Kafka--架构维度
2023-01-12 11:23:44 0 举报Kafka--架构维度、原理
作者其他创作
大纲/内容
partition 0 leader
partition分区
metadata.update(cluster
B
indexoffset: 54 position: 4158
ISR的数量可以设置,如果设置了2个,那么ISR中有两个broker同步成功了,就会返回成功
启动命令
2
kafka - broker jvm
第一轮循环的时候,做了连接
consumer拉取的方式取数据粒度(批次)
topic
while(running)loop
因为只有2个分区,如果用3个consumer去消费,将有一个consumer被空置
inFlightRequestsMAX_IN_FLIGHT_REQUESTS_PER_CONNECTION 5设置每次连接没有返回请求的最大数值发送了 5 次 ,kafka 都没有返回,那么不再sender
副本
IO是双向的IO 框架 Netty
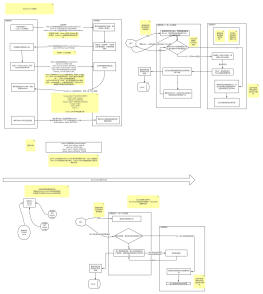
producer只跟分区的leader进行数据写入,各个分区的leader会向该分区的follower进行数据同步,consumer也是只跟分区的leader进行数据读取。
C
4
隔离开防止 饿死现象reponse的队列与连接处理器一一对应
LogEndOffsetLEO
consumer 1
memory metadata
broker-2jvm
Z区域分割
broker 2
Kafka的partition的消息
1datatime
实验1:ack:0
P0分区是物理的
msg3
sendInternalMetadataRequest()
metadatabtp
RecordAccumulator BUFFER_MEMORY_CONFIG
P0
consumer批次拉取数据后,多线程处理时遇到的问题:A数据和B数据分别在自己的线程中,维护谁的offset
NetworkClientnioSelector
producer 1
丢A1
KAFKA消息的处理方式
重复B1
Driver
B1
group3消费的区域
1
partition-X
A1A2
A
2,通知要拉取数据的offset
网卡
producer
partition 0 follower
分区内的数据是有序的但需要注意逻辑代码
topic : kafka自己创建的topic用来维护offset默认50个分区partition
45
5
起始ISR
P1
对生产者无任何影响
3.kafka通知kernel数据的offset
APP-T1
zk
consumer 2
生产者线程producer.send(msg);
consumer
数据填充
大数据必然的分治: 数据间无关联聚合: 数据间有关联
新版本可以维护到自身的topic中,后持久化逻辑层
批次的头或尾的绝对更新依赖了事务的反馈不会有重复消费,丢失数据的问题
redis
Y垂直拆分功能拆分
X水平扩展
spark中,批次
admin-api
在ack(-1)分布式的机制下一致性 :1,强一致性,所有节点必须全部存活,一致性破坏可用性2,最终一致性,[网络到分布式], (kafka的方案)2-1,font color=\"#ff3333\
producer以生产时间为主
目标地址是node03的,指向其他位置127.0.0.1
响应式
log 文件 字节数组 position记录的是字节数组的位置
RDD
取消了,不从zk总获取集群元数据信息,改为从kafka主节点获取
Group组1
ES
pagecache
wakeup()
MQ
Consumer Group 1
D
node03
实际运行是在内存中处理
IOthread:Sender
3
创建topic
200
broker2
连接处理器 2 一个线程
p1leader
p1follower
partition-1follower
ACK 为 -1的时候ISR里的多个broker的消息进度是一致
pagecache(4k大小)1
position
broker1
response : 队列 2
在consumer消费的时候1,丢失2,重复围绕的是offset 也就是消费的进度节奏?频率?先后?1,异步的,5秒之内,先写业务,再持久化offset:容易重复消费2,同步的,业务的操作和offset的持久化3,先offset持久了,但是业务写失败了,丢失数据了
offset 维护&持久化OOXX:P0:3?topic ooxx的p0分区offset为3
broker3
数据库
data
topic: xxoo1
生产是生产
老版本中
runtime内存里维护了自己的offset(偏移量的进度)内存中~!
db
partition:consumer1:1N:11:N 绝对不行
listen accept()
服务端如何更好的接受管理这么多的连接以及完成 请求和响应的正确匹配
打包的过程1M
broker
batch
kafka的broker的partition保存了 producer发送来的数据重点是“数据”怎么去用,可以重复利用在单一的使用场景下,即便追求性能,用多个consumer,应注意,不能一个分区由多个consumer消费。几个分区对应最多对应几个consumer,超过partition数量的consumer没有数据传输浪费资源数据的重复利用是站在Group上的,但是group内要保障上述描述
read (事件,以停止select)
group1
maybeUpdate
ISR所有收到5数据的分区,都是ISR
P
consumer-1
partition 0(follower)follower只备份leader的内容,只有在leader挂掉后controller将重选leader,只有follower变为leader才可以操作
多线程无法保证发送数据的有序性
不允许的
完成 请求和响应的正确匹配
P0备副本
Trade off思路决定出路
所有的消费组消费的区域一致
offset
socket
强制获取元数据强制发送数据wakeup()
app消费者
p1
group-x有3个分区,最多3个consumer消费,在增加consumer无意义
解决办法
主机事务成功之后,挡掉了,数据库需要幂等主机可能对offset更新出现网络问题,因此需有重试、兜底的offset
批次
磁盘文件方式保存数据
msg大小 < batch设置的大小一个batch可以放多个msgmsg大小 > batch设置的大小会单独开辟一个大batch存放msg,最后快速回收掉尽量不要msg大于batch的大小,以保证池化机制,调整 Buffer_memory_config是为了尽量触发批次发送,减少内存碎片,降低系统复杂度。
consumer 0
p0
无关的数据就分散到不同的分区里,以追求并发并行有关的数据,一定要按原有顺序发送的同一个分区里
initiateConnect(node)
consumer 1
拉取v.s推送 1,推送:是server主动去推送,网卡打满。。。2,拉取:consumer自主、按需、去订阅拉取server的数据
读取212的offset
kafka-broker1
group 2 消费的区域
磁盘,持久层
单机管理主 从集群
1,单线程,按顺序、单条处理,offset就是递增的,无论对db,offset频率高,导致CPU,网卡,资源浪费 进度控制,精度高2,流式的多线程,能多线程的多线程,最终将整个批次的事务环节交给一个线程,做到这个批次,要么成功,要么失败,减少对DB的压力,和offset频率压力,更多的去利用CPU,网卡硬件资源,粒度粗通过redis获取数据只是为了完善每一条记录的内容,比如:完善下商品的地址信息
接收消息后的ISR
http短连接(一次input)长连接(重复input)io框架是否可以重复input
broker 1jvm进程、相当于一台机器
msg2
write
topic 业务(主题/一个消息队列)
Kafka副本是要出主机的,走网络的可以有读写分离,容易出现一致性问题只在leader的P上进行W/R,再同步到副本
node04
consumer只能消费集群中HW位置的消息
node02
单次请求 同步阻塞请求的数据体比较大
消费是消费
partition-0follower
broker 3
java中:传统的io oioio.flush 是个空实现,没有物理刷盘,还是依赖内核的dirty刷盘,所以,会丢东西
partition 0 (leader)
interceptors.onSend(record);拦截器
为了解耦
6
sender
1.要拉取数据
第三方redismysql
timestamp: 1610627900905 offset: 54
一个线程不关注顺序可以使用多线程处理
P-0
data(链表)
RECEIVE_BUFFER_CONFIG
理论--分布式
更新metadata:
1,单线程:按条处理来更新offset,可保证数据不丢失不重复,但是速度比较慢,浪费硬件资源2,多线程:offset的维护按条,还是按批?如果每个线程按照单线程的方式处理,都会出现问题。多线程解决方案:流式计算,充分利用线程 (该并行的地方并行,该统一的地放统一起来)
p0leader
NetworkClient
数据库事务
只有ACK 为 -1的时候ISR里的多个broker的消息进度才会保持一致
MQ异步削峰填谷解耦可靠性有不同的要求
Group组2
poll()
node01
逻辑层
线程2如果维护B的offset,B1成功,A1,A2失败了回滚offset记录到B1位置A1丢失
ack0
那啥.log 不用mmap?通用知识点:mmap 或者 普通iolog 使用普通 io 的形式目的是通用性数据存入磁盘的可靠性级别app 层级 A、调用了io的write,但是这个时候只到达了内核,性能快,但是丢数据B、只有NIO的filechannel,你调用了write()+force(),才真的写到磁盘,性能极低的向磁盘写数据两种方式1,每条都force2,只是write 基于内核刷写机制,靠脏页
有了timestamp的索引,consumer可以按时间拉取
A的有序性,怎么保证?单独一个producer处理可以保证,如果多个producer同时进入一个partition中无法保证
数组: 大小固定 空间上是连续 计算方式找到偏移链表: 不固定 空间上不连续 遍历复杂度 建立索引
Low WatermarkLW
brokerskafka集群
P1备副本
Pconsumer
分区
kafka
所以jdk中通过RandomAccessFile
不是绝对定位
spark消费kafka
kafka-broker2
Broker
生产者ack0
事务
为什么要用多线程可以减少事务减少对数据库的压力
线程1如果维护A的offset,B1成功,A1、A2失败回滚,以A的offset重新拉取数据B1重复了在入库
poll-->nioSelector.select()
分区内部是有序分区外部无序offset
新老版本之间
0,不要强调单机磁盘的可靠性,应该转向异地多机的同步1,如果拿磁盘做持久化,优先pagecache或者绝对磁盘2,在多机集群分布式的时候,做tradeoff:强一致,最终一致性(过半,ISR)*:redis,宁可用HA,不用刻意追求AOF准确性像kafka,我们追求ack -1,不要太追求磁盘的可靠性还有trade off ,就是在HA场景下,如果有实例异常退出,是否需要立刻尝试重启(有可能导致不停的同步数据,导致主节点的资源被拖垮)
kafka-consumer-groups.sh可以查看group消费的情况
生产者ack1
seek
OSR5的数据没有同步到该partition,所以该分区将被变为OSR
ack01-1
group2 开始也是磁盘io读取,创建pagecache,然后交给consumer的group2组
response : 队列 1
Serializer序列化
单机到分布式分布式中间件
topic是逻辑的
实验3:ack:-1
Consumer Group 0
单线程:事务方式处理,逐条处理
High WatermarkHW衡量所有broker同步位置
连接处理器 1 一个线程
ack -1:分布式 备机的同步完成才成功 最严苛 所有的副本都要同步一致
topic ooxx
partition 0(leader)producer只对leader分区添加数据
磁盘
java NIO select()
ack: 0 :producer消息发出去后就算成功 1 :消息要持久化才成功(默认值)-1: 分布式 备机的同步完成才成功
group 1
KAFKA存储层(全量历史),弹性特殊场景:基于队列,反复的查阅使用,推送、趋向于稳定要么用redis要么用kafka支持时间戳==================Kafka默认会裁剪历史数据,所以会有LW(Low Watermark)
零拷贝,pagecache中有的话直接拉取
lock{ sql操作producer->kafka}unlock分布式锁,为了保证数据顺序要在锁里传递
ISR的变化
consumer能消费的就是producer生产的
data的索引indexoffset
AKF
p0follower
当group1消费到跟group2重叠的区域时,可直接从group2已经创建的pagecache中拉取,无需再交互磁盘
group 2
组与组之间是绝对隔离的
1连接处理器的id
4,如果offset直接命中pagecache直接取走,如果没有命中就根据offset从磁盘构建pagecache内容,然后给sendfile提供给consumer,不再经过broker,这就是零拷贝
ack1
producer 0
handler......
Partition 的 Leader主节点消息数据流程
partition-1leader
KafkaProducer线程安全
kernel
consumer 2
group1刚开始消费的时候会从磁盘走io到pagecache中,然后交给consumer的group1组
kafka对数据只是发送,没有加工的过程!
broker-1 (一个kafka进程)jvm
producertopicps
分布式 分区可靠性 要解决一个问题,伴随着引入更多的问题
处理计算单线程 or 线程池的
handleCompletedReceives()
partition-0leader
在业务层次上分布式 角色之间进行通信不要因为业务需求 让ZK集群成为负担在并发下,注意一致性的问题
写磁盘的粒度越小速度越慢trade off把单机的持久化可靠性转向集群多机方式
生产者会阻塞
ISR最初的时候都是ISR。但是同步数据时不成功,导致分区变成了OSR
controller控制哪个partition为leader
生产者
ack为1 (默认值)消息要持久化才成功(备区不一定成功)只关注producer和leader partition的通信
poll
ZK只负责分布式协调不是存储不要有业务操作,防止网卡打满导致分布式协调出现延迟等问题
时间
sendfile零拷贝
consumer以什么粒度更新&持久化offset
实验2:ack:1
group 1 消费的区域
controller主从中的主leader
1.更新元数据
KAFKA零拷贝
record
select(time)多路复用器
os提供了seek方法
zk元数据
生产者线程
1,索引;2,生产者,数据可靠性;3,时间戳,自定义消费数据-->本质:seek验证ACK的值在副本网路不同的情况下对生产者的影响,如何时间戳消费
topic :ooxx
LINGER_MS_CONFIG 0 1,阻塞生产一条,发送一条。batch可能不满2,非阻塞LINGER_MS_CONFIG 30batch会等30ms或者batch直接填满即发送,牵扯生产和io速度不对称
什么情况下多线程的优势发挥到极致?线程间数据具备隔离性时
为什么kafka快: 1.利用 Partition 实现并行处理2. 顺序写磁盘3. 充分利用 Page Cache4. 零拷贝技术5. 批处理在很多情况下,系统的瓶颈不是 CPU 或磁盘,而是网络IO。因此,除了操作系统提供的低级批处理之外,Kafka 的客户端和 broker 还会在通过网络发送数据之前,在一个批处理中累积多条记录 (包括读和写)。记录的批处理分摊了网络往返的开销,使用了更大的数据包从而提高了带宽利用率。6. 数据压缩Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
追求性能
zookeeper
DB
接收消息后的OSR
2.如何sender使用java的nio发送
RecordAccumulator
msg1
多线程解决方案:1,类似大数据,比如spark2,流式计算编程
SEND_BUFFER_CONFIG
request:队列
kafka-broker0controller
MAX_REQUEST_SIZE_CONFIG1M请求中batch的集合大小
metadata主节点会收集集群中的所有的元数据brokertopicpartition
第二轮循环,发送metadata请求
需求:顺序性1,前置 socket里存在顺序性,由发送方维护2,推送方,在架构上整体设计约束的
通信的有无状态警示:通信:客户端带着请求ID,且服务端响应请求的ID ,有状态节点间通信的机制上图中,和通信状态无关,它只是服务进程内部的线程间数据传递过程的对应关系
indextimestamp
生产者获取元数据(集群信息)更新元数据
5,提供数据




0 条评论
下一页









