上条件都一样,选取id最小的slave
优缺点
优点
哨兵模式基于主从复制模式,所以主从复制模式有的优点,哨兵模式也有
哨兵模式下,master挂掉可以自动进行切换,系统可用性更高
缺点
样也继承了主从模式难以在线扩容的缺点,Redis的容量受限于单机配置
需要额外的资源来启动sentinel进程,实现相对复杂一点,同时slave节点作为备份节点不提供服务
Cluster 模式
Cluster模式实现了Redis的分布式存储,即每台节点存储不同的内容,来解决在线扩容的问题。
无中心结构
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
节点的fail是通过集群中超过半数的节点检测失效时才生效
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
工作机制
在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
优缺点
优点
无中心架构,数据按照slot分布在多个节点。
集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
可线性扩展到1000多个节点,节点可动态添加或删除
能够实现自动故障转移,节点之间通过gossip协议交换状态信息,用投票机制完成slave到master的角色转换
缺点
客户端实现复杂,驱动要求实现Smart Client,缓存slots mapping信息并及时更新,提高了开发难度。目前仅JedisCluster相对成熟,异常处理还不完善,比如常见的“max redirect exception”
节点会因为某些原因发生阻塞(阻塞时间大于 cluster-node-timeout)被判断下线,这种failover是没有必要的
数据通过异步复制,不保证数据的强一致性
slave充当“冷备”,不能缓解读压力
批量操作限制,目前只支持具有相同slot值的key执行批量操作,对mset、mget、sunion等操作支持不友好
key事务操作支持有线,只支持多key在同一节点的事务操作,多key分布不同节点时无法使用事务功能
不支持多数据库空间,单机redis可以支持16个db,集群模式下只能使用一个,即db 0
其他
基于客户端分片
Twemproxy
Codis
总结
常见问题
简单介绍一下 Redis 呗!
简单来说 Redis 就是一个使用 C 语言开发的数据库,不过与传统数据库不同的是 Redis 的数据是存在内存中的 ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
另外,Redis 除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列。
Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。
分布式缓存常见的技术选型方案有哪些?
分布式缓存的话,使用的比较多的主要是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
说一下 Redis 和 Memcached 的区别和共同点
共同点
都是基于内存的数据库,一般都用来当做缓存使用。
都有过期策略。
两者的性能都非常高。
区别
Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。
Redis 有灾难恢复机制。 因为可以把缓存中的数据持久化到磁盘上。
Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。
Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.
Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。 (Redis 6.0 引入了多线程 IO )
Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
Memcached过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
为什么要用 Redis/为什么要用缓存?
操作缓存就是直接操作内存,所以速度相当快。
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
Redis 单线程模型
Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型
这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
Redis 通过IO 多路复用程序 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗(和 NIO 中的 Selector 组件很像)。
Redis 没有使用多线程?为什么不使用多线程?
虽然说 Redis 是单线程模型,但是, 实际上,Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。
Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
为什么不使用多线程
单线程编程容易并且更容易维护;
Redis 的性能瓶颈不再 CPU ,主要在内存和网络;
多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
Redis6.0 之后为何引入了多线程?
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。
Redis6.0 的多线程默认是禁用的,只使用主线程。
io-threads-do-reads yes
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
Redis 给缓存数据设置过期时间有啥用?
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接Out of memory。
比如我们的短信验证码可能只在1分钟内有效,用户登录的 token 可能只在 1 天内有效
Redis是如何判断数据是否过期的呢?
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
过期的数据的删除策略了解么?
惰性删除 :只会在取出key的时候才对数据进行过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除。
定期删除 : 每隔一段时间抽取一批 key 执行删除过期key操作。并且,Redis 底层会并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
扩展
仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就Out of memory了。
怎么解决这个问题呢?答案就是: Redis 内存淘汰机制。
仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就Out of memory了。
怎么解决这个问题呢?答案就是: Redis 内存淘汰机制。
Redis 内存淘汰机制了解么?
volatile-lru(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0 版本后增加
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
4.0 版本后增加
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
Redis 持久化机制
见
数据库 -> NoSql -> Redis -> 持久化
数据库 -> NoSql -> Redis -> 持久化
redis的工作原理
redis的并发量是多少
跟计算机性能有关10万
redis的线程模型是什么
redis 实际上是个单线程工作模型
redis的数据类型有哪些
Redis五种数据类型及应用场景
五种数据类型
string
hash
list
set
zset
redis的过期策略
redis的过期策略详解
设置过期时间
expire key time(以秒为单位)--这是最常用的方式
setex(String key, int seconds, String value)--字符串独有的方式
三种过期策略
定时删除
惰性删除
惰性删除为redis服务器内置策略
定期删除
第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
redis使用的过期策略:惰性删除+定期删除
为什么redis是单线程的但是还可以支撑高并发
文件事件处理器是单线程的
多个 socket
IO 多路复用程序
文件事件分派器
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
为啥 redis 单线程模型也能效率这么高
1.纯内存操作
2.核心是基于非阻塞的 IO 多路复用机制
3.单线程反而避免了多线程的频繁上下文切换问题
怎么保证redis是高并发以及高可用的
redis 实现高并发主要依靠主从架构,一主多从
高并发的同时,容纳大量的数据,需要redis集群
redis 高可用,如果是做主从架构部署,那么加上哨兵就可以了
怎么保证redis挂掉之后再重启数据可以进行恢复
Redis数据备份和重启恢复
聊聊redis cluster集群模式的原理
一般如何应对缓存雪崩以及穿透问题吗
解决缓存雪崩的方案
事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
事后:redis持久化,快速恢复缓存数据
缓存穿透现象以及解决方案
每次系统A从数据库只要没有查到,就写一个空值到缓存里去
如何保证缓存与数据库双写时的数据一致性
redis的并发竞争问题该如何解决
什么是Redis的并发竞争问题
生产环境的redis集群的部署架构是什么样的
使用分布式缓存的时候存在问题
常见分布式缓存问题
redis应用
分布式系统的问题
分布式系统常见的几个问题和解决办法
分布式session问题
分布式跨域问题
分步式事务
分布式任务调度
分布式锁
分布式幂等性
分布式缓存
更新数据时,是先删除缓存再更新DB,还是先更新DB再删除缓存?
redis高性能数据库
完善_Redis高性能缓存数据库
redis高速缓存系统
本地缓存Ehcache
计算机缓存的分类
java中常用的几种缓存类型
客户端缓存
页面缓存
浏览器缓存
App客户端缓存
网络缓存
代理缓存
CDN缓存
服务器缓存
数据库缓存
平台缓存级缓存
Ehcache缓存过期策略
FIFO:First In First Out,先进先出。
LRU:Least Recently Used,最近最少使用
LFU:Least Frequently Used,最不经常使用
Ehcache缓存使用
springboot整合Ehcache网络教程
SpringBoot2.0整合Ehcache缓存技术
代码
@Cacheable(value = "myToken")
@CacheEvict(value = "myToken", allEntries = true)
Ehcache与redis整合
Ehcache与redis整合网络教程
Spring+ehcache+redis两级缓存--缓存实战篇(1)
spring整合redis缓存
文档教程
深度解析SpringBoot2.x整合Spring-Data-Redis
源码
SpringBoot整合Redis,RedisTemplate和注解两种方式的使用
spring + redis + spring-data-redis2.0.10 整合-单机版
spring + redis + spring-data-redis2.0.10 整合-redis Cluster版
springboot之使用redistemplate优雅地操作redis
缓存与DB存在不同步
更新DB缓存网络教程
更新数据时,是先删除缓存再更新DB,还是先更新DB再删除缓存?
出现不同步的情况
如果删了缓存,还没有来得及写库,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据
如果先写了库,再删除缓存前,写库后没有删除掉缓存,则也会出现数据不一致情况
如果是redis集群,或者主从模式,写主读从,由于redis复制存在一定的时间延迟,也有可能导致数据不一致
缓存与DB不同步解决
缓存与DB不同步解决网络教程
采用延时双删策略(双淘汰策略)
设置缓存过期时间
异步更新缓存(基于订阅binlog的同步机制)
redis缓存引发问题
缓存击穿、穿透、雪崩
REDIS 缓存的穿透,雪崩和热点key
Redis缓存雪崩、缓存穿透、热点Key解决方案和分析
缓存穿透、缓存击穿、缓存雪崩区别和解决方案
缓存三大问题及解决方案
缓存击穿
缓存穿透
缓存雪崩
redis分布式session
服务器session作用
Session 是客户端与服务器通讯会话技术, 比如浏览器登陆、记录整个浏览会话信息
分布式session不一致
session是存放在服务器上,客户端会使用同一个Sessionid在多个不同的服务器上获取对应的Session,从而会导致Session不一致问题
分布式Session一致性解决方案
用Nginx 做的负载均衡可以添加ip_hash这个配置
使同一个ip的请求发到同一台服务器
没有负载均衡
用haproxy做的负载均衡可以用 balance source这个配置
使同一个ip的请求发到同一台服务器
使用Session集群令牌存放Redis
基于令牌(Token)方式实现Session解决方案,因为Session本身就是分布式共享连接
分布式session之token解决方案实现
spring-session-data-redis框架整合
把session值缓存到redis中
spring-session-data-redis框架步骤教程
SpringBoot+SpringSession+Redis分布式Session解决方案
springboot2.1入门系列四 Spring Session实现session共享
redis分布式线程锁
出现分布式锁的原因
解决同一业务数据并发处理方案
spring redis锁实例
Spring-data-redis + redis 分布式锁(一)
Spring-data-redis + redis 分布式锁(二)
代码
redis系列:基于redis的分布式锁
代码
大牛技术系列教程
zookeeper基本操作
zookeeper网络教程
Docker安装Zookeeper并进行操作
zookeeper应用场景
注册中心
配置中心
消息中间件
分布式事务
分布式锁
选举策略
负载均衡
zookeeper分布式锁
分布式锁与实现(二)—基于ZooKeeper实现
分布式锁与实现(一) —基于Redis实现
redis令牌桶限流器
Java并发:分布式应用限流 Redis + Lua 实践
接口限流算法:漏桶算法&令牌桶算法
redis防止重复提交
【Redis使用系列】使用Redis做防止重复提交
redis的网站计数器
redis列表消息队列
redis整合主要框架
shiro整合redis使用
springboot+shiro+redis项目整合
源码
文档教程
springboot+shiro+redis项目整合
源码
Mongodb
Neo4j
Hbase
MemcacheDB
........
时序数据库
InfluxDB
Druid
ElasticSearch
Prometheus
········
缓存
为什么引入缓存
空间换时间
CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。 再比如操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把块表理解为一种特殊的高速缓冲存储器(Cache)。
我们为了避免用户在请求数据的时候获取速度过于缓慢,所以我们在数据库之上增加了缓存这一层来弥补。
缓存带来的问题
系统复杂性增加 :引入缓存之后,你要维护缓存和数据库的数据一致性、维护热点缓存等等。
系统开发成本往往会增加 :引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。但是,如果你只是简单的使用一下本地缓存存储一下简单的数据,并且数据量不大的话,那么就不需要单独去弄一个缓存服务。
本地缓存
HashMap 和 ConcurrentHashMap
Ehcache 、 Guava Cache 、 Spring Cache、Caffeine
分布式缓存
本地缓存容量受服务部署所在的机器限制明显。 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
本地缓存对分布式架构支持不友好,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
缓存读写模式/更新策略
Cache Aside Pattern(旁路缓存模式)
写:更新 DB,然后直接删除 cache 。
读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中。
Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。
读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中。
Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案
缓存失效时间变短(不推荐,治标不治本) :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
增加cache更新重试机制(常用): 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
Read/Write Through Pattern(读写穿透)
Read/Write Through 套路是:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
写(Write Through):先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache 和 DB)。
读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
写(Write Through):先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache 和 DB)。
读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
Write Behind Pattern(异步缓存写入)
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。
Write Behind Pattern 下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。
Write Behind Pattern 下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了。
缓存穿透
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
解决办法
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
缓存无效 key
布隆过滤器
缓存雪崩
缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。
解决办法
针对 Redis 服务不可用的情况
采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
限流,避免同时处理大量的请求。
针对热点缓存失效的情况
设置不同的失效时间比如随机设置缓存的失效时间。
缓存永不失效。
如何保证缓存和数据库数据的一致性
见
数据库 -> 缓存 -> 缓存读写模式(更新策略)
数据库 -> 缓存 -> 缓存读写模式(更新策略)
网络
HTTP
简介
HTTP协议就是客户端和服务器交互的一种通迅的格式
告知服务器意图
HTTP提供了好几种方法给我们使用
GET
PUT
HEAD
DELETE
POST
OPTIONS
总的来说:我们现在盛行的RESTful风格就是充分利用了这些方法
持久连接
在HTTP1.0的时候,每一次进行HTTP通信就会断开一次连接
在HTTP1.1版本,就是持久连接了。一次HTTP连接能够处理多个请求
持久连接为“管线化”方式发送成为了可能:在一次HTTP连接里面,不需要等待服务器响应请求,就能够继续发送第二次请求
常用状态码
2XX--一般表示为成功处理
200 正常处理
204 成功处理,但服务器没有新数据返回,显示页面不更新
206 对服务器进行范围请求,只返回一部分数据
更多脑图和最新原创技术文章可关注公众号:Java3y
3XX--一般表示为重定向
301 请求的资源已分配了新的URI中,URL地址改变了。【永久重定向】
302 请求的资源临时分配了新的URI中,URL地址没变【转发】
303 与302相同的功能,但明确客户端应该采用GET方式来获取资源
304 发送了附带请求,但不符合条件【返回未过期的缓存数据】
307 与302相同,但不会把POST请求变成GET
4XX--客户端出错
400 请求报文语法错误了
401 需要认证身份
403 没有权限访问
404 服务器没有这个资源
更多脑图和最新原创技术文章可关注公众号:Java3y
5XX--服务器出错
500 内部资源出错了
503 服务器正忙
HTTPS简述
HTTPS就是披着SSL的HTTP
HTTP在建立通信线路的时候使用公开私有密钥,当建立完连接后,随后就使用共享密钥进行加密和解密了
HTTPS是基于第三方的认证机构来获取认受认可的证书
过程
用户向web服务器发起一个安全连接的请求
服务器返回经过CA认证的数字证书,证书里面包含了服务器的public key(公钥)
用户拿到数字证书,用自己浏览器内置的CA证书解密得到服务器的public key
用户用服务器的public key加密一个用于接下来的对称加密算法的密钥,传给web服务器
4.1因为只有服务器有private key可以解密,所以不用担心中间人拦截这个加密的密钥
服务器拿到这个加密的密钥,解密获取密钥,再使用对称加密算法,和用户完成接下来的网络通信
网站通信粗略过程
DNS:负责解析域名
HTTP:产生请求报文数据
TCP协议:分割HTTP数据,保证数据运输
IP协议:传输数据包,找到通信目的地地址。
HTTP是不保存状态的协议
HTTP是无状态的,也就是说,它是不对通信状态进行保存的。它并不知道之前通信的对方是谁
由于我们很多时候都是需要知道对方是谁,于是我们就有了Cookie来解决
提升传输效率
使用压缩技术把实体主体压小,在客户端再把数据解析
使用分块传输编码,将实体主体分块传输,当浏览器解析到实体主体就能够显示了。
这种技术可以实现断点续传
服务器与客户端之间的应用程序
代理
网关
能够提供非HTTP请求的操作,访问数据库什么的
隧道
建立一条安全的通信路径,可以使用SSL等加密手段进行通信。
HTTP请求和响应报文组成
请求报文
a、请求行:包含请求方法、URI、HTTP版本信息
b、请求首部字段
c、请求内容实体
d、空行
响应报文
A:一个状态行【用于描述服务器对请求的处理结果。】
B:首部字段【用于描述服务器的基本信息,以及数据的描述,服务器通过这些数据的描述信息,可以通知客户端如何处理等一会儿它回送的数据】
C:一个空行
D:实体内容【服务器向客户端回送的数据】
HTTP1.1版本新特性
a、默认持久连接节省通信量,只要客户端服务端任意一端没有明确提出断开TCP连接,就一直保持连接,可以发送多次HTTP请求
b、管线化,客户端可以同时发出多个HTTP请求,而不用一个个等待响应(理论->未实践)
c、断点续传:实际上就是利用HTTP消息头使用分块传输编码,将实体主体分块传输。
HTTP2
HTTP2与HTTP1.1最重要的区别就是解决了线头阻塞的问题!其中最重要的改动是:多路复用 (Multiplexing)
HTTP2所有性能增强的核心在于新的二进制分帧层(不再以文本格式来传输了)
其他重要改动
使用HPACK对HTTP/2头部压缩
服务器推送
流量控制(针对传输中的流进行控制(TCP默认的粒度是针对连接))
流优先级(Stream Priority)它被用来告诉对端哪个流更重要。
OSI七层模型
OSI(Open System Interconnection)参考模型是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。
只要遵循这个七层协议就可以实现计算机互联
OSI七层模型及各层作用
物理层
定义物理设备标准
所有与网络有关的
数据链路层
STP
网卡,交换机
将物理层接收的数据进行MAC(媒体访问控制)地址的封装和解封装,也可以简单的理解为物理寻址
网络层
ip
控制子网的运行,如逻辑编址,分组传输,路由
传输层
定义一些传输数据的协议和端口。
TCP
UDP
会话层
负责在网络中的两节点建立,维持和终止通信
SMTP, DNS
表示层
确保一个系统的应用层发送的消息可以被另一个系统的应用层读取
Telnet
应用层
文件传输,文件管理,电子邮件的信息处理
HTTP、TFTP, FTP, NFS, WAIS、SMTP
TCP/IP协议
TCP 和 UDP
TCP 是面向连接的、可靠的流协议,通过三次握手建立连接,通讯完成时要拆除连接。
UDP是面向无连接的通讯协议,UDP通讯时不需要接收方确认,属于不可靠的传输,可能会出现丢包现象。
三次握手和四次挥手
通俗易懂地讲解TCP建立连接的三次握手和释放连接的四次挥手
理解TCP/IP三次握手与四次挥手的正确姿势
名词解释
ACK : TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1
SYN(SYNchronization) : 在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN (finis)即完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
三次握手
第一次握手:客户端将标志位SYN置为1,随机产生一个值seq=J,并将该数据包发送给服务器端,客户端进入SYN_SENT状态,等待服务器端确认。
第二次握手:服务器端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务器端将标志位SYN和ACK都置为1,ack=J+1,随机产生一个值seq=K,
并将该数据包发送给客户端以确认连接请求,服务器端进入SYN_RCVD状态。
第三次握手:客户端收到确认后,检查ack是否为J+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=K+1,并将该数据包发送给服务器端,服务器端检查ack是否为K+1,ACK是否为1,如果正确则连接建立成功,客户端和服务器端进入ESTABLISHED状态,完成三次握手,随后客户端与服务器端之间可以开始传输数据了。
四次挥手
第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
TCP/IP中的数据包
TCP 中通过序列号与确认应答提高可靠性
网络编程常见术语
网络编程基础(网络基本知识)
Socket套接字
Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面
主机 A 的应用程序要能和主机 B 的应用程序通信,必须通过 Socket 建立连接,而建立 Socket 连接必须需要底层TCP/IP 协议来建立 TCP 连接。
建立 TCP 连接需要底层 IP 协议来寻址网络中的主机。
短连接
连接->传输数据->关闭连接
HTTP是无状态的,浏览器和服务器每进行一次HTTP操作,就建立一次连接,但任务结束就中断连接
短连接是指SOCKET连接后发送后接收完数据后马上断开连接
使用场景
WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源
长连接
连接->传输数据->保持连接 -> 传输数据-> 。。。 ->关闭连接
长连接指建立SOCKET连接后不管是否使用都保持连接,但安全性较差。
使用场景
数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费
运维
Linux
awk
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BAWK/
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BAWK/
grep
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BGREP/
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BGREP/
sed
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BSED/
https://blog.viakiba.cn/2020/07/17/Linux%E5%91%BD%E4%BB%A4%E4%B9%8BSED/
screen
lsof
rsync
scp
..........
详细汇总
网络管理
网络接口相关
ifconfig:查看网络接口信息
ifup/ifdown:开启或关闭接口
临时配置相关
route命令:可以临时地设置内核路由表
hostname命令:可以临时地修改主机名
sysctl命令:可以临时地开启内核的包转发
ifconfig命令:可以临时地设置网络接口的IP参数
网络检测的常用工具:
ifconfig 检测网络接口配置
route 检测路由配置
ping 检测网络连通性
netstat 查看网络状态
lsof 查看指定IP 和/或 端口的进程的当前运行情况
host/dig/nslookup 检测DNS解析
traceroute 检测到目的主机所经过的路由器
tcpdump 显示本机网络流量的状态
安装软件
yum
rpm
wget
管理用户
用户管理
useradd
添加用户
usermod
修改用户
userdel
删除用户
组管理
groupadd
添加组
groupmod
修改组
groupdel
删除组
批量管理用户:
成批添加/更新一组账户:newusers
成批更新用户的口令:chpasswd
组成员管理:
向标准组中添加用户
gpasswd -a <用户账号名> <组账号名>
usermod -G <组账号名> <用户账号名>
从标准组中删除用户
gpasswd -d <用户账号名> <组账号名>
口令管理
口令时效设置:
修改 /etc/login.defs 的相关配置参数
口令维护(禁用、恢复和删除用户口令):
passwd
设置已存在用户的口令时效:
change
切换用户
su
sudo
用户相关的命令:
id:显示用户当前的uid、gid和用户所属的组列表
groups:显示指定用户所属的组列表
whoami:显示当前用户的名称
w/who:显示登录用户及相关信息
newgrp:用于转换用户的当前组到指定的组账号,用户必须属于该组才可以正确执行该命令
查看文件
cat
查看文本文件内容
more
可以分页看
less
不仅可以分页,还可以方便地搜索,回翻等操作
tail -10
查看文件的尾部的10行
head -20
查看文件的头部20行
文件和目录的操作
ls
显示文件和目录列表
cd
切换目录
pwd
显示当前工作目录
mkdir
创建目录
rmdir
删除空目录
touch
生成一个空文件或更改文件的时间
cp
复制文件或目录
mv
移动文件或目录、文件或目录改名
rm
删除文件或目录
ln
建立链接文件
find
查找文件
file/stat
查看文件类型或文件属性信息
echo
把内容重定向到指定的文件中 ,有则打开,无则创建
管道命令 |
将前面的结果给后面的命令,例如:`ls -la | wc `,将ls的结果加油wc命令来统计字数
重定向 > 是覆盖模式,>> 是追加模式
例如:`echo "Java3y,zhen de hen xihuan ni" > qingshu.txt `把左边的输出放到右边的文件里去
进程管理
ps:查找出进程的信息
nice和renice:调整进程的优先级
kill:杀死进程
free:查看内存使用状况
top :查看实时刷新的系统进程信息
作业管理
jobs:列举作业号码和名称
bg: 在后台恢复运行
fg:在前台恢复运行
ctrl+z:暂时停止某个进程
自动化任务
at
cron
管理守护进程
chkconfig
service
ntsysv
打包和压缩文件
压缩
gzip filename
bzip2 filename
tar -czvf filename
解压
gzip -d filename.gz
bzip2 -d filename.bz2
tar -xzvf filename.tar.gz
grep+正则表达式
grep -n mystr myfile
在文件 myfile 中查找包含字符串 mystr的行
grep '^[a-zA-Z]' myfile
显示 myfile 中第一个字符为字母的所有行
Vi编辑器
普通模式
G 用于直接跳转到文件尾
ZZ 用于存盘退出Vi
ZQ 用于不存盘退出Vi
/和? 用于查找字符串
n 继续查找下一个
yy 复制一行
p 粘帖在下一行,P粘贴在前一行
dd 删除一行文本
u 取消上一次编辑操作(undo)
插入模式
使用i或a或o进去插入模式
使用esc返回普通模式
命令行模式
w 保存当前编辑文件,但并不退出
w newfile 存为另外一个名为 “newfile” 的文件
wq 用于存盘退出Vi
q! 用于不存盘退出Vi
q 用于直接退出Vi (未做修改)
设置Vi环境
set autoindent 缩进,常用于程序的编写
set noautoindent 取消缩进
set number 在编辑文件时显示行号
set tabstop=value 设置显示制表符的空格字符个数
set 显示设置的所有选项
vim常用命令总结
权限管理
改变文件或目录的权限:chmod
改变文件或目录的属主(所有者):chown
改变文件或目录所属的组:chgrp
设置文件的缺省生成掩码:umask
文件扩展属性
显示扩展属性:lsattr [-adR] [文件|目录]
修改扩展属性:chattr [-R] [[-+=][属性]] <文件|目录>
修改扩展属性:chattr [-R] [[-+=][属性]] <文件|目录>
查看linux环境
查看linux内核版本
查看GCC版本gcc -v
查看glibc版本ldd --version
查看发行版信息cat /etc/redhat-release
Linux命令速查
Linux命令大全
Linux关闭开启防火墙
Nginx
代理
负载均衡
Https配置
正反向代理的区别
什么是正向代理
正向代理类似一个跳板机,代理访问外部资源
举例说明
客户端必须设置正向代理服务器,当然前提是要知道正向代理服务器的IP地址,还有代理程序的端口。
正向代理总结
正向代理 是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器)
然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
正向代理的用途
(1)访问原来无法访问的资源,如google
(2) 可以做缓存,加速访问资源
(3)对客户端访问授权,上网进行认证
(4)代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
什么是反向代理
反向代理总结
初次接触方向代理的感觉是,客户端是无感知代理的存在的,反向代理对外都是透明的,
访问者者并不知道自己访问的是一个代理。因为客户端不需要任何配置就可以访问。
反向代理过程
反向代理(Reverse Proxy)实际运行方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器
从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
反向代理作用
(1)保证内网的安全,可以使用反向代理提供WAF功能,阻止web攻击
(2)负载均衡,通过反向代理服务器来优化网站的负载
nginx安装与命令
常用服务器介绍
Nginx教程(7) 正向代理与反向代理【总结】
nginx安装及常见问题
无法访问nginx,要关闭防火墙
目录结构
Conf
配置文件
Html
网页文件
Logs
日志文件
Sbin
二进制程序
常用命令
nginx开启关闭和状态
linux nginx启动重启关闭命令
ps aux|grep nginx 和ps -ef|grep nginx一样
关闭nginx (./sbin/nginx -s stop)
启动停止命令
./nginx -c nginx.conf
如果不指定,默认为NGINX_HOME/conf/nginx.conf
./nginx -s stop
停止
./nginx -s quit
退出
./nginx -s reload
重新加载nginx.conf
发送信号的方式
kill -QUIT 进程号
安全停止
kill -TERM 进程号
立即停止
windows下的nginx
使用nginx+tomcat实现集群
Windows下Nginx的启动、停止等命令
window版nginx部署实践
安装java的环境
卸载与安装jdk1.8
安装mysql数据库
安装tomcat服务器
nginx的安装与配置
Nginx Linux详细安装部署教程
编译安装nginx 1.8.1 及配置
nginx进程的模型
模型及基本概念
发送信号方式
nginx的信号量
nginx的配置结构
conf配置文件结构
配置文件图结构
配置文件结构
配置文件教程
main全局配置
#user nobody
#主模块命令, 指定Nginx的worker进程运行用户以及用户组,默认由nobody账号运行
worker_processes 1;
指定Nginx要开启的进程数。
#error_log logs/error.log;
#错误日志存放目录
#pid
logs/nginx.pid;
worker_rlimit_nofile 100000;
worker进程的最大打开文件数限制
worker_cpu_affinity 0001 0010 0100 1000 0001 00100100 1000;
cpu亲和力配置,让不同的进程使用不同的cpu
event配置
设定nginx的工作模式及连接数上限
use epoll;
use用来指定nginx的工作模式
worker_connections 1024;
设置nginx每个进程最大的连接数,默认是1024
http服务器
include mime.types;
文件扩展名与文件类型映射表
default_type application/octet-stream;
默认文件类型,当文件类型未定义时候就使用这类设置的。
log_format access '$remote_addr - $remote_user [$time_local] "$request" '
设置日志模式
设定请求缓存
server_names_hash_bucket_size 128;client_header_buffer_size 512k;large_client_header_buffers 4 512k;client_max_body_size 100m;
server_tokens off;
隐藏响应header和错误通知中的版本号
tcp_nopush on;
激活tcp_nopush参数可以允许把httpresponse header和文件的开始放在一个文件里发布,积极的作用是减少网络报文段的数量
tcp_nodelay on;
激活tcp_nodelay,内核会等待将更多的字节组成一个数据包,从而提高I/O性能
sendfile on
开启高效传输模式
keepalive_timeout 65;
长连接超时时间,单位是秒
upstream backend_server {server 10.254.244.20:81 weight=1 max_fails=2 fail_timeout=30s;}
upstream表示负载服务器池,定义名字为backend_server的服务器池
轮询
upstream webhost {server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;}
权重
upstream webhost {server 192.168.0.5:6666 weight=2;server 192.168.0.7:6666 weight=3;}
ip_hash
upstream webhost {ip_hash;server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;}
每个请求按访问IP的hash结果分配,这样来自同一个IP的访客固定访问一个后端服务器,有效解决了动态网页存在的session共享问题
url_hash
upstream webhost {server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;hash $request_uri;}
此方法按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率
server虚拟主机
设置一个虚拟机主机,可以包含自己的全局快,同时也可以包含多个locating模块。
listen 80;
server的全局配置,配置监听的端口
server_name localhost;
本server的名称,当访问此名称的时候nginx会调用当前serevr内部的配置进程匹配。
index index.html index.htm index.php;
首页排序
root /data0/abc;
#站点根目录,即网站程序存放目录
error_page 500 502 404 /templates/kumi/phpcms/404.html;
错误页面
rewrite ^/list-([0-9]+)-([0-9]+)\.html$ /index.php?m=content
伪静态 将www.abc.com/list....html的文件转发到index.php。。。
access_log /var/log/nginx/access.log access;
定义本虚拟主机的访问日志
location ~ /.svn/ { deny all;}
location 标签,根目录下的.svn目录禁止访问
location /
location其实是server的一个指令,为nginx服务器提供比较多而且灵活的指令,都是在location中提现的
root html;
相当于默认页面的目录名称,默认是相对路径,可以使用绝对路径配置。
index index.html index.htm;
error_page 500 502 503 504 /50x.html;
#错误页面的文件名称
location = /50x.html
location处理对应的不同错误码的页面定义到/50x.html,这个跟对应其server中定义的目录下。
root html;
定义默认页面所在的目录
location配置语法
location的作用
根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作
location的正则
正则表达式实例教程
nginx location 配置 正则表达式实例详解
“=”精确匹配,内容要同表达式完全一致才匹配成功
“~”大小写敏感
“~*”大小写忽略
“^~”只匹配以 uri 开头
“@”nginx内部跳转
不加任何规则
默认是大小写敏感,前缀匹配,相当于加了“~”与“^~”
匹配优先级
Location解析过程
if指令
return指令
内置变量
日志的配置及切割
Nginx日志格式
Nginx日志分隔
crontab设置作业
反向代理负载均衡
反向代理
DNS域名解析过程
DNS将域名解析为真实ip地址和端口号
查找浏览器DNS缓存
查找本地host文件(ip与域名的关系)
访问nginx服务器地址
从网络运营商获取对应的IP地址
反向代理的好处
反向代理的好处隐藏真实内部ip地址,请求先访问nginx代理服务器(外网可以访问到),在使用nginx服务器转发到真实服务器中
反向代理的配置
当客户端访问www.itmayiedu.com,监听端口号为80直接跳转到真实ip服务器地址 127.0.0.1:8081
外网映射工具
外网映射的作用
在做微信开发或者是对接第三方支付接口时,回调接口可能需要外网访问。
外网映射的工具
natapp、ngrok
反向代理架构
蚂蚁课堂架构.png
公网服务器
局域网服务器
反向代理跳转地址
抓包分析反向代理跳转地址
基础用法
负载均衡
负载均衡的作用
解决高并发,减少单台服务器的压力,拦截到请求,在采用负载均衡算法后,分配到不同的真实服务器上
服务器故障转移
负载均衡、故障转移、失败重试、容错、健康检查
当上游服务器(真实业务逻辑访问的服务器)发生故障时,可以转移到其他上游服务器
服务集群的问题
负载均衡的配置
upstream和location配置
负载均衡的方式
upstream表示负载服务器池,定义名字为backend_server的服务器池
url_hash
upstream webhost {server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;hash $request_uri;}
此方法按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率
ip_hash
upstream webhost {ip_hash;server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;}
每个请求按访问IP的hash结果分配,这样来自同一个IP的访客固定访问一个后端服务器,有效解决了动态网页存在的session共享问题
权重
upstream webhost {server 192.168.0.5:6666 weight=2;server 192.168.0.7:6666 weight=3;}
轮询
upstream webhost {server 192.168.0.5:6666 ;server 192.168.0.7:6666 ;}
负载均衡故障转移
当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用
负载均衡的故障转移配置
proxy_connect_timeout 1s;
nginx与后端服务器连接的超时时间_发起握手等候响应超时时间
proxy_send_timeout 1s;
nginx发送给上游服务器(真实访问的服务器)超时时间
proxy_read_timeout 1s;
nginx接受上游服务器(真实访问的服务器)超时时间
静态网页的服务器
Nginx是一个HTTP服务器,可以将服务器上的静态文件(如HTML、图片)通过HTTP协议展现给客户端
URL的重写与配置
使用正则匹配请求的url,根据定义的规则进行重写和改变,需ngx_http_rewrite_module模块来支持url重写功能
可重写的功能
可重写变量和含义
重写的语法
判断IP地址来源
如果访问的ip地址为192.168.5.165,则返回403
限制浏览器访问
不允许谷歌浏览器访问 如果是谷歌浏览器返回500
URL重写场景
rewrite语法格式
regex 常用正则表达式
rewrite过程
nginx的动静分离
动静分离教程
【Nginx】实现动静分离
mvvm模式的交互
动静分离的两种方式
伪静态
动静分离实例
虚拟主机配置应用
nginx虚拟主机作用
将一台服务器,拆封多个网站部署
nginx虚拟主机配置
nginx 配置虚拟主机的三种方法
基于域名的虚拟主机
#当客户端访问www.itmayiedu.com,监听端口号为80,直接跳转到data/www目录下文件
#当客户端访问bbs.itmayiedu.com,监听端口号为80,直接跳转到data/bbs目录下文件
基于端口的虚拟主机
#当客户端访问www.itmayiedu.com,监听端口号为8080,直接跳转到data/www目录下文件
#当客户端访问www.itmayiedu.com,监听端口号为8081,直接跳转到data/bbs目录下文件
跨域问题网关配置
跨域的由来
跨域属于浏览器的问题,不是服务器的问题
跨域的解决方案
1.使用jsonp解决网站跨域
不支持post请求,代码书写比较复杂
2.使用HttpClient内部转发
前端Q向后端B发送请求,Q先请求后端A,后端A请求后端B,获取数据后响应前端Q
3.使用设置响应头允许跨域
response.setHeader("Access-Control-Allow-Origin", "*")
4.基于Nginx搭建企业级API接口网关
原理:保证域名和端口号是相同的,根据不同项目名称使用nginx转发到真实服务器地址
5.使用Zuul搭建微服务API接口网关
cors方案用法
简单请求与复杂请求
缓存及Gzip的配置
nginx的缓存配置教程
Nginx缓存原理及配置
静态资源缓存配置
资源压缩配置
nginx的https配置
https配置加强信息传输安全
nginx使用ssl模块配置支持HTTPS访问
信息传输安全概念
HTTPS简介
openssl生成证书
Nginx.conf配置证书
keepalived的配置
nginx高可用概述
安装Keepalived
配置抢占式模式
Docker
Docker简介
前提知识+课程定位
是什么
问题:为什么会有docker出现
docker理念
一句话
解决了运行环境和配置问题软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术。
能干嘛
之前的虚拟机技术
容器虚拟化技术
开发/运维(DevOps)
一次构建、随处运行
更快速的应用交付和部署
更便捷的升级和扩缩容
更简单的系统运维
更高效的计算资源利用
企业级
新浪
美团
蘑菇街
......
去哪下
官网
docker官网:http://www.docker.com
docker中文网站:https://www.docker-cn.com/
仓库
Docker Hub官网: https://hub.docker.com/
Docker安装
前提说明
Docker的基本组成
镜像(image)
容器(container)
仓库(repository)
小总结
安装步骤
CentOS6.8安装Docker
yum install -y epel-release
yum install -y docker-io
安装后的配置文件:/etc/sysconfig/docker
启动Docker后台服务:service docker start
docker version验证
CentOS7安装Docker
https://docs.docker.com/install/linux/docker-ce/centos/
安装步骤
官网中文安装参考手册
https://docs.docker-cn.com/engine/installation/linux/docker-ce/centos/#prerequisites
确定你是CentOS7及以上版本
cat /etc/redhat-release
yum安装gcc相关
CentOS7能上外网
分支主题
yum -y install gcc
yum -y install gcc-c++
卸载旧版本
yum -y remove docker docker-common docker-selinux docker-engine
2018.3官网版本
安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
设置stable镜像仓库
大坑
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
推荐
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
更新yum软件包索引
yum makecache fast
安装DOCKER CE
yum -y install docker-ce
启动docker
systemctl start docker
测试
docker version
docker run hello-world
配置镜像加速
mkdir -p /etc/docker
vim /etc/docker/daemon.json
systemctl daemon-reload
systemctl restart docker
卸载
systemctl stop docker
yum -y remove docker-ce
rm -rf /var/lib/docker
永远的HelloWorld
阿里云镜像加速
是什么
https://dev.aliyun.com/search.html
注册一个属于自己的阿里云账户(可复用淘宝账号)
获得加速器地址连接
登陆阿里云开发者平台
获取加速器地址
配置本机Docker运行镜像加速器
重新启动Docker后台服务:service docker restart
Linux 系统下配置完加速器需要检查是否生效
网易云加速
基本同上述阿里云
启动Docker后台容器(测试运行 hello-world)
docker run hello-world
run干了什么
底层原理
Docker是怎么工作的
为什么Docker比较比VM快
Docker常用命令
帮助命令
docker version
docker info
docker --help
镜像命令
docker images
列出本地主机上的镜像
OPTIONS说明:
-a :列出本地所有的镜像(含中间映像层)
-q :只显示镜像ID。
--digests :显示镜像的摘要信息
--no-trunc :显示完整的镜像信息
docker search 某个XXX镜像名字
网站
https://hub.docker.com
命令
docker search [OPTIONS] 镜像名字
OPTIONS说明:
--no-trunc : 显示完整的镜像描述
-s : 列出收藏数不小于指定值的镜像。
--automated : 只列出 automated build类型的镜像;
docker pull 某个XXX镜像名字
下载镜像
docker pull 镜像名字[:TAG]
docker rmi 某个XXX镜像名字ID
删除镜像
删除单个
docker rmi -f 镜像ID
删除多个
docker rmi -f 镜像名1:TAG 镜像名2:TAG
删除全部
docker rmi -f $(docker images -qa)
思考
结合我们Git的学习心得,大家猜猜是否会有
docker commit /docker push??
容器命令
有镜像才能创建容器,这是根本前提(下载一个CentOS镜像演示)
docker pull centos
新建并启动容器
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
OPTIONS说明
启动交互式容器
列出当前所有正在运行的容器
docker ps [OPTIONS]
OPTIONS说明
退出容器
两种退出方式
exit
容器停止退出
ctrl+P+Q
容器不停止退出
启动容器
docker start 容器ID或者容器名
重启容器
docker restart 容器ID或者容器名
停止容器
docker stop 容器ID或者容器名
强制停止容器
docker kill 容器ID或者容器名
删除已停止的容器
docker rm 容器ID
一次性删除多个容器
docker rm -f $(docker ps -a -q)
docker ps -a -q | xargs docker rm
重要
启动守护式容器
docker run -d 容器名
查看容器日志
docker logs -f -t --tail 容器ID
* -t 是加入时间戳
* -f 跟随最新的日志打印
* --tail 数字 显示最后多少条
查看容器内运行的进程
docker top 容器ID
查看容器内部细节
docker inspect 容器ID
进入正在运行的容器并以命令行交互
docker exec -it 容器ID bashShell
重新进入docker attach 容器ID
上述两个区别
attach 直接进入容器启动命令的终端,不会启动新的进程
exec 是在容器中打开新的终端,并且可以启动新的进程
从容器内拷贝文件到主机上
docker cp 容器ID:容器内路径 目的主机路径
小总结
常用命令
Docker 镜像
是什么
UnionFS(联合文件系统)
Docker镜像加载原理
分层的镜像
为什么 Docker 镜像要采用这种分层结构呢
特点
Docker镜像都是只读的
当容器启动时,一个新的可写层被加载到镜像的顶部。
这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
Docker镜像commit操作补充
docker commit提交容器副本使之成为一个新的镜像
docker commit -m=“提交的描述信息” -a=“作者” 容器ID 要创建的目标镜像名:[标签名]
案例演示
从Hub上下载tomcat镜像到本地并成功运行
docker run -it -p 8080:8080 tomcat
-p 主机端口:docker容器端口
-P 随机分配端口
i:交互
t:终端
故意删除上一步镜像生产tomcat容器的文档
也即当前的tomcat运行实例是一个没有文档内容的容器,
以它为模板commit一个没有doc的tomcat新镜像atguigu/tomcat02
启动我们的新镜像并和原来的对比
启动atguigu/tomcat02,它没有docs
新启动原来的tomcat,它有docs
Docker容器数据卷
是什么
一句话:有点类似我们Redis里面的rdb和aof文件
能干嘛
容器的持久化
容器间继承+共享数据
数据卷
容器内添加
直接命令添加
命令
docker run -it -v /宿主机绝对路径目录:/容器内目录 镜像名
查看数据卷是否挂载成功
容器和宿主机之间数据共享
容器停止退出后,主机修改后数据是否同步
命令(带权限)
docker run -it -v /宿主机绝对路径目录:/容器内目录:ro 镜像名
DockerFile添加
根目录下新建mydocker文件夹并进入
可在Dockerfile中使用VOLUME指令来给镜像添加一个或多个数据卷
File构建
build后生成镜像
获得一个新镜像zzyy/centos
run容器
通过上述步骤,容器内的卷目录地址已经知道
对应的主机目录地址哪??
主机对应默认地址
备注
数据卷容器
是什么
总体介绍
以上一步新建的镜像zzyy/centos为模板并运行容器dc01/dc02/dc03
它们已经具有容器卷
/dataVolumeContainer1
/dataVolumeContainer2
容器间传递共享(--volumes-from)
先启动一个父容器dc01
在dataVolumeContainer2新增内容
dc02/dc03继承自dc01
--volumes-from
命令
dc02/dc03分别在dataVolumeContainer2各自新增内容
回到dc01可以看到02/03各自添加的都能共享了
删除dc01,dc02修改后dc03可否访问
删除dc02后dc03可否访问
再进一步
新建dc04继承dc03后再删除dc03
结论:容器之间配置信息的传递,数据卷的生命周期一直持续到没有容器使用它为止
DockerFile解析
是什么
Dockerfile是用来构建Docker镜像的构建文件,是由一系列命令和参数构成的脚本。
构建三步骤
编写Dockerfile文件
docker build
docker run
文件什么样???
以我们熟悉的CentOS为例
https://hub.docker.com/_/centos/
DockerFile构建过程解析
Dockerfile内容基础知识
1:每条保留字指令都必须为大写字母且后面要跟随至少一个参数
2:指令按照从上到下,顺序执行
3:#表示注释
4:每条指令都会创建一个新的镜像层,并对镜像进行提交
Docker执行Dockerfile的大致流程
(1)docker从基础镜像运行一个容器
(2)执行一条指令并对容器作出修改
(3)执行类似docker commit的操作提交一个新的镜像层
(4)docker再基于刚提交的镜像运行一个新容器
(5)执行dockerfile中的下一条指令直到所有指令都执行完成
小总结
DockerFile体系结构(保留字指令)
FROM
基础镜像,当前新镜像是基于哪个镜像的
MAINTAINER
镜像维护者的姓名和邮箱地址
RUN
容器构建时需要运行的命令
EXPOSE
当前容器对外暴露出的端口
WORKDIR
指定在创建容器后,终端默认登陆的进来工作目录,一个落脚点
ENV
用来在构建镜像过程中设置环境变量
ADD
将宿主机目录下的文件拷贝进镜像且ADD命令会自动处理URL和解压tar压缩包
COPY
类似ADD,拷贝文件和目录到镜像中。
将从构建上下文目录中 的文件/目录复制到新的一层的镜像内的 位置
COPY src dest
COPY ["src", "dest"]
VOLUME
容器数据卷,用于数据保存和持久化工作
CMD
指定一个容器启动时要运行的命令
Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,CMD 会被 docker run 之后的参数替换
ENTRYPOINT
指定一个容器启动时要运行的命令
ENTRYPOINT 的目的和 CMD 一样,都是在指定容器启动程序及参数
ONBUILD
当构建一个被继承的Dockerfile时运行命令,父镜像在被子继承后父镜像的onbuild被触发
小总结
案例
Base镜像(scratch)
Docker Hub 中 99% 的镜像都是通过在 base 镜像中安装和配置需要的软件构建出来的
自定义镜像mycentos
编写
Hub默认CentOS镜像什么情况
准备编写DockerFile文件
myCentOS内容DockerFile
构建
docker build -t 新镜像名字:TAG .
运行
docker run -it 新镜像名字:TAG
列出镜像的变更历史
docker history 镜像名
CMD/ENTRYPOINT 镜像案例
都是指定一个容器启动时要运行的命令
CMD
Dockerfile 中可以有多个 CMD 指令,但只有最后一个生效,CMD 会被 docker run 之后的参数替换
Case
tomcat的讲解演示
docker run -it -p 8888:8080 tomcat ls -l
ENTRYPOINT
docker run 之后的参数会被当做参数传递给 ENTRYPOINT,之后形成新的命令组合
Case
制作CMD版可以查询IP信息的容器
crul命令解释
问题
如果我们希望显示 HTTP 头信息,就需要加上 -i 参数
WHY
制作ENTROYPOINT版查询IP信息的容器
自定义镜像Tomcat9
mkdir -p /zzyyuse/mydockerfile/tomcat9
在上述目录下touch c.txt
将jdk和tomcat安装的压缩包拷贝进上一步目录
apache-tomcat-9.0.8.tar.gz
jdk-8u171-linux-x64.tar.gz
在/zzyyuse/mydockerfile/tomcat9目录下新建Dockerfile文件
目录内容
构建
构建完成
run
备注
验证
结合前述的容器卷将测试的web服务test发布
总体概述
web.xml
a.jsp
热更新
https://blog.viakiba.cn/2020/03/30/java-hot-fix/
https://blog.viakiba.cn/2020/03/30/java-hot-fix/
数据修复
Groovy
代码修复
ClassFileTransInfo
Instrument
热修复 方法体
agent (java探针 性能监控等)
分布式场景
高并发解决方案
动态资源和静态资源分离
CDN
负载均衡
分布式缓存
数据库读写分离或数据切分
服务分布式部署
并发编程
事务概念
事务与锁
分布式事务产生背景
X/OpenDTP事务模型
标准分布式事务
分布式事务解决方案
两阶段提交
BASE理论与柔性事务
TCC方案
TCC-Transaction 分布式事务 —项目实战
项目文件
tcc执行过程
tcc-transaction-http-order :商城服务,提供商品和商品订单逻辑。
tcc-transaction-http-capital :资金服务,提供账户余额逻辑。
tcc-transaction-http-redpacket :红包服务,提供红包余额逻辑。
补偿性方案
异步确保型与最大努力型
单点登陆方案
单点登陆的问题背景
页面跨域问题
Session跨域共享方案
session的扩展
分布式任务调度方案
Quartz调度的用法
Elastic-Job示例
分布式调度的疑难点
Quartz集群定制化分布式调度
RabbitMQ
AMQP协议概念含义
AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现
消息队列主要有两种形式的目的地
1.队列(queue):点对点的消息通信(point-point)
2.主题(topic):发布(publish)/订阅(subscribe)通信
消息中间件的特点
1.采用异步处理模式
2.发送者和接收者不必了解对方,只需确认消息.发送者和接受者不必同时在线
3.消息中间件存储存储发送,接收消息,可以看做是一个容器
4.使用消息中间件的好处
中间件的使用场景
MQ的使用场景
RabbitMQ的几种典型使用场景
MQ应用场景
项目中使用rabbitmq的原因
承保系统送承保信息到收付系统,之后再送给费管系统
mq使用中的缺点
为什么要是用消息队列以及消息队列的优缺点分析
消息中间件的对比
Kafka、RabbitMQ、RocketMQ等消息中间件的介绍和对比
Kafka、RabbitMQ、RocketMQ等消息中间件的对比
rabbitMq基础使用
使用rabbitmq原因
开源、性能优秀,稳定性保障
提供可靠性消息的投递模式(confirm)、返回模式(return)
与springAMQP完美的整合、api丰富
集群模式非常丰富,表达式配置,HA模式,镜像队列模型
保证数据不丢失的前提是做到高可靠性、可用性
rabbitmq的概念特点
Virtual host:虚拟地址,用于逻辑隔离;一个Virtual host里可以有多个Exchange和Queue,同一个Virtual host不能有重名的Exchange和Queue;
rabbitmq组件详解
rabbitmq channel参数详解
三种Exchange模式
Exchanges Queues中互相跳转
Rabbitmq消息持久化
生产者或者消费者断线重连
ACK 确认机制
消息任务分发与消息ACK确认机制
RabbitMQ入门教程(十二):消息确认Ack
中间件的使用问题
如何保证消息队列的高可用
如何保证消息队列的高可用啊?
如何保证消息不被重复消费
RabbitMQ保证不消费重复数据
insert数据,给这个消息做唯一主键
做redis的set的操作
给消息分配一个全局id,将<id,message>以K-V形式写入redis
如何保证消息的可靠性传输
如何保证消费的可靠性传输
生产者丢数据
写消息的过程中,消息没有到达rabbitmq在网络传输过程中就丢了
confirm模式,重发
消息队列丢数据
rabbitmq接到消息后先暂存到自己的内存里,结果消费者还没来得及消费,rabbitmq挂掉了
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
消费者丢数据
消费者丢数据一般是因为采用了自动确认消息模式。至于解决方案,采用手动确认消息即可。
如何保证消息的顺序性
拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点
就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
几百万消息在消息队列里积压了几个小时
如何写一个消息队列架构设计
rabbitmq实战实例
rabbitmq HelloWorld实例
保单成本平台子任务
生产者
准备文件
车险保单.txt
车险批单.txt
配置文件policyBatches-message-producer.xml
policyBatches-message-producer.xml
PolicyBatchesMsgSenderImpl
PolicyBatchesMsgSenderImpl.java
TestPolicyBatchesSenderImpl
TestPolicyBatchesSenderImpl.java
消费者
配置文件policyBatches-message-consumer.xml
policyBatches-message-consumer.xml
PolicyBatchesMsgConsumerPolicyImpl
PolicyBatchesMsgConsumerPolicyImpl.java
PolicyBatchesMsgConsumerEndorImpl
PolicyBatchesMsgConsumerEndorImpl.java
TestPolicyBatchesConsumerImpl
TestPolicyBatchesConsumerImpl.java
spring boot中的rabbitMq配置
sprinboot集成rabbitmq教程
Spring Boot系列十三 Spring Boot集成RabbitMQ
Spring Boot系列十五 spring boot集成RabbitMQ 源码分析
RocketMQ
rocketmq学习教材
RocketMQ用户指南v3.2.4.pdf
rocketmq学习链接
rocketmq在windows、linux、docker的安装
Windows环境安装与配置RocketMQ
RocketMQ-Console安装、使用详解
springboot的RocketMq实例
Rocketmq - 1 介绍和核心概念
Rocketmq - 2 集群架构模型和部署结构图
Rocketmq - 3 部署双主环境
Rocketmq - 4 Broker配置文件,存储和HelloWorld
RocketMQ - 5 源码模块分析
RocketMQ - 6 生产者,顺序消息
RocketMQ - 8 消费者 push和pull模式,配置参数
rocketmq - 9 消息重试,消息幂等去重,消息模式
rocketmq - 10 双主双从模式
rocketmq队列
RocketMQ-延迟队列
RocketMQ-死信队列
RocketMQ-重试队列
rocketmq学习教程
黑马RocketMQ大纲
RocketMQ-01
RocketMQ-02
RocketMQ-03
rocketmq基本操作
rocketmq的优缺点
优点
1.解耦
2.削峰
3.数据分发
缺点
1.系统可用性降低
2.系统复杂度提高
重复消费
消息丢失
消息顺序
3.一致性问题
各个角色介绍
Producer:消息的发送者;举例:发信者
Consumer:消息接收者;举例:收信者
Broker:暂存和传输消息;举例:邮局
NameServer:管理Broker;举例:各个邮局的管理机构
Topic:区分消息的种类;一个发送者可以发送消息给一个或者多个Topic;一个消息的接收者可以订阅一个或者多个Topic消息
Message Queue:相当于是Topic的分区;用于并行发送和接收消息
双主双从集群搭建
消息生产发送
同步消息生产
异步消息生产
单向消息生产
负载均衡消费
广播模式消费
顺序消息模式
顺序消息生产
顺序消息消费
延时消息模式
延时消息生产
延时消息消费
发送批量消息
过滤消息模式
过滤消息生产
过滤消息消费
事务消息模式
事务消息生产
事务消息消费
rocketmq实战商城
业务分析
模拟电商网站购物场景中的【下单】和【支付】业务
下单业务(订单系统)
下单流程分析图
下单组件图.png
下单时序图.png
下单业务解决思路
失败补偿机制
校验订单
生成预订单
生成预订单.png
调用服务
扣减库存(库存服务)
扣减优惠券(优惠券服务)
扣减余额(用户服务)
确认订单
确认成功
确认失败
下单失败
发送订单确认失败MQ消息
回退库存
回退库存幂等性处理
数据库乐观锁
回退优惠券
回退余额
取消订单
支付业务
支付流程分析图
支付组件图.png
支付流程图.png
创建支付订单
创建支付订单.png
支付回调
支付后回调.png
rocketmq高级功能
消息的存储
mq消息生产消费流程
消息存储方式.png
消息生成者发送消息
MQ收到消息,将消息进行持久化,在存储中新增一条记录
返回ACK给生产者
MQ push 消息给对应的消费者,然后等待消费者返回ACK
如果消息消费者在指定时间内成功返回ack,那么MQ认为消息消费成功
MQ删除消息
性能对比
文件系统>关系型数据库DB
顺序写的过程,保证当前写的速度
消息存储结构
RocketMQ消息的存储是由ConsumeQueue和CommitLog配合完成 的
刷盘机制
RocketMQ的消息是存储到磁盘上的,这样既能保证断电后恢复, 又可以让存储的消息量超出内存的限制。
同步刷盘
异步刷盘
高可用机制
RocketMQ角色.jpg
rocketmq分布式集群
RocketMQ分布式集群是通过Master和Slave的配合达到高可用性的。
Master和Slave的区别
在Broker的配置文件中,参数 brokerId的值为0表明这个Broker是Master,大于0表明这个Broker是 Slave;
同时brokerRole参数也会说明这个Broker是Master还是Slave;
Master角色的Broker支持读和写,Slave角色的Broker仅支持读,也就是 Producer只能和Master角色的Broker连接写入消息;
Consumer可以连接 Master角色的Broker,也可以连接Slave角色的Broker来读取消息。
消息消费高可用
在Consumer的配置文件中,并不需要设置是从Master读还是从Slave 读
当Master不可用或者繁忙的时候,Consumer会被自动切换到从Slave 读。
当一个Master角色的机器出现故障后,Consumer仍然可以从Slave读取消息,不影响Consumer程序
消息发送高可用
消息发送高可用设计.jpg
Topic的多个Message Queue创建在多个Broker组上(相同Broker名称,不同 brokerId的机器组成一个Broker组)
当一个Broker组的Master不可 用后,其他组的Master仍然可用,Producer仍然可以发送消息
RocketMQ目前还不支持把Slave自动转成Master
如果机器资源不足, 需要把Slave转成Master,则要手动停止Slave角色的Broker,更改配置文 件,用新的配置文件启动Broker。
负载均衡机制
Producer负载均衡
producer负载均衡.png
Producer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。
由于queue可以散落在不同的broker,所以消息就发送到不同的broker下
Consumer负载均衡
集群模式
广播模式
失败消息重试
顺序消息失败的重试
消息队列 RocketMQ 会自动不断进行消息重试(每次间隔时间为 1 秒)
应用会出现消息消费被阻塞的情况
在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生
无序消息失败的重试
无序消息的重试只针对集群消费方式生效;
广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息。
死信队列处理
当一条消息初次消费失败,消息队列 RocketMQ 会自动进行消息重试;
达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息
消息队列 RocketMQ 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。
无法被消费的消息称为死信消息(Dead-Letter Message),存储死信消息的特殊队列称为死信队列(Dead-Letter Queue)。
死信特性
死信消息特性
不会再被消费者正常消费。
有效期与正常消息相同,均为 3 天,3 天后会被自动删除。因此,请在死信消息产生后的 3 天内及时处理
死信队列特性
一个死信队列对应一个 Group ID, 而不是对应单个消费者实例
如果一个 Group ID 未产生死信消息,消息队列 RocketMQ 不会为其创建相应的死信队列
一个死信队列包含了对应 Group ID 产生的所有死信消息,不论该消息属于哪个 Topic
死信处理
某些因素导致消费者无法正常消费该消息,需要排查可疑因素并解决问题
在消息队列 RocketMQ 控制台重新发送该消息,让消费者重新消费一次
消费幂等处理
消息队列 RocketMQ 消费者在接收到消息以后,有必要根据业务上的唯一 Key 对消息做幂等处理的必要性
消费幂等的必要性
发送时消息重复
服务端对客户端应答失败
投递时消息重复
客户端给服务端反馈应答的时候网络闪断
负载均衡时消息重复
消息队列 RocketMQ 的 Broker 或客户端重启、扩容或缩容
处理方式
真正安全的幂等处理,不建议以 Message ID 作为处理依据
最好的方式是以业务唯一标识作为幂等处理的关键依据
rocketmq解决问题
幂等性,RocketMQ解决消息顺序和重复
RocketMQ—顺序消息和重复消息
WebSocket的使用
websocket原理
看完让你彻底搞懂Websocket原理
使用 HTML5 WebSocket 构建实时 Web 应用
websocket实战
Springboot整合Websocket案例(后端向前端主动推送消息)
Java Websocket实例【项目实战系列】
fastdfs服务器
fastdfs服务器简介
fastdfs服务器作用
FastDFS是一个开源的轻量级分布式文件系统,主要是使用它对文件进行管理
主要用到的功能是:文件存储、文件同步、文件访问(文件上传、文件下载)等
fastdfs解决了大容量存储和负载均衡的需求问题
特别适合以文件为载体的在线服务,如相册网站、视频网站等
fastdfs服务器优势
FastDFS充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标
使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传、下载等服务
fastdfs服务器安装
docker安装fastdfs
docker+fastdfs+springboot一键式搭建分布式文件服务器
快速在docker里面FastDFS安装单机版+nginx
使用Docker一键搭建FastDFS+Nginx分布式文件服务器
拉取镜像并启动
docker run -d --restart=always --privileged=true --net=host --name=fastdfs -e IP=192.168.25.134 -e WEB_PORT=80 -v ${HOME}/fastdfs:/var/local/fdfs registry.cn-beijing.aliyuncs.com/tianzuo/fastdfs
测试是否安装成功
docker exec -it fastdfs /bin/bash
echo "Hello FastDFS!">index.html
fdfs_test /etc/fdfs/client.conf upload index.html
http://192.168.25.134/group1/M00/00/00/wKgZhl7psfaAckipAAAADwL5vO455.html
fastdfs服务器原理
FastDFS由跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)构成
Tracker server 追踪服务器
追踪服务器负责接收客户端的请求,选择合适的组合storage server
tracker server 与 storage server之间也会用心跳机制来检测对方是否活着
Tracker需要管理的信息也都放在内存中,并且里面所有的Tracker都是对等的(每个节点地位相等),很容易扩展
客户端访问集群的时候会随机分配一个Tracker来和客户端交互
Storage server 储存服务器
实际存储数据,分成若干个组(group),实际上traker就是管理的storage中的组
组内机器中则存储数据,group可以隔离不同应用的数据,不同的应用的数据放在不同group里面
优点
海量的存储:主从型分布式存储,存储空间方便拓展
fastDFS对文件内容做hash处理,避免出现重复文件
fastDFS结合Nginx集成, 提供网站效率
客户端应用Client服务器
本地的项目所部署在的服务器
fastdfs上传下载文件流程
fastdfs上传文件流程
fastdfs上传文件流程.png
写操作的时候,storage会将他所挂载的所有数据存储目录的底下都创建2级子目录,每一级256个总共65536个
新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据作为本地文件存储到该目录中
fastdfs下载文件流程
fastdfs下载文件流程.png
当客户端向Tracker发起下载请求时,并不会直接下载,而是先查询storage server(检测同步状态),返回storage server的ip和端口
然后客户端会带着文件信息(组名,路径,文件名),去访问相关的storage,下载文件
fastdfs服务器实践
微服务粒度划分
单体设计优先
Yagni (You aren't gonna need it)
设计刚刚好的系统
过犹不及
过度设计
敏捷
系统边界识别
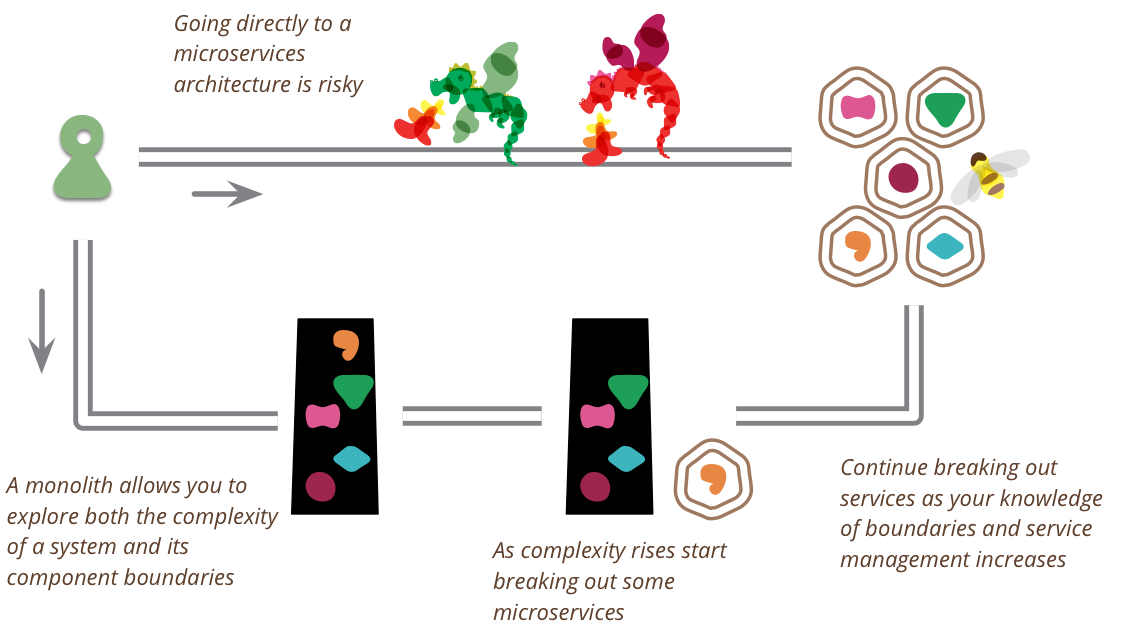
在微服务中重构比在单体应用中重构成本高多了
在单体应用中,随着用户的反馈,系统的维护 有利于识别良好的、稳定的系统边界
几种演进方式
良好架构单体应用优先
单体应用组件分离微服务
粗粒度服务,之后再拆分
微服务技术栈的管理
不限死使用的语言和框架, 但是也不允许完全的灵活性
语言和框架
前端
Vuejs
AngularJS
后端
nodejs
typescript
hapi
ruby
grape
java
jersery
spring boot
微服务化的一个好处 :smiley: 就是: 根据工作的不同来选用合理的工具
划分微服务的注意事项
领域驱动的划分
按照业务来组织工作
如何划分微服务?
按照领域模型划分
新项目不建议直接使用微服务
你很可能并不真的理解业务领域, 从而也很难理解各个服务的边界
不能为了微服务而微服务,微服务本身也是有成本的, 如果成本大于收益,得不偿失
微服务架构提倡通过对特定业务领域的分析与建模,将复杂的、 集中的、耦合度高的应用系统分解成**小而专、耦合度低并且高度自治**的一组服务
微服务的“微”并不是一个真正可衡量、看得见、摸得着的“微”。这个“微”所表达的,是一种设计思想和指导方针,是需要团队或者组织共同努力找到的一个平衡点
:!!: **业务独立性**和**团队自主性**。首先,应该保证微服务是具有业务独立性的单元,在这个前提下,由团队来判断当前的服务大小是否合适,考虑到团队的沟通成本,一般不建议超过10个人,或者在超过10个人的团队中,可以再划分子团队。在这种情况下,当团队中大部分成员认为当前的服务是能够容易维护的、容易理解的,这就是我们认为适合团队的、有意义的“微”。
演进式设计
微服务可能出现来回往复的拆分和合并,知道开发人员真正理解了服务的边界应该是什么
根据业务的实际情况作调整, 而不是守着架构一成不变
大多数软件架构的腐化都发生在维护期, 微服务也不是银弹,无法解决这个问题, 因此长期维护的项目架构必须演进 :recycle:
颗粒度控制在什么程度?
职责的单一性
而不是代码的多少
我们的疑问?
需求大小?
代码?
职责?

收集的资料
http://wldandan.github.io/blog/categories/microservices/
https://martinfowler.com/microservices/
http://insights.thoughtworkers.org/evolutionary-architecture-micro-services/
https://martinfowler.com/bliki/MonolithFirst.html
http://www.jiagoushuo.com/article/1000532.html
https://coggle.it/diagram/WPRq45VczAABUIGl/t/%E5%BE%AE%E6%9C%8D%E5%8A%A1%E7%B2%92%E5%BA%A6%E5%88%92%E5%88%86
压力测试
Jmeter
Ngrinder
LoadRunne
团队协作
Java构建
Maven
Gradle
Ant
CI / CD
Jenkins
Travis CI
GitLab CI
Spinnaker (部署)
版本控制
Git
git文件上传下载gitHub
两种方法上传本地文件到github
Git GUI上传修改的文件
Git Gui建库、克隆、上传、下载、合并
git实操步骤与解决问题
git更新代码
git pull
git更新步骤
解决fatal: refusing to merge unrelated histories
fatal: 'origin' does not appear to be a git repository
. git 中 rebase 和 merge 有什么区别
merge 会把公共分支和你当前的 commit 合并在一起,形成一个新的 commit 提交
rebase 会把你当前分支的 commit 放到公共分支的最后面,所以叫变基。就好像你从公共分支又重新拉出来这个分支一样。
eg: 如果你从 master 拉了个 feature 分支出来,然后你提交了几个 commit ,这个时候刚好有人把他开发的东西合并到 master 了,这个时候 master 就比你拉分支的时候多了几个 commit ,如果这个时候你 rebase develop 的话,就会把你当前的几个 commit,放到那个人 commit 的后面。
尽量不要在公共分支使用 rebase
本地和远端对应同一条分支,优先使用 rebase ,而不是 merge
比如 rebase,你自己开发分支一直在做,然后某一天,你想把主线的修改合到你的分支上,做一次集成,这种情况就用 rebase 比较好.把你的提交都放在主线修改的头上
如果用 merge,脑袋上顶着一笔 merge 的8,你如果想回退你分支上的某个提交就很麻烦,还有一个重要的问题, rebase 的话,本来我的分支是从3拉出来的, rebase 完了之后,就不知道我当时是从哪儿拉出来的我的开发分支
同样的,如果你在主分支上用 rebase , rebase 其他分支的修改,是不是要是别人想看主分支上有什么历史,他看到的就不是完整的历史课,这个历史已经被你篡改了
rebase 会把你当前分支的 commit 放到公共分支的最后面,所以叫变基。就好像你从公共分支又重新拉出来这个分支一样。
eg: 如果你从 master 拉了个 feature 分支出来,然后你提交了几个 commit ,这个时候刚好有人把他开发的东西合并到 master 了,这个时候 master 就比你拉分支的时候多了几个 commit ,如果这个时候你 rebase develop 的话,就会把你当前的几个 commit,放到那个人 commit 的后面。
尽量不要在公共分支使用 rebase
本地和远端对应同一条分支,优先使用 rebase ,而不是 merge
比如 rebase,你自己开发分支一直在做,然后某一天,你想把主线的修改合到你的分支上,做一次集成,这种情况就用 rebase 比较好.把你的提交都放在主线修改的头上
如果用 merge,脑袋上顶着一笔 merge 的8,你如果想回退你分支上的某个提交就很麻烦,还有一个重要的问题, rebase 的话,本来我的分支是从3拉出来的, rebase 完了之后,就不知道我当时是从哪儿拉出来的我的开发分支
同样的,如果你在主分支上用 rebase , rebase 其他分支的修改,是不是要是别人想看主分支上有什么历史,他看到的就不是完整的历史课,这个历史已经被你篡改了
gitLab的建立
Centos7 搭建Gitlab服务器并配置
Centos 7搭建Gitlab服务器超详细
基于Docker搭建GitLab
CentOS 7下基于Docker搭建GitLab服务器
缺少 sudo docker pull gitlab/gitlab-ce:latest
Svn
项目管理
Worktile
Trello
Redmine
Jira
原型设计
Sketch
axrue
墨刀
摹客
xiaopiu
文档管理
confluence
通过Docker安装JIRA和Confluence
Sphinx
xwiki
Redmine知识库插件
日志汇集
sentry
Spring Boot实战之配置使用Sentry上报错误日志(二)
CentOS7环境下通过Docker安装sentry
13-1 sentry的介绍和通过docker搭建sentry
多语言业务错误日志收集监控工具Sentry 安装与使用
Sentry通过Docker私有化部署
ELK
elasticSearch
ElasticSearch基础操作及ElasticsearchTemplate API
spring-data-ES 完整版+kibana管理ES的index操作
代码规范
阿里项目代码规范
阿里巴巴Java开发手册 1.4.0.pdf
数据库表使用规范
mysql数据库开发规范
MYSQL开发规范v1.0.2.doc
MYSQL开发基本规范(涉及分区表).doc
API管理
springfox-swagger2
SpringMVC集成springfox-swagger2构建restful API
安全
RSA
签名/验签
https://blog.viakiba.cn/2018/09/14/%E8%AF%81%E4%B9%A6%E9%93%BE%E6%A0%A1%E9%AA%8C%E4%B8%8E%E8%AF%81%E4%B9%A6%E5%90%88%E5%B9%B6/
证书
https://blog.viakiba.cn/2018/08/18/%E7%A7%81%E6%9C%89%E8%AF%81%E4%B9%A6%E7%AE%A1%E7%90%86/
https://blog.viakiba.cn/2018/09/08/Java-HTTPS-%E8%87%AA%E7%AD%BE%E8%AF%81%E4%B9%A6%E8%AE%BF%E9%97%AE/
https://gist.github.com/viakiba/4d9227537b9834dc8ac0eef58bd0325b
AES
DES
3DES
aes
摘要
Hmac
Md5
Sha1
Sha256
JSON web E/S/T
JWE
JWT
JWS
字节转换



0 条评论
下一页











